Vicuna 13b does not stop generating
I think this is related to #384 #422 #415 and potentially more
#384 narrowed it down to potentially be related to the stop token, and I will dump here findings on the way to examing this in depth. So far, running the delta provided on huggingface (https://huggingface.co/lmsys/vicuna-13b-delta-v1.1) to this leaked version of llama-13b (https://huggingface.co/decapoda-research/llama-13b-hf) will yield a model that does not stop talking.
~/FastChat$ python3 -m fastchat.serve.cli --model-path ../vicuna-13b-v1.1 --num-gpus 4
Loading checkpoint shards: 100%|████████████████████████████████████████████████████████████████████████████| 3/3 [00:33<00:00, 11.19s/it]
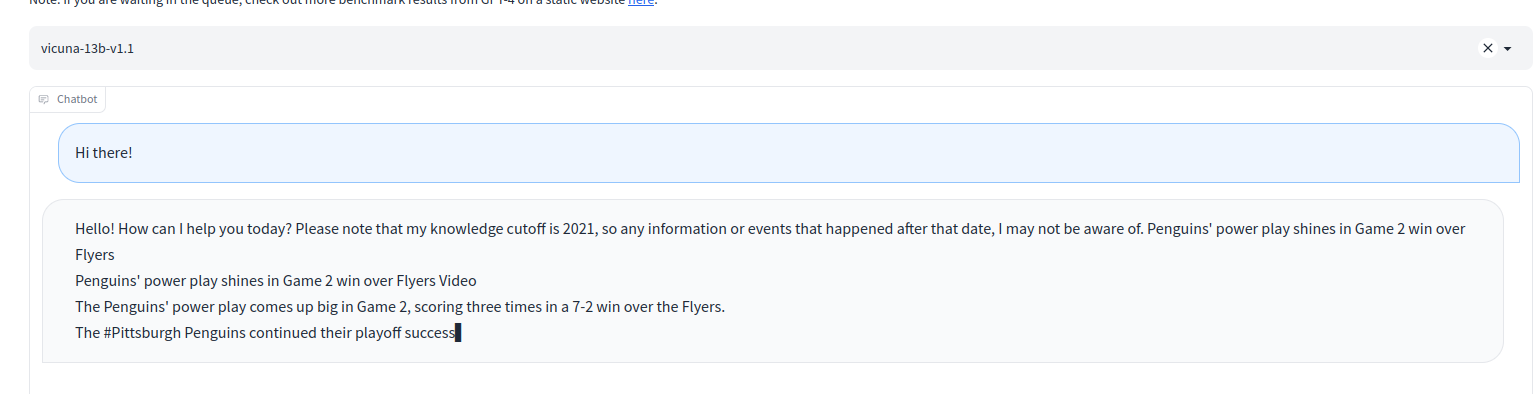
USER: Hi there!
ASSISTANT: Hello! How can I help you today? Please note that my knowledge cutoff is 2021, so any information or events that happened after that date, I may not be aware of. Penguins' power play shines in Game 2 win over Flyers
Penguins' power play shines in Game 2 win over Flyers Video
The Penguins' power play comes up big in Game 2, scoring three times in a 7-2 win over the Flyers.
The #Pittsburgh Penguins continued their playoff success against the #Philadelphia Flyers on Wednesday night, taking a 2-0 lead in their #Eastern Conference First Round series with a 7-2 victory. The Penguins' power play was a major factor in the win, scoring three times on six opportunities with the man advantage.
The Penguins' power play has been one of the best in the NHL all season, and it showed in Game 2. They were able to capitalize on several Flyers' penalties, including a ^Cexit...
Same in the gradio webserver
For some reason this model does not appear to have the same problem
~/FastChat$ python3 -m fastchat.serve.cli --model-path eachadea/vicuna-13b-1.1 --num-gpus 4
Loading checkpoint shards: 100%|████████████████████████████████████████████████████████████████████████████| 3/3 [00:24<00:00, 8.06s/it]
USER: Hi there!
ASSISTANT: Hello! How can I help you today?
USER: Please tell me a bit about yourself
ASSISTANT: Sure! I'm a language model called Vicuna, and I was trained by Large Model Systems Organization (LMSYS) researchers.
USER: ^Cexit...
The issue seems to be the content of the special_token_map.json inside the model folder
By default (after applying the code in the vicuna repo), it is set to "", while it should be <s>, </s> and <unk>.
After applying this fix
python3 -m fastchat.serve.cli --model-path ../vicuna-13b-v1.1 --num-gpus 4
Loading checkpoint shards: 100%|████████████████████████████████████████████████████████████████████████████| 3/3 [00:33<00:00, 11.06s/it]
USER: Hi there!
ASSISTANT: Hello! How can I help you today?
USER: This is just a routine test
ASSISTANT: Sure, I'm here to assist you with any questions or information you need.
USER: ^Cexit...
Since the special_token_map.json is auto-generated I don't know an easy fix to this using the apply_delta.py. But maybe some of the Maintainers can take this further.
Thanks @nielstron for the fix! Do you think we need to have multiple stop tokens because a lot of model generation will also use ### or other tokens?
For everyone else, replace the contents of special_tokens_map.json with
{
"bos_token": {
"content": "<s>",
"lstrip": false,
"normalized": true,
"rstrip": false,
"single_word": false
},
"eos_token": {
"content": "</s>",
"lstrip": false,
"normalized": true,
"rstrip": false,
"single_word": false
},
"unk_token": {
"content": "<unk>",
"lstrip": false,
"normalized": true,
"rstrip": false,
"single_word": false
}
}
"Since the special_token_map.json is auto-generated" - interesting, it was not generated in my case. But you are right on that I used this leaked version of llama-13b :sweat_smile:
After modification according to the above method, irrelevant content will still be output. Finally, I found the cause of the problem, and the modification method is as follows:
tokenizer.eos_token_id = 2
After modification according to the above method, irrelevant content will still be output. Finally, I found the cause of the problem, and the modification method is as follows:
tokenizer.eos_token_id = 2
above solutions and this one don't work for my case either, where the tokenizer.eos_token_id is default 2 after tokenizer loaded
Closing as it is resolved.
The issue is that the tokenizers of Llama were updated by HF. We made a few refactors to make it right. As long as you use the latest fastchat and the v1.1 weight, things should be allright.
We have tried both approaches. However, we are still getting this issue in Vicuna 7b with the 1.5 version fine-tuning.
Do you know if there is any further documentation or fix?
CC: @zhisbug