weekly

weekly copied to clipboard
【开源自荐】bilive - 7 x 24 小时无人监守录制、渲染弹幕、识别字幕、自动切片、自动上传、兼容超低配机器,启动项目,人人都是录播员
项目名称
bilive - 7 x 24 小时无人监守录制、渲染弹幕、识别字幕、自动切片、自动上传、兼容超低配机器,启动项目,人人都是录播员。
开源地址
https://github.com/timerring/bilive
项目文档
https://bilive.timerring.com/
项目简介
自动监听并录制B站直播和弹幕(含付费留言、礼物等),根据分辨率转换弹幕、语音识别字幕并渲染进视频,根据弹幕密度切分精彩片段并通过视频理解大模型生成有趣的标题,自动投稿视频和切片至B站,兼容无GPU版本,兼容超低配置服务器与主机。
项目功能
- 速度快:采用
pipeline流水线处理视频,理想情况下录播与直播相差半小时以内,没下播就能上线录播,目前已知 b 站录播最快版本! - 多房间:同时录制多个直播间内容视频以及弹幕文件(包含普通弹幕,付费弹幕以及礼物上舰等信息)。
- 占用小:自动删除本地已上传的视频,极致节省空间。
- 模版化:无需复杂配置,开箱即用,( :tada: NEW)通过 b 站搜索建议接口自动抓取相关热门标签。
- 检测片段并合并:对于网络问题或者直播连线导致的视频流分段,能够自动检测合并成为完整视频。
- 自动渲染弹幕:自动转换xml为ass弹幕文件并且渲染到视频中形成有弹幕版视频并自动上传。
- 硬件要求极低:无需GPU,只需最基础的单核CPU搭配最低的运存即可完成录制,弹幕渲染,上传等等全部过程,无最低配置要求,10年前的电脑或服务器依然可以使用!
- ( :tada: NEW)自动渲染字幕(如需使用本功能,则需保证有 Nvidia 显卡):采用 OpenAI 的开源模型
whisper,自动识别视频内语音并转换为字幕渲染至视频中。 - ( :tada: NEW)自动切片上传:根据弹幕密度计算寻找高能片段并切片,结合多模态视频理解大模型
GLM-4V-PLUS自动生成有意思的切片标题及内容,并且自动上传。 - ( :tada: NEW)已上线 docker
项目架构
graph TD
User((用户))--record-->startRecord(启动录制)
startRecord(启动录制)--保存视频和字幕文件-->videoFolder[(Video 文件夹)]
User((用户))--scan-->startScan(启动扫描 Video 文件夹)
videoFolder[(Video 文件夹)]<--间隔两分钟扫描一次-->startScan(启动扫描 Video 文件夹)
startScan <--视频文件--> whisper[whisperASR模型]
whisper[whisperASR模型] --生成字幕-->parameter[查询视频分辨率]
subgraph 启动新进程
parameter[查询分辨率] -->ifDanmaku{判断}
ifDanmaku -->|有弹幕| DanmakuFactory[DanmakuFactory]
ifDanmaku -->|无弹幕| ffmpeg1[ffmpeg]
DanmakuFactory[DanmakuFactory] --根据分辨率转换弹幕--> ffmpeg1[ffmpeg]
ffmpeg1[ffmpeg] --渲染弹幕及字幕 --> Video[视频文件]
Video[视频文件] --计算弹幕密度并切片--> GLM[多模态视频理解模型]
GLM[多模态视频理解模型] --生成切片信息--> slice[视频切片]
end
slice[视频切片] --> uploadQueue[(上传队列)]
Video[视频文件] --> uploadQueue[(上传队列)]
User((用户))--upload-->startUpload(启动视频上传进程)
startUpload(启动视频上传进程) <--扫描队列并上传视频--> uploadQueue[(上传队列)]
项目模式
pipeline模式(默认): 目前最快的模式,需要 GPU 支持,最好在blrec设置片段为半小时以内,asr 识别和渲染并行执行,分 p 上传视频片段。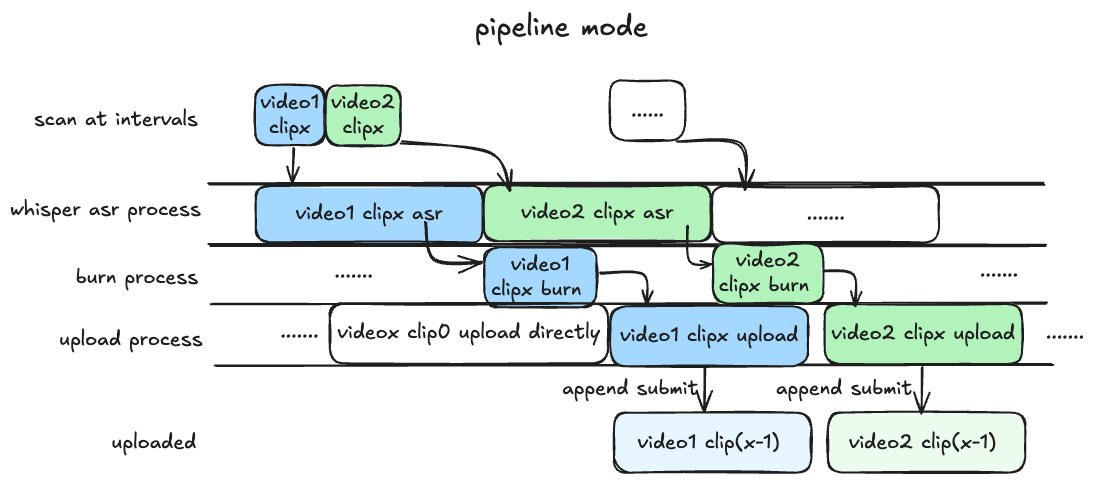
append模式: 基本同上,但 asr 识别与渲染过程串行执行,比 pipeline 慢预计 25% 左右,对 GPU 显存要求较低,兼顾硬件性能与处理上传效率。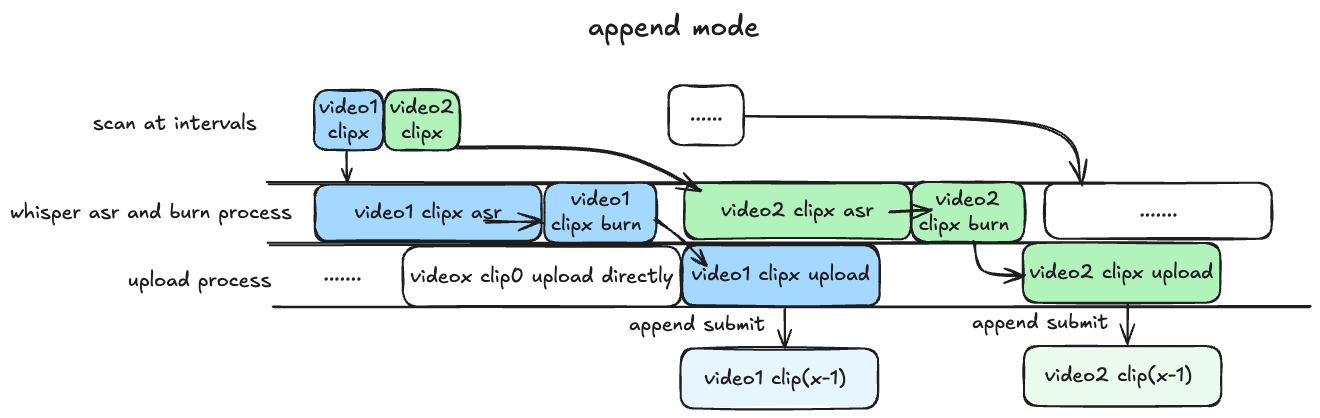
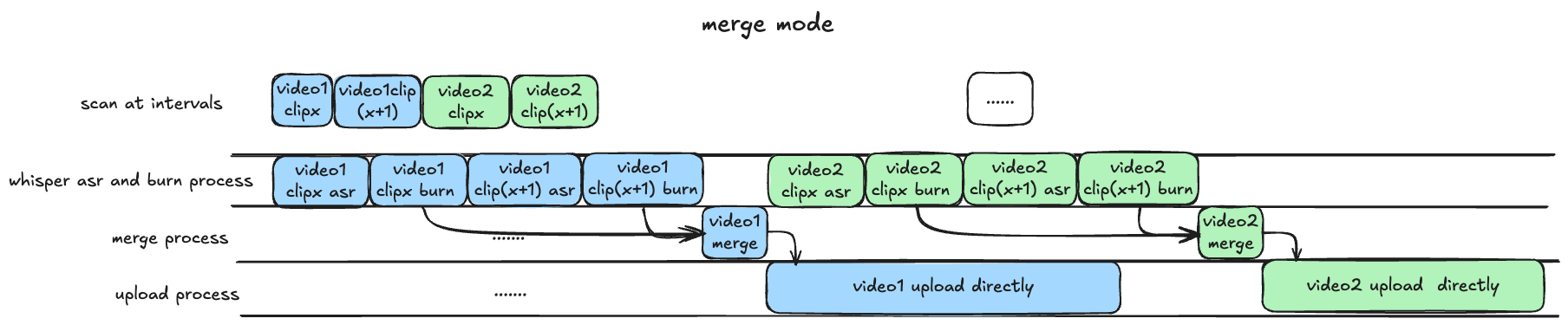
merge模式: 等待所有录制完成,再进行识别渲染合并过程,上传均为完整版录播(非分 P 投稿),等待时间较长,效率较慢,适合需要上传完整录播的场景。