vit-pytorch
 vit-pytorch copied to clipboard
vit-pytorch copied to clipboard
Model doesn't converge
We are trying to apply this method on a medical dataset, and have about 70K images (224 res) for 5 classes. However, our training doesn't converge (we tried a range of learning rates e.g. 3e-3, 3e-4 etc.) however doesn't seem to work. Currently our model outputs 45% accuracy where the average accuracy for this dataset is around 85-90% (we trained for 100 epochs). Is there anything else we should tune?
Also, here is our configuration:
batch_size = 64
epochs = 400
lr = 3e-4
gamma = 0.7
seed = 42
efficient_transformer = Linformer(
dim=128,
seq_len=49 + 1, # 7x7 patches + 1 cls-token
depth=4,
heads=8,
k=64
)
# Visual Transformer
model = ViT(
dim=128,
image_size=224,
patch_size=32,
num_classes=5,
transformer=efficient_transformer, # nn.Transformer(d_model=128, nhead=8),
channels=1,
).to(device)
Thank you very much!
@liberbey Hey Ahmet! One of pitfalls of transformers is having settings that result in the dimension per head to be too small. The dimension per head should be at least 32 and best at 64. It can be calculated as dim // heads, so in your case, the dimension of each head is 16. Try increasing the dimension to 256 and increasing the sequence length (decrease patch size to 16) I would be very surprised if it does not work
@lucidrains Hey Phil, thank you very much for your help! I'll try these parameters and post the results here.
@lucidrains We have changed the parameters as:
efficient_transformer = Linformer(
dim=256,
seq_len=197,
depth=6,
heads=8,
k=64
)
# Visual Transformer
model = ViT(
dim=256,
image_size=224,
patch_size=16,
num_classes=5,
transformer=efficient_transformer,
channels=1,
).to(device)
But our model still does not converge. Here are the results:
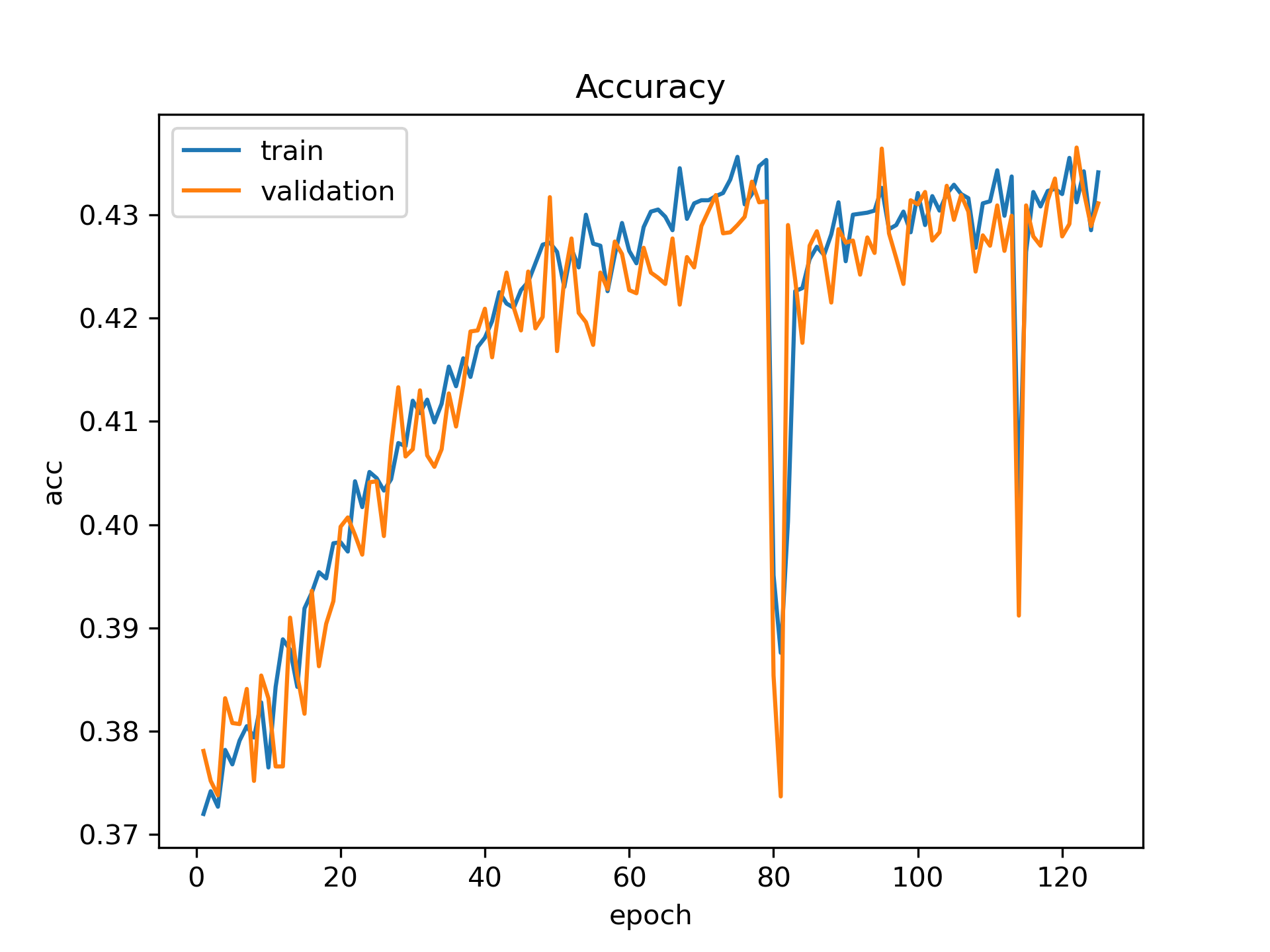
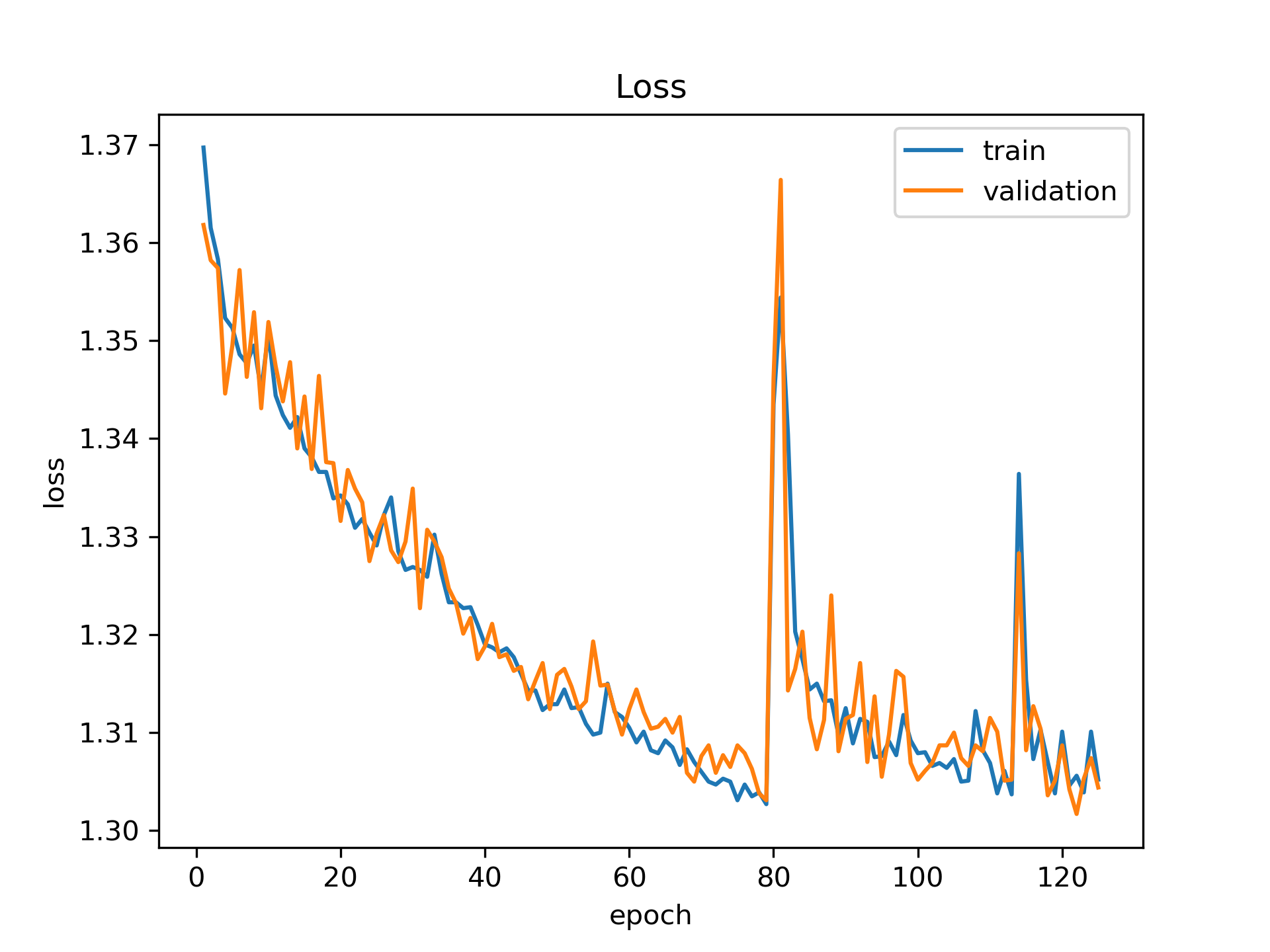
Do you have any other suggestions? Thanks again!
@liberbey I think the only option is to get a bunch of unlabelled images (in the millions) and do self-supervised learning with BYOL before fine-tuning on your dataset. Transformers only work well in the high data / compute regime
@lucidrains Thanks again! We will try to find a larger dataset. By the way, these are validation results, not test results. So we wondered if there could be another problem about our approach. Because we were expecting that the test results would be bad due to not using pretrained model but not the validation set... Also, do you have any suggestions by the dramatic drop around 80th epoch?
@lucidrains Thanks again! We will try to find a larger dataset. By the way, these are validation results, not test results. So we wondered if there could be another problem about our approach. Because we were expecting that the test results would be bad due to not using pretrained model but not the validation set... Also, do you have any suggestions by the dramatic drop around 80th epoch?
Did you use a special learning rate scheduler? My loss curve on my own dataset also shows an uncommon curve, check here. Seems that ViT is hard to train.
@SuX97 We didn’t use anything special for tuning the learning rate, however I am not sure if this repo is coming with a default scheduler @lucid
@SuX97 @liberbey well, there's been a new development, you two should try https://github.com/lucidrains/vit-pytorch#distillation
@liberbey hey you'll probably need a schedule with linear warmup for training any transformer, look here for more info
@umbertov Thanks for the suggestion. Do you know if it is supported in this repo? @lucidrains
@lucidrains I just want to make sure: can I first do BYOL, and then try Distillation on top of it using this repo?
Hello All,
Is there any updates regarding ViT convergence? as I am facing the same issue. And are the suggested papers help in tackling this issue?
Thanks in advance.
Hi All,
Very good question. I have implemented 8 transformers and out of 7 VITs have a serious convergence problem. The dataset size is 97000
Regards, Khawar
Hello @khawar512,
Could u please mention the survived model :D that works fine with u? If u could mention the other 7 models too, it will be great .
Thanks in advance.
Hi @eslambakr
The best model is Praymid ViT Swin, CAIT, CrossViT, CeiT, ViT,NesT, PVT.
Thank you very much @khawar512 . But I don't know what do u mean by Praymid ViT, is it differs than PVT. If yes can u please share a reference to the paper and an implementation for it if exists?
Besides, I will try "DeiT: Training data-efficient image transformers & distillation through attention" https://arxiv.org/abs/2012.12877 and share the updates here. As I believe it should overcome the convergence problem.
@eslambakr
I am talking about below paper https://arxiv.org/abs/2102.12122
Any update on this? I also have problems getting the ViT converge on a medical classification dataset (50K) that converges fine on CNNs.
I can confirm I have the same issue, and I'm not even using this repo. I'm using ContinuousTransformerWrapper from https://github.com/lucidrains/x-transformers together with an extra cls_token bolted on for classification.
So this could be a general artefact of using transformers for classification. This is surprising to me.
The reason why I want to use something like simple_vit_1d is that i'm classifying speech which has a lot of temporal content that a CNN will struggle to capture.