CoolplaySpark
 CoolplaySpark copied to clipboard
CoolplaySpark copied to clipboard
《1.2 DStream 生成 RDD 实例详解.md》讨论区
这里是 《1.2 DStream 生成 RDD 实例详解.md》 讨论区。
如需要贴代码,请复制以下内容并修改:
public static final thisIsJavaCode;
val thisIsScalaCode
谢谢!
”每个新 batch 生成时,都会调用 DStreamGraph.generateJobs(time),也进而出发我们之前讨论这个 Job 生成过程,周而复始。“有错别字“出发”,应该是“触发”
Update: 上述内容已改正,thanks!
@lw-lin 请问Spark Streaming为了避免重复计算,对DStream做一次cache以后,为什么性能下降很厉害?在使用cache操作的时候有什么地方需要注意吗?
@tsface 主要看下 cache 的内存占用情况。如果一个 partition 被 cache() 后由于内存压力又 drop 掉了,那么需要使用的时候就会再次计算,反而比之前多了许多计算量。如果内存压力大,可以试下 persist(MEMORY_AND_DISK_SER)。 另外,Spark 的版本是?1.6 与 1.5 相比,内存管理上有些差别。
这个我已经提 PR 了,貌似还没有 merge
2016-07-04 15:15 GMT+08:00 Xingjun Wang [email protected]:
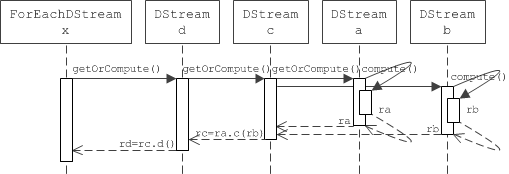
后面几行也是如此,所以我们如果用 DStream DAG 图来表示之前那段 quick example 的话,就是这个样子:
这儿有一个图没有,应该是md写错了?.png,不是.jpg?
— You are receiving this because you were mentioned. Reply to this email directly, view it on GitHub https://github.com/lw-lin/CoolplaySpark/issues/3#issuecomment-230221285, or mute the thread https://github.com/notifications/unsubscribe/ABXA1-8zQ7uhIv9rluUmOlFxOeEFKN65ks5qSLL7gaJpZM4GvavE .
Blog:http://www.klion26.com GTalk:qcx978132955 一切随心
关于ForEachDStream 的 compute(time) 实现部分, 该子类的 compute(time) 实现是 None. 所以下面的 所以在 compute(time) 的具体实现里,就很简单了: 这部分是不是要做下说明, 并改为解释 generateJob(time) 为何要覆盖基类中的方法.
如@runitao所说,ForEachDStream的compute实现是None,是因为这是最后一个DStream,不会有其他的DStream依赖于他,所以没有compute RDD的必要了吧
spark streaming的job会涉及到DAGScheduler吗? 似乎 没有看到job的stage是如何划分的, job直接扔到线程池去执行了.
如果理解没有问题的话。spark streaming 执行的是 job,job 执行会调用到 dagscheduler,由 dagscheduler 划分 stage
2018年2月25日星期日,Ryan Tao [email protected] 写道:
spark streaming的job会涉及到DAGScheduler吗? 似乎 没有看到job的stage是如何划分的, job直接扔到线程池去执行了.
— You are receiving this because you were mentioned. Reply to this email directly, view it on GitHub https://github.com/lw-lin/CoolplaySpark/issues/3#issuecomment-368307586, or mute the thread https://github.com/notifications/unsubscribe-auth/ABXA1xDpflwCnR_qg3GfYKyJMyzzUHTMks5tYVnpgaJpZM4GvavE .
-- Blog:http://www.klion26.com GTalk:qcx978132955 一切随心