hydra-booster
 hydra-booster copied to clipboard
hydra-booster copied to clipboard
Hydra-nodes sharing Provider Records after 24 hours
Hey there!
I'm been working lately on measuring the Provider Record Liveness in the IPFS network following the network measurement RFM 17. I built a little tool able to publish randomly generated CIDs, and that tracks the activity of the peers that were contacted to store the PRs over a given period (including whether they have or not the PRs).
I performed a few studies publishing 10k random CIDs to K=20 peers for ~36 hours with a peer dialing frequency of 30 mins (without republishing the PRs), and I found some weird behavior in hydra nodes.
In the following graph, we can observe the quartile distribution of the peers that successfully returned the PRs for the generated CIDs over the dial rounds, where we can clearly see a significant drop of peers that keep the PRs after 24 hours (~round 48).
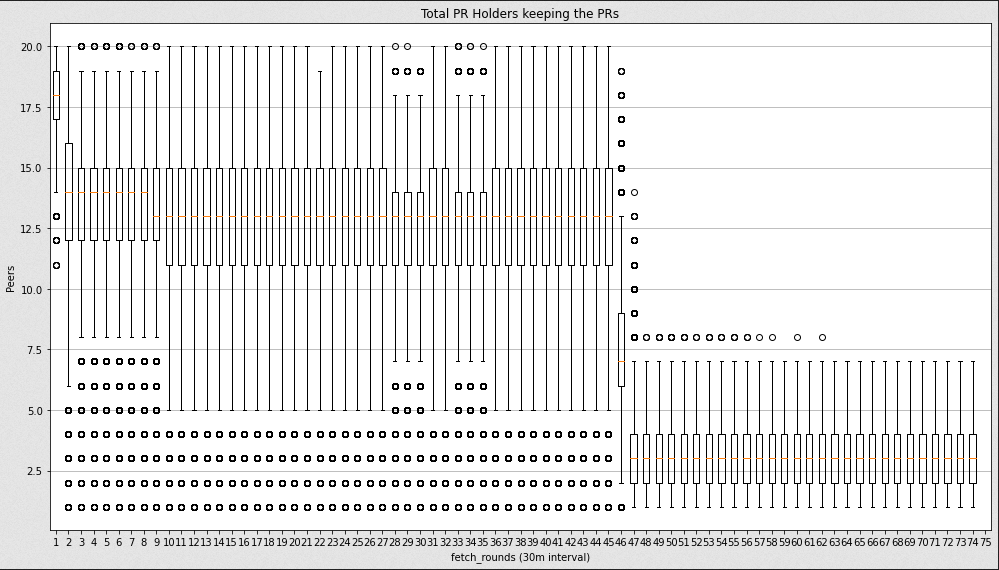
I thought that by specs, the PRs of a CID should expire after 24 hours (if there is no republish taking place), so if anyone requests them after those 24 hours, nodes shouldn't return them even if they have them.
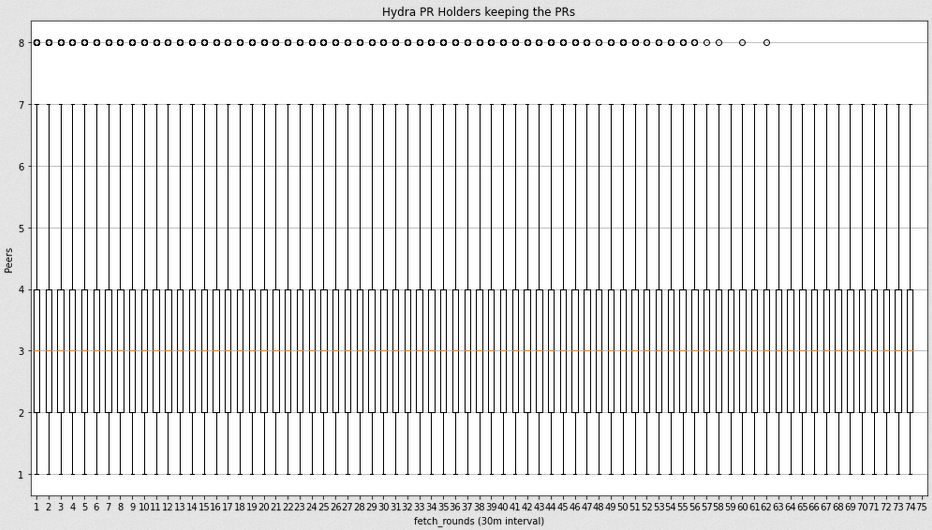
After filtering by User Agent the ones that are hydra-boosters, Hydra peers show a stable activity returning the PRs when asking for them over the ~36 hours of study.
On the other hand, if we display the exact same quartile graph rest of the nodes with a non-hydra UserAgent, we can observe the clear drop of peers returning the PRs after 24 hours (round ~48).

Is there any reason behind it? Is it possible that since I'm fetching the PRs of the CIDs every 30 mins, my tool is "increasing" the popularity of the content and therefore the PRs get cached somewhere in the Hydra nodes?
Cheers!
afaik, hydras honor the TTL of the records and then use DynamoDB auto-eviction to clear out records w/o needing to do a GC on the datastore. Are you setting a long TTL and go-ipfs has a max TTL set and perhaps the hydras alone honor it?
I was just publishing random content to the network, I didn't run any Hydra-booster by myself. So unless all the Hydras out there manually set up a longer TTL, my measurements show that the default TTL is not getting followed.
I was going through the running multiple hydras chapter of the README file, and it does seem that at least one of the Hydras has to do a GC on the provider records:
When sharing a datastore between multiple Hydras, ensure only one Hydra in the swarm is performing GC on provider records by using the -disable-prov-gc flag or HYDRA_DISABLE_PROV_GC environment variable, and ensure only one Hydra is counting the provider records in the datastore by using the -disable-prov-counts flag or HYDRA_DISABLE_PROV_COUNTS environment variable.
Could it be that a large Hydra swarm forgot to enable the GC in at least one node?
Hey there @thattommyhall !
I kept digging about the Hydra incident and I spotted a bug in my plotting script. The bug was leading to actually not display the entire distribution of points in the graph, and that explains why non of the graphs had representation at 0 peers.
Once it has been solved, I can still see a clear difference between the hydras and non-hydras peers:
Hydras distribution:
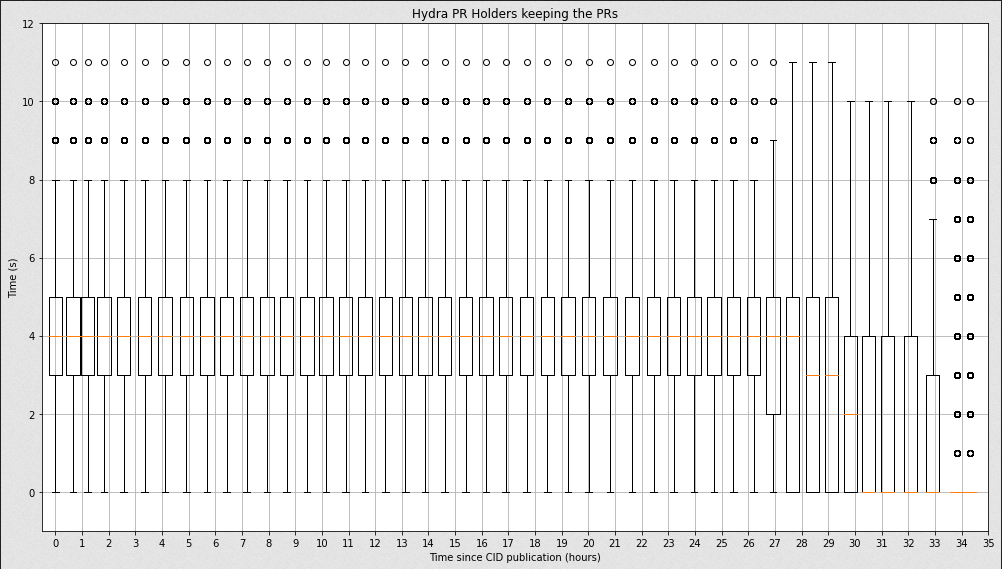
Non-Hydras distribution:
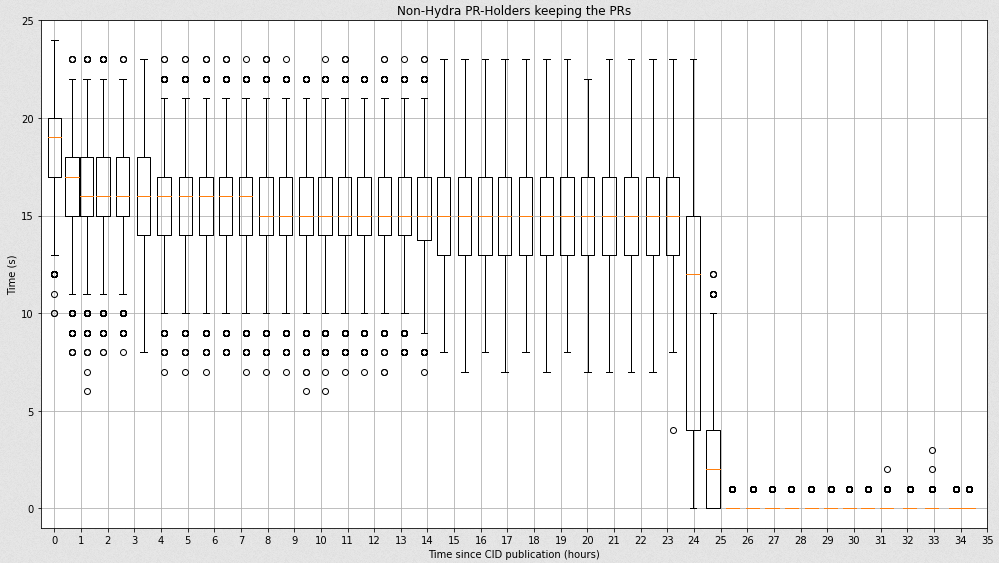
which actually means that the content is still retrievable after 24 hours:
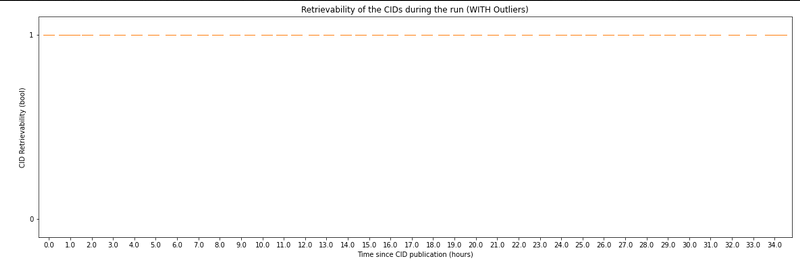
Would you still consider the modification of the TTL parameter as an explanation for this behavior?