Some questions about preprocessing normalization
1、In the configuration file gta5_stm.yml mean: [0.0, 0.0, 0.0] std: [1., 1., 1.]. In gta5_maps_pla.yml and gta5_st.yml, it is mean: [0.485, 0.456, 0.406], std: [0.229, 0.224, 0.225] Why are the normalized values set different? As far as I know, the impact of different normalization on the model is fatal. For example, use mean: [0.0, 0.0, 0.0],std: [1., 1., 1.] loading the dataset and your pretrained weights model is very poor. 2、The normalized mean used during self-training: [0.485, 0.456, 0.406], std: [0.229, 0.224, 0.225] is better than mean: [0.0, 0.0, 0.0] std: [1., 1 ., 1.]? 3、 Can you provide the training code to get the warmup weights, I want to try the training effect under the normalization setting of mean: [0.0, 0.0, 0.0] std: [1., 1., 1.] I really hope and thank you for answering the above questions, and look forward to your training code in the third point.
1&2. "gta5_stm.yml" use the model pre-trained by simclrv2 (the r152_1x_sk1.pth parameters) to extract features, so the normalization value should be "mean: [0.0, 0.0, 0.0] std: [1., 1., 1.]", which is consistent with the pre-training stage of the simclr model.
Other models require training, so I think using either type of normalized has little effect on the results.
3.For warmup, you can simply modify the gta5_st.yml as follows:
...
#labelpath: gta5_maps_workdir/pseudo_labels
...
loss_target_seg: False # True
sce_loss_target: False # True
loss_consist: False # True
...
But we find that the warmup stage based on Global Photometric Alignment is unstable, so we provide the warmup model we use in the experiments.
Did you use the reweight_map in your article when training warmup (baseline)?
Sorry to bother you, I changed the source domain self-training settings you mentioned above, and set use_reweight_map to False, and the results are as follows:
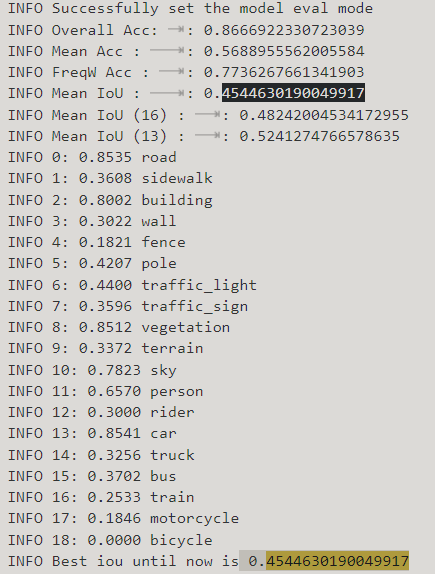 The score of bicycle is 0. I wonder if it is related to not using use_reweight_map?
The score of bicycle is 0. I wonder if it is related to not using use_reweight_map?
Sorry to bother you, I changed the source domain self-training settings you mentioned above, and set use_reweight_map to False, and the results are as follows:
This is not normal. Cloud you share me the log, yaml file and the pytorch version? Use reweight_map may alleviate this, but not adding this should not result in a bike with a mIoU of 0.
Did you use the reweight_map in your article when training warmup (baseline)?
The baseline didn't use reweight_map.
run_2023_02_17_20_37_43.log
gta5_st_yaml.txt
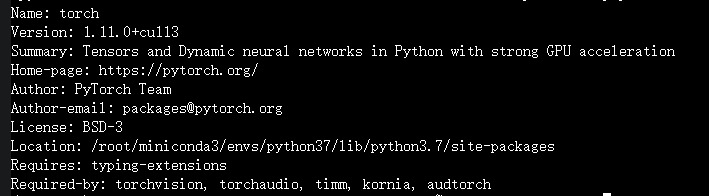 The log, yaml, and pytorch version information are as above. I modified the normalized value in yaml. As you said, it has no effect. I also performed mean: [0.485, 0.456, 0.406]
std: [0.229, 0.224, 0.225] experiment, bicycle is still 0.
The log, yaml, and pytorch version information are as above. I modified the normalized value in yaml. As you said, it has no effect. I also performed mean: [0.485, 0.456, 0.406]
std: [0.229, 0.224, 0.225] experiment, bicycle is still 0.
run_2023_02_17_20_37_43.log gta5_st_yaml.txt
It was an oversight on my part. In warmup stage, the batch-norm layer of backbone should be fixed. You can modify the yaml as follows:
...
model:
pretrained: True
bn_backbone: freezed_bn # fix the bn of backbone
bn_aspp: bn
bn_decoder: bn
...
Here is a question, gtabased_class_entropy = [0.1502,0.2935,0.1362,0.4436,0.4393,0.2795,0.3139,0.3106,0.1068,0.3195,0.0719,0.2364,0.4754,0.0986,0.3673,0.4127,0.4826,0.5645,0.6694,] How is it calculated? In your article, it is the average entropy of the prediction results of each class in the target domain. Are you talking about the average value of the cross-entropy loss?