BLASX
 BLASX copied to clipboard
BLASX copied to clipboard
large scale Dgemm segmentation fault
Hello, there are still errors when applying the library to a large matrix gemm on multiple GPUs. I need to find another library that can replace cublasXt and execute large-scale matrix gemm on multiple GPUs. Therefore, I tested Dgemm on 50000X50000 and 50000X50000. In the end, I got a segmentation error. I tried to figure out what the problem was. But it's hard for me to go deep. I just found that cublasGetMatrixAsync and cublasSetMatrixAsync seem to be wrong in blasx_dgemm.c. Here is the gdb info about this.
 If you can help, I really appreciate it.
If you can help, I really appreciate it.
Would you please tell me your environment? Which cuda version and how many GPUs are you using?
Yes, it can work for 20000 x 20000 double matrix. Sorry, I just found another issues about this. So it seems the 50000 x 50000 double matrix exceeds the available device memory and there is no memory check. It is a pity to use the lib to solve large-scale problems.
okay. It is already very impressive to see 2*10^4 case working on GPU.
The purpose of this library is to demonstrate a new system design to support large scale matrix multiplications, not for production use. We're researchers to focus on ideas. Maintaining and implementing a production level code base is too laborious for us to do, therefore I recommend you using cuBLAS-XT instead. Thank you for your interest.
I reproduced your bug and found out the issue of seg fault came from the overflow of int. https://github.com/linnanwang/BLASX/blob/master/blas/blasx_dgemm.c#L64 I already created a PR and will merge it into master ASAP.
The advantage of BLASX is allowing super large matrix that can not be fit in GPU memory as long as it can be fit into CPU memory, because we split matrix into tiles and have a task runtime to swap tiles into/out of GPU memory.
Thanks very much!!! I take the change to the code. But unfortunately, there still a seg fault. When running large matrix(n=50000), it will cause seg fault again. It seems carsh when running mem_control_kernel_double.
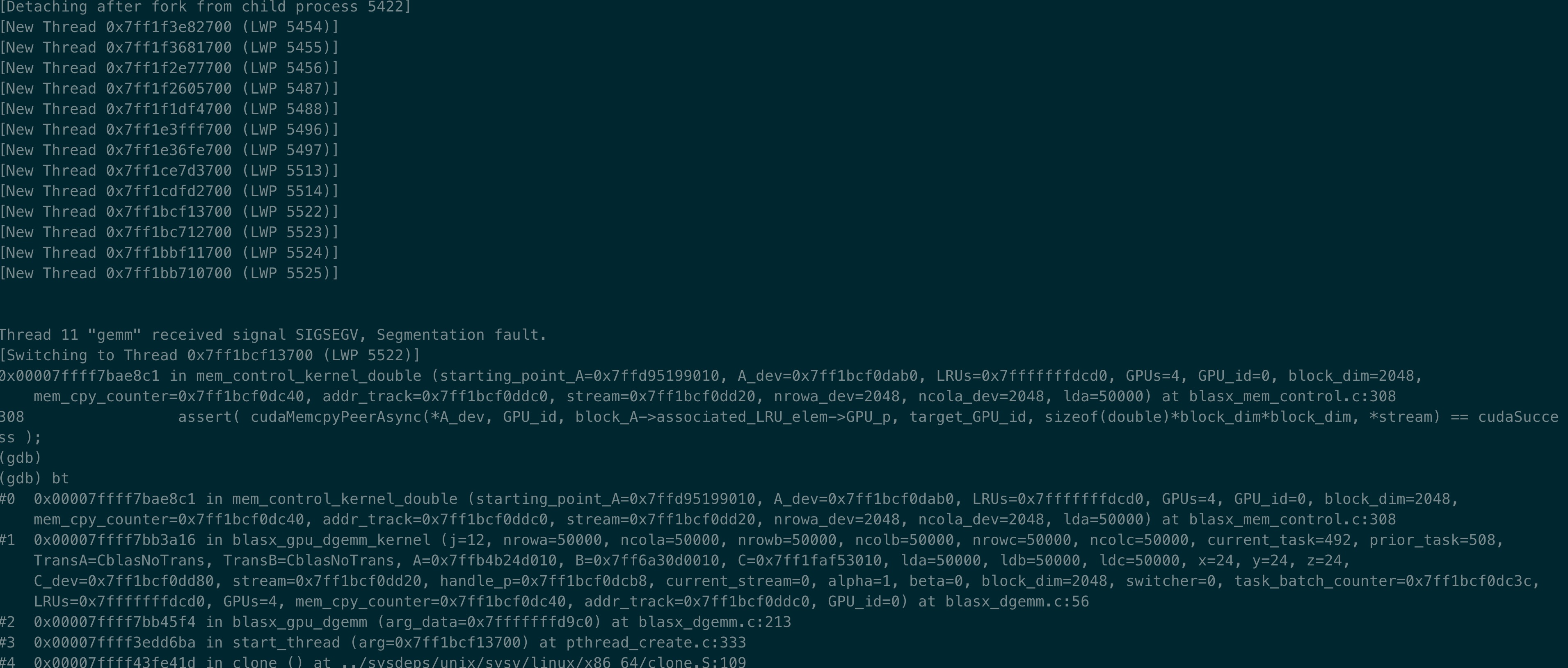 I have four GeForce GTX 1080 Ti with 10G device memory.
I have four GeForce GTX 1080 Ti with 10G device memory.
I feel like it is another overflow. I ran 50K*50K sgemm with 1 GPU and it works fine. I do not have a multi-gpu machine now. Can you try sgemm on 1 GPU?