albert_pytorch
 albert_pytorch copied to clipboard
albert_pytorch copied to clipboard
A Lite Bert For Self-Supervised Learning Language Representations
做post-training 发现缺少optimizer.bin 这个文件,即run_pretraining.py 的228、229行: if args.model_path: optimizer.load_state_dict(torch.load(args.model_path + "/optimizer.bin"))

如题,阅读源码发现main函数只进行了定义,未进行调用,盲猜少了下面的代码: if __name__ == "__main__": main()
下面这个代码取自model/modeling_bert.py 按这个代码的意思,我理解应该是在第二个子层(也就是在Attention子层出来以后),进行如下计算 BertIntermediate 1 全连接nn.Linear 2 激活函数 BertOutput 1 全连接nn.Linear 2 残差 3 dropout 这样就有两个nn.Linear了。这和论文上提到的模型不一致。我理解应该是只有一个nn.Linear class BertIntermediate(nn.Module): def __init__(self, config): super(BertIntermediate, self).__init__() self.dense = nn.Linear(config.hidden_size, config.intermediate_size) if isinstance(config.hidden_act, str) or...
Albert能否在训练时减少显存占用? 比如,假如两个网络同样有6个注意力模块,第一个网络没有参数共享,第二个网络在所有模块间都进行了参数贡献,那么在训练时两个模型显存占用会不会有特别明显差别? 换句话讲,Albert的优点只是减小了模型的size吗?
您好, 请问readme中fine-tune结果的超参数(比如训练epoch数量,batch size, learning rate)等可以公布说明吗?为什么CoLA上的结果只有0.5+呢?
提供的albert v2版本下载,里面没有tf的权重文件,直接给了转换好的pytorch_model。真tm坑人,搁着耍猴呢?浪费老子一个小时时间,真是日死这外国佬,艹你妈的
在执行convert_albert_tf_checkpoint_to_pytorch.py时出现如下错误, 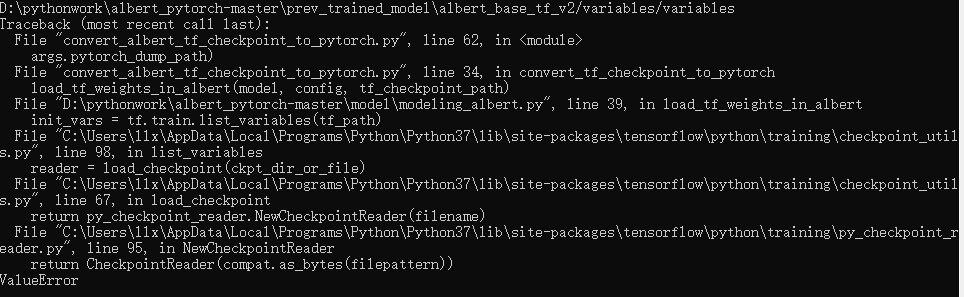
Hey, I was going through the code and found out that you had used NSP on pytorch Albert implementation. Doesn't Albert use Sentence Order Predicition??
您好,感谢您的分享。 请问如果我想在代码中加入pytorch的重计算机制(torch.utils.checkpoint)来减少显存开销,应该怎么做呢?
Metadata
Owner
Metadata
A Lite Bert For Self-Supervised Learning Language Representations