llama2-webui
 llama2-webui copied to clipboard
llama2-webui copied to clipboard
Run any Llama 2 locally with gradio UI on GPU or CPU from anywhere (Linux/Windows/Mac). Use `llama2-wrapper` as your local llama2 backend for Generative Agents/Apps.

Failed to build llama-cpp-python ERROR: Could not build wheels for llama-cpp-python, which is required to install pyproject.toml-based projects
## Environment - OS : MacOS Ventura 13.5.1 - Shell : Fish 3.6.1 - Python : 3.11.4 ## Issue Getting an error when launching the app with the standard, unmodified,...
Dear llama2-webui developer, Greetings! I am vansinhu, a community developer and volunteer at InternLM. Your work has been immensely beneficial to me, and I believe it can be effectively utilized...
On Macbook CPU inference,run in Docker,user Chinese Error models GGML: https://huggingface.co/LinkSoul/Chinese-Llama-2-7b-ggml/blob/main/Chinese-Llama-2-7b.ggmlv3.q4_1.bin  llama.cpp: loading model from /app/model/llama-2-7b-chat.ggmlv3.q4_1.bin llama_model_load_internal: format = ggjt v3 (latest) llama_model_load_internal: n_vocab = 32000 llama_model_load_internal: n_ctx =...
we build a WebUi to use llama,llama2, vicuna, falcon, etc. It's pretty good, if someone wants to run llama2, and maybe this project also can use it. 😊 https://github.com/eosphoros-ai/DB-GPT-Web
# # test log Cloud platform: matpool.com Machine used: NVIDIA A40 Model used: Llama-2-13b-chat-hf After the model is loaded, it takes up video memory: about 26G 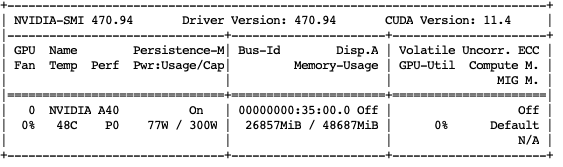 Inference memory usage:...
Metadata
Owner
Metadata
Run any Llama 2 locally with gradio UI on GPU or CPU from anywhere (Linux/Windows/Mac). Use `llama2-wrapper` as your local llama2 backend for Generative Agents/Apps.