Liwei Lin
Liwei Lin
@keepsimplefocus 确实是这样。1 ReceiverInputDStream ←→ 1 Receiver ←→ 1 分发 RDD(partition 数为 1)。 如果想要分发 n 个 Receiver, 只要把 n 个 ReceiverInputDStream 给 union 到一起就好了:`ssc.union(Seq[ReceiverInputDStream])`,就像在 Spark Core 模块里 union 多个 RDD 一样。
@luphappy 已在 [Issue#1](https://github.com/lw-lin/CoolplaySpark/issues/1) 里回复了
@cjuexuan 在 [Streaming 官方的 Programming Guide](http://spark.apache.org/docs/latest/streaming-programming-guide.html) 里,有下面的图示: 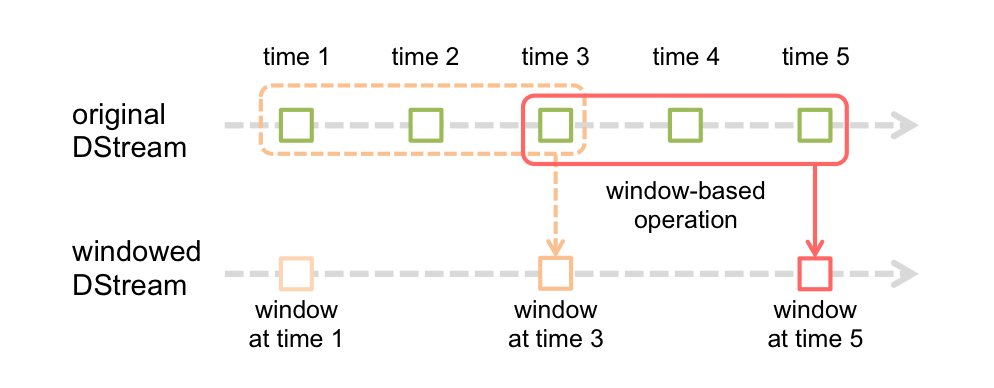 上图里 batch duration = 1, window length = 3, sliding interval = 2 任何情况下 Job Submit 是以 batch duration 为准,但本 batch 里不一定生成...
@luckuan 的解释更详细一些。对图中的 originalDStream,每个 batch 都生成了 RDD,对 windowedDStream,每隔 sliding interval 才去实际生成 RDD,而不是每个 batch 都生成 RDD。
@pzz2011 如果你是指 Google Dataflow 对 Window 的定义(如下图)的话,那么 Spark Streaming 支持 Fixed 和 Sliding,原生并不支持 Sessions。  另一方面可以参考 [Cloudera 的 Spark-Dataflow](https://github.com/cloudera/spark-dataflow),可能基于 Spark Streaming 提供了 Sessions 支持,我不是特别清楚。
@pzz2011 前两种就是通常意义下的 window;一般大家常见到的 window 操作都适合于这两种场景。另外实际上 Fixed 只是 Sliding 的一种特殊情况。 Watermark 的概念主要还是看 WheelMill 吧,DataFlow 以 WheelMill 为流引擎,DataFlow 的 watermark 是来自 WheelMill 的。WheelMill 的论文来自 VLDB 2013。 交易所的对实时性要求高的计算(高频交易等)都是针对特定业务的专有系统来支持的。这类系统专业、稳定、非常非常实时,但是不会具有通用性。现有流数据平台无法很好的支持交易所的需求。我还没听说过交易所也用 Batch 处理(如 MR、Spark 等)的,他们应该也是有专用系统。
@sumpan 最近不太有时间写 StreamingContext 详解了,不过有了前面系列文章的基础,StreamingContext 本身反而是最简单的部分了,所以推荐直接看源代码。感谢关注!
@zhengzhou-spark @JudeLmin ``` // 完整代码可见本文最后的附录 ``` 代码已经更新到原文附录,thanks!
@AntikaSmith 确实之前的表述有问题,也确实是 `没有lazy,那么它应该是在streamingContext初始化的时候就生成了吧` 这样的。I'm fixing it -- thanks for pointing this out! 另外如果没加 Streaming 交流群的话,请加下? 
Sure. Currently in the Parquet read path, only the data of columns from requested_schema ∩ file_schema are fetched from the storage, not the data from columns specified only in predicates....