Support for collections.mcny.org
Hello. I'm trying to find support for:
http://collections.mcny.org/C.aspx?VP3=SearchResult&VBID=24UAYWLSZW1VA&SMLS=1&RW=1920&RH=959
Click image, then click magnifying glass at bottom left. They use flash. I zoom to 100% and I can access the tiles via inspect/Network tab (e.g. http://collections.mcny.org/Doc/MNY/TEMP/CACHE/MN1/zoomOL/MNY13110/3xe4crF1pPTnNb5xhkcltBmW.jpeg), but can't figure out the code to stitch them together.
Thanks.
Been researching this for a while and I still can't solve the puzzle with mcny.org.
Before Flash become obsolete in the coming year, I thought I'd reach out one more time to see if anyone has any luck with the zoomable images on mcny.org.
The tiles use a unique (and seemingly random) combination of characters for each jpg and I can't pinpoint the script that determines this labeling.
Any help would be greatly appreciated.
Hello, I had a quick look at the site, and they use a protocol I have never seen on other sites. It looks like they get the tile URLs from requests like
https://collections.mcny.org/htm/ZoomOLGetBlocks.aspx?s=0.5&h=4796&w=4132&y=4537&x=3871&k=%2FFkVcgpYYRt49rRArPHnVBF3ClLKrhlKL%2FsAyWBcSiM&i=MNY13110
which returns date like
sBlockResponse=/Doc/MNY/TEMP/CACHE/MN1/zoomOL/MNY13110/zaVpBrA9VbxNAzoNfiDzkYo.jpeg|3600|4400|1||/Doc/MNY/TEMP/CACHE/MN1/zoomOL/MNY13110/D2sWup3pb2yZI2bLBHaorrE.jpeg|3600|4800|1||/Doc/MNY/TEMP/CACHE/MN1/zoomOL/MNY13110/d0icuoW6ShpUjn8zpt6jQTP.jpeg|4000|4400|1||/Doc/MNY/TEMP/CACHE/MN1/zoomOL/MNY13110/CZ6zw43IcQArqsrjYsYBFJq.jpeg|4000|4800|1
If you are interested in writing a dezoomer for this format, you can follow the instructions on our wiki. Don't hesitate to ask for help if you need.
Thanks for the reply. Been working like mad on trying to write a dezoomer and I'm running into endless snafus. If anyone else reading this is up for a challenge, dig in.
I tried to use the JS script example from the WIKI for the mcny.org site but I am having a little trouble following the code and making sure I have the variables populated correctly. And I'm getting syntax errors when I execute my version of the modified script.
I'm able to find the Request URL and the form data for each image. And I'm able to get the sBlockResponse paths for each image. But I'm not sure where to input the data in the actual script to grab the images for stitching?
I'm attaching a screenshot of what I have. I know it's incomplete, but I'm just not sure how to populate the script.
Any help would be greatly appreciated.
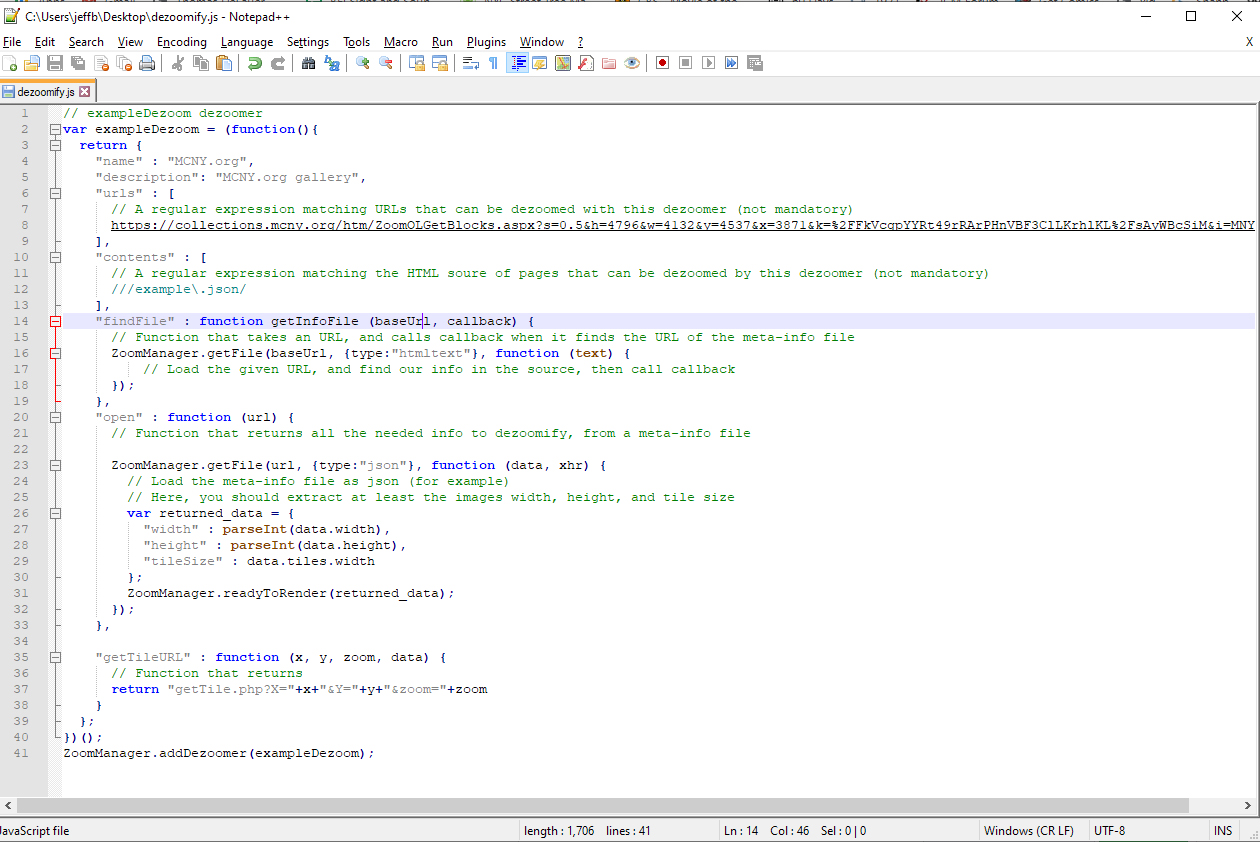
Good. I think you should use a better code editor to write javascript (such as VSCode or Atom). This should allow you to avoid syntax errors. For instance, urls should contain a regular expression. You cannot just copy and paste the URL in the javascript code.
In findFile, you should write code that finds the ZoomOLGetBlocks URL for the page.
In open, you should compute the width height and tile size from the sBlockResponse text.
In getTileURL you should return a tile URL given the row and column of the image.