Write a custom PyTorch extension for Stream+Collide
The computational bottleneck in LBM simulations is memory access. The current code framework handles that very naively. To boost the performance, the collision and streaming routines can be combined, like for example in the esoteric twist method. This would require to step beyond the standard routines offered by PyTorch and write custom C++/CUDA PyTorch extensions: https://pytorch.org/tutorials/advanced/cpp_extension.html
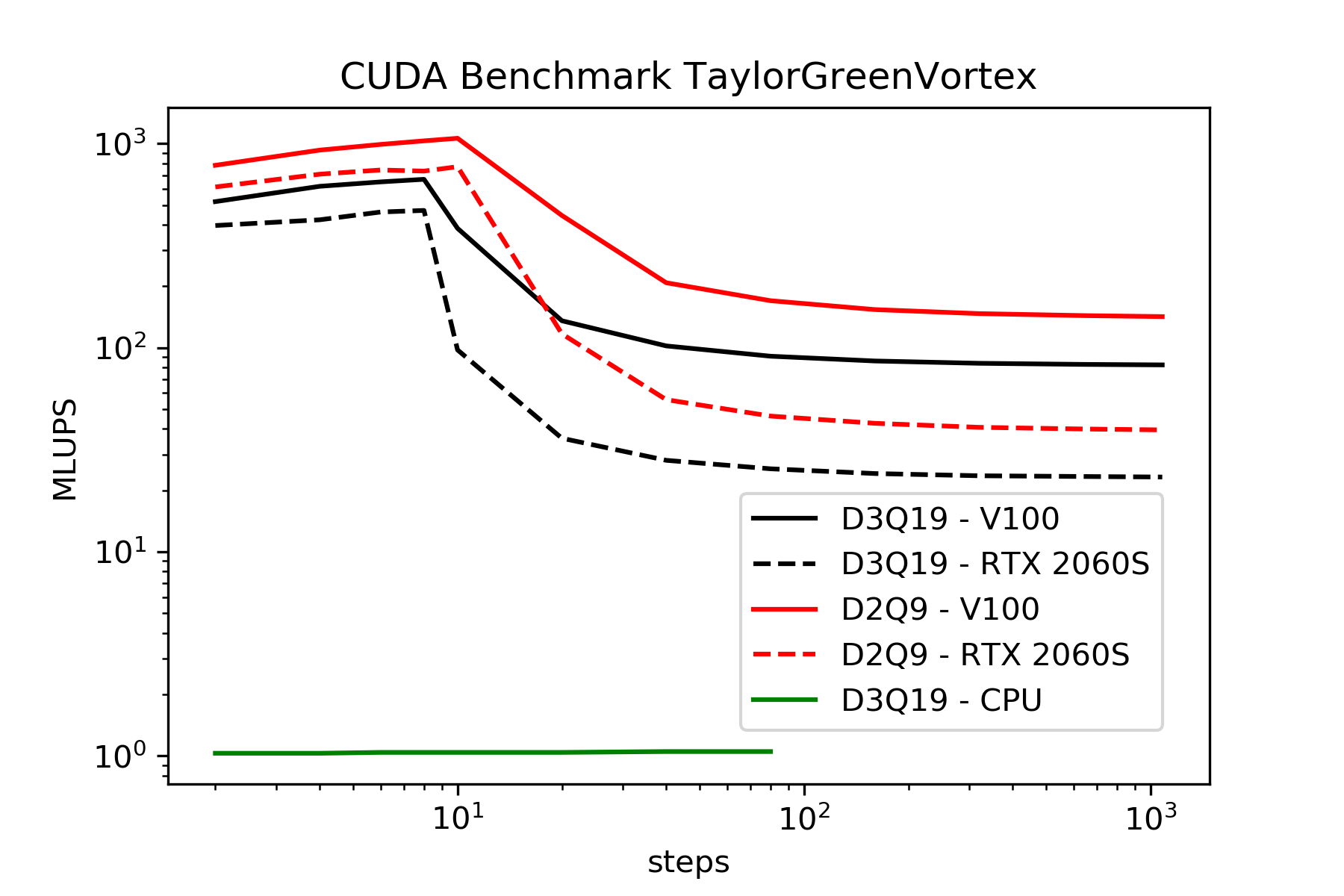
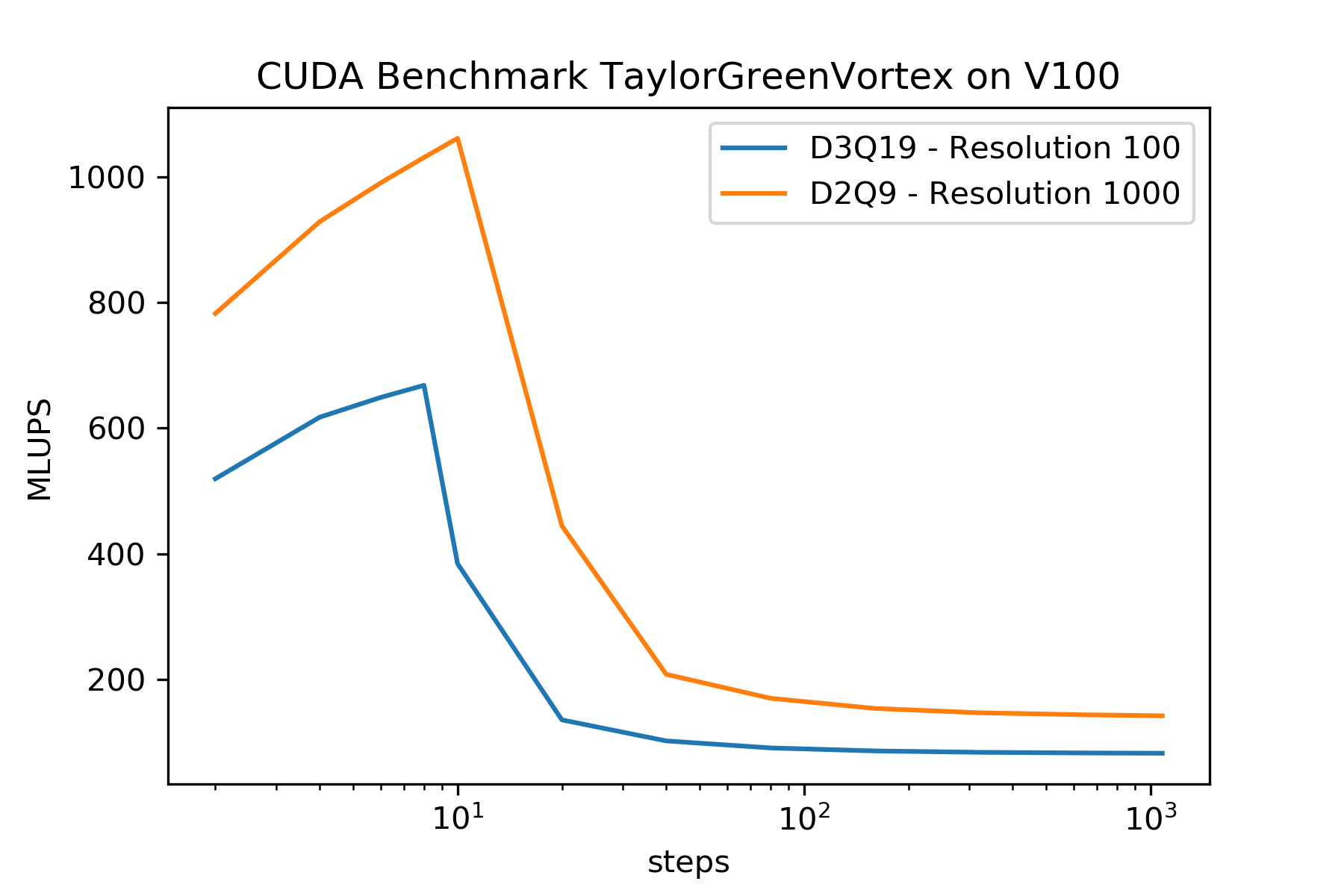
The current performance strongly depends on the number of steps. The following figure shows a benchmark for a TGV2D/3D on a V100. The performance decreases strongly if more than 8-10 steps are executed.
Here are some additional data. As expected, the performance of the RTX 2060 Super (8Gb) is lower than the V100. However, the performance collapse can also be seen here. This behavior cannot be seen for the CPU (see figure)