Demo
First of all thank you for the great work. I'm currently trying to set up a demo of the estimator but run into some issues in the post-processing stage (the network output is a B x 17 x 128 x 128 for 512x512 images) Are planning to release any helper functions for post-processing the output to a key-points ?
Many thanks
When I am free, I will add a demo for inference. For your issue, you can read our code at https://github.com/leoxiaobin/deep-high-resolution-net.pytorch/blob/master/lib/core/inference.py, which include how to get the final prediction with the heatmaps.
@MassyMeniche @leoxiaobin With a quick dive into codes, find a function to get max preds:
heatmaps = out.detach().cpu().numpy()
preds, maxvals = get_max_preds(heatmaps)
Which out is simply raw ouput of network. the preds shape is Bx17x2. I suppose it's 17 keypoints coordinates? But when I draw it it does not seems right:

What does that function gets? How to get the final keypoints coordinates finally?
@jinfagang , after you get the preds, you should also need to project the coordinates to the original image, using the function at https://github.com/leoxiaobin/deep-high-resolution-net.pytorch/blob/master/lib/core/inference.py#L49****
@jinfagang , after you get the preds, you should also need to project the coordinates to the original image, using the function at https://github.com/leoxiaobin/deep-high-resolution-net.pytorch/blob/master/lib/core/inference.py#L49****
what does the center and scale mean?...
@njustczr After a digging in, I think it's the object detection box.. which means you should do object detection first..
@njustczr After a digging in, I think it's the object detection box.. which means you should do object detection first..
center:bbox center? scale: the ratio of (width / height) ?
@njustczr After a digging in, I think it's the object detection box.. which means you should do object detection first..
get_max_preds() performs better than get_final_preds()?... scale=height/200.0
I have the same question. Please share how did you get keypoints on your own data.
By refecence this code[https://github.com/microsoft/human-pose-estimation.pytorch/issues/26#issuecomment-447404791], I can get good result. Make a file in the tools folder, and name it as "demo.py"
from __future__ import absolute_import
from __future__ import division
from __future__ import print_function
import argparse
import os
import pprint
import torch
import torch.nn.parallel
import torch.backends.cudnn as cudnn
import torch.optim
import torch.utils.data
import torch.utils.data.distributed
import torchvision.transforms as transforms
import _init_paths
from config import cfg
from config import update_config
from core.loss import JointsMSELoss
from core.function import validate, get_final_preds
from utils.utils import create_logger
from utils.transforms import *
import cv2
import dataset
import models
import numpy as np
def parse_args():
parser = argparse.ArgumentParser(description='Train keypoints network')
# general
parser.add_argument('--cfg',
help='experiment configure file name',
default='experiments/mpii/hrnet/w32_256x256_adam_lr1e-3.yaml',
type=str)
parser.add_argument('opts',
help="Modify config options using the command-line",
default=None,
nargs=argparse.REMAINDER)
parser.add_argument('--img-file',
help='input your test img',
type=str,
default='')
# philly
parser.add_argument('--modelDir',
help='model directory',
type=str,
default='')
parser.add_argument('--logDir',
help='log directory',
type=str,
default='')
parser.add_argument('--dataDir',
help='data directory',
type=str,
default='')
parser.add_argument('--prevModelDir',
help='prev Model directory',
type=str,
default='')
args = parser.parse_args()
return args
def _box2cs(box, image_width, image_height):
x, y, w, h = box[:4]
return _xywh2cs(x, y, w, h, image_width, image_height)
def _xywh2cs(x, y, w, h, image_width, image_height):
center = np.zeros((2), dtype=np.float32)
center[0] = x + w * 0.5
center[1] = y + h * 0.5
aspect_ratio = image_width * 1.0 / image_height
pixel_std = 200
if w > aspect_ratio * h:
h = w * 1.0 / aspect_ratio
elif w < aspect_ratio * h:
w = h * aspect_ratio
scale = np.array(
[w * 1.0 / pixel_std, h * 1.0 / pixel_std],
dtype=np.float32)
if center[0] != -1:
scale = scale * 1.25
return center, scale
def main():
args = parse_args()
update_config(cfg, args)
logger, final_output_dir, tb_log_dir = create_logger(
cfg, args.cfg, 'valid')
logger.info(pprint.pformat(args))
logger.info(cfg)
# cudnn related setting
cudnn.benchmark = cfg.CUDNN.BENCHMARK
torch.backends.cudnn.deterministic = cfg.CUDNN.DETERMINISTIC
torch.backends.cudnn.enabled = cfg.CUDNN.ENABLED
model = eval('models.'+cfg.MODEL.NAME+'.get_pose_net')(
cfg, is_train=False
)
if cfg.TEST.MODEL_FILE:
logger.info('=> loading model from {}'.format(cfg.TEST.MODEL_FILE))
model.load_state_dict(torch.load(cfg.TEST.MODEL_FILE), strict=False)
else:
model_state_file = os.path.join(
final_output_dir, 'final_state.pth'
)
logger.info('=> loading model from {}'.format(model_state_file))
model.load_state_dict(torch.load(model_state_file))
model = torch.nn.DataParallel(model, device_ids=cfg.GPUS).cuda()
# define loss function (criterion) and optimizer
criterion = JointsMSELoss(
use_target_weight=cfg.LOSS.USE_TARGET_WEIGHT
).cuda()
# Loading an image
image_file = args.img_file
data_numpy = cv2.imread(image_file, cv2.IMREAD_COLOR | cv2.IMREAD_IGNORE_ORIENTATION)
if data_numpy is None:
logger.error('=> fail to read {}'.format(image_file))
raise ValueError('=> fail to read {}'.format(image_file))
# object detection box
box = [450, 160, 350, 560]
c, s = _box2cs(box, cfg.MODEL.IMAGE_SIZE[0], cfg.MODEL.IMAGE_SIZE[1])
r = 0
trans = get_affine_transform(c, s, r, cfg.MODEL.IMAGE_SIZE)
input = cv2.warpAffine(
data_numpy,
trans,
(int(cfg.MODEL.IMAGE_SIZE[0]), int(cfg.MODEL.IMAGE_SIZE[1])),
flags=cv2.INTER_LINEAR)
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225]),
])
input = transform(input).unsqueeze(0)
# switch to evaluate mode
model.eval()
with torch.no_grad():
# compute output heatmap
output = model(input)
preds, maxvals = get_final_preds(cfg, output.clone().cpu().numpy(), np.asarray([c]), np.asarray([s]))
image = data_numpy.copy()
for mat in preds[0]:
x, y = int(mat[0]), int(mat[1])
cv2.circle(image, (x, y), 2, (255, 0, 0), 2)
# vis result
cv2.imwrite("test_h36m.jpg", image)
cv2.imshow('res', image)
cv2.waitKey(10000)
if __name__ == '__main__':
main()
The command is:
python tools/demo.py --cfg experiments/coco/hrnet/w32_384x288_adam_lr1e-3.yaml --img-file 000002.jpg TEST.MODEL_FILE models/pytorch/pose_coco/pose_hrnet_w32_384x288.pth

@Ixiaohuihuihui Hi, I test imgs use your codes. However the render results is bad. Do you know the reason of this cases? Thanks.
@Ixiaohuihuihui Hi, I test imgs use your codes. However the render results is bad. Do you know the reason of this cases? Thanks.
I don't know the special issuses. But I think maybe we should modify the parameters according to datasets. Which dataset images did you test on?
@lxiaohuihuihui thanks so much for sharing! If I try with Coco data I get perfect results, but not on my own (because they are scaled differently?). Could you maybe explain what scale and pixel_std refer to exactly? I guess this is where it goes wrong. Thanks in advance!
@lxiaohuihuihui thanks so much for sharing! If I try with Coco data I get perfect results, but not on my own (because they are scaled differently?). Could you maybe explain what scale and pixel_std refer to exactly? I guess this is where it goes wrong. Thanks in advance!
Please refer: https://github.com/microsoft/human-pose-estimation.pytorch/issues/26#issuecomment-449536235
Actually, I also don't know how to test in the wild image elegantly, but I guess maybe you can get the parameter by drawing a detection box manually or using fasterrcnn to detect the people. Your image size should be consistent wit the reference image in coco.
I actually use detection bounding boxes from Mask RCNN and with coco data it works, I also checked wether the bboxes are correct and they are. Thanks anyway :)
As mentioned in https://github.com/microsoft/human-pose-estimation.pytorch/issues/26#issuecomment-449536235 the error was due to this line:
c, s = _box2cs(box, data_numpy.shape[0], data_numpy.shape[1])
instead it should be:
c, s = _box2cs(box, data_numpy.shape[1], data_numpy.shape[0])
So image_width and image_height were basically switched. I guess it worked better for Coco data, because the images are a lot more symmetrical than mine.
@leoxiaobin @lxiaohuihuihui @MassyMeniche @jinfagang @wait1988 @njustczr
i have try the inference for a single image. But I don not think the result is good. Is it the problem of
trained model , or my inference code?the result is as follows:


 origin images is as follows:
origin images is as follows:

 I make prediction on pose_hrnet_w32_256x192.pth.
can u run the demo, and show me the result?
I make prediction on pose_hrnet_w32_256x192.pth.
can u run the demo, and show me the result?
@tengshaofeng I'm not getting perfect results on your data either. I used w48_384x288 on your data
I think it's because the joints of your humans are occluded by kinda baggy clothes and pose estimation is very sensitiv to that. But at least for the first picture it should work. It's just like that because my human detector did not work perfectly as you can see.




but for example if I try on random data, where you can see the body parts better it works:


@carlottaruppert , thanks so much for your reply. I think your performance is better than mine. Have u used the operation of fliping when test?
As mentioned in microsoft/human-pose-estimation.pytorch#26 (comment) the error was due to this line:
c, s = _box2cs(box, data_numpy.shape[0], data_numpy.shape[1])
instead it should be:
c, s = _box2cs(box, data_numpy.shape[1], data_numpy.shape[0])
So image_width and image_height were basically switched. I guess it worked better for Coco data, because the images are a lot more symmetrical than mine.
Have you done this? It is essantial. I haven't used flipping in testing, I am using a slightly altered version of the script posted in this issue.
@carlottaruppert ,yes , I try as you said. It performance better. Really thanks for your advice. sorry to bother u again. the follow image is not good, can u try it for me?


I think my result is better... since the picture width and height is basically the size of the bbox I scipped the Mask RCNN and coded the bbox hard. In addition I made sure that this part is commented out: if center[0] != -1: scale = scale * 1.25 because HR Net enlarges the bbox and I didn't want that to happen because then it's bigger than the actual image and this can lead to errors. This could be your error too btw!
This is my result:

I think it's confused by the dress again, so the legs aren't good
@carlottaruppert , when i comment the "if center[0] != -1:
scale = scale * 1.25"
the result is like follows:
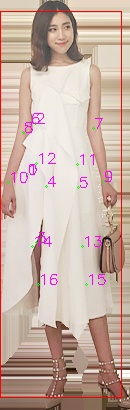 maybe I should try the model of w48_384x288
maybe I should try the model of w48_384x288
@carlottaruppert , when i set the box as large as the image, and I use the w48_384x288,but the result is as follows, I do not know why I can not get your result.
 can u share your inference code with me?
can u share your inference code with me?
from future import absolute_import from future import division from future import print_function import argparse import os import pprint import torch import torch.nn.parallel import torch.backends.cudnn as cudnn import torch.optim import torch.utils.data import torch.utils.data.distributed import torchvision.transforms as transforms import _init_paths from config import cfg from config import update_config from core.loss import JointsMSELoss from core.function import validate, get_final_preds from utils.utils import create_logger from utils.transforms import * import cv2 import dataset import models import numpy as np def parse_args(): parser = argparse.ArgumentParser(description='Train keypoints network') # general parser.add_argument('--cfg', help='experiment configure file name', default='experiments/mpii/hrnet/w32_256x256_adam_lr1e-3.yaml', type=str)
parser.add_argument('opts',
help="Modify config options using the command-line",
default=None,
nargs=argparse.REMAINDER)
parser.add_argument('--img-file',
help='input your test img',
type=str,
default='')
# philly
parser.add_argument('--modelDir',
help='model directory',
type=str,
default='')
parser.add_argument('--logDir',
help='log directory',
type=str,
default='')
parser.add_argument('--dataDir',
help='data directory',
type=str,
default='')
parser.add_argument('--prevModelDir',
help='prev Model directory',
type=str,
default='')
args = parser.parse_args()
return args
def _box2cs(box, image_width, image_height): x, y, w, h = box[:4] return _xywh2cs(x, y, w, h, image_width, image_height)
def _xywh2cs(x, y, w, h, image_width, image_height): center = np.zeros((2), dtype=np.float32) center[0] = x + w * 0.5 center[1] = y + h * 0.5
aspect_ratio = image_width * 1.0 / image_height
pixel_std = 200
if w > aspect_ratio * h:
h = w * 1.0 / aspect_ratio
elif w < aspect_ratio * h:
w = h * aspect_ratio
scale = np.array(
[w * 1.0 / pixel_std, h * 1.0 / pixel_std],
dtype=np.float32)
# if center[0] != -1:
# scale = scale * 1.25
return center, scale
def main(): args = parse_args() update_config(cfg, args)
logger, final_output_dir, tb_log_dir = create_logger(
cfg, args.cfg, 'valid')
logger.info(pprint.pformat(args))
logger.info(cfg)
# cudnn related setting
cudnn.benchmark = cfg.CUDNN.BENCHMARK
torch.backends.cudnn.deterministic = cfg.CUDNN.DETERMINISTIC
torch.backends.cudnn.enabled = cfg.CUDNN.ENABLED
model = eval('models.'+cfg.MODEL.NAME+'.get_pose_net')(
cfg, is_train=False
)
if cfg.TEST.MODEL_FILE:
logger.info('=> loading model from {}'.format(cfg.TEST.MODEL_FILE))
model.load_state_dict(torch.load(cfg.TEST.MODEL_FILE), strict=False)
else:
model_state_file = os.path.join(
final_output_dir, 'final_state.pth'
)
logger.info('=> loading model from {}'.format(model_state_file))
model.load_state_dict(torch.load(model_state_file))
model = torch.nn.DataParallel(model, device_ids=[0]).cuda()
# define loss function (criterion) and optimizer
criterion = JointsMSELoss(
use_target_weight=cfg.LOSS.USE_TARGET_WEIGHT
).cuda()
# Loading an image
image_file = args.img_file
data_numpy = cv2.imread(image_file, cv2.IMREAD_COLOR | cv2.IMREAD_IGNORE_ORIENTATION)
if data_numpy is None:
logger.error('=> fail to read {}'.format(image_file))
raise ValueError('=> fail to read {}'.format(image_file))
# object detection box
box = [0, 0, data_numpy.shape[0], data_numpy.shape[1]]
c, s = _box2cs(box, data_numpy.shape[1], data_numpy.shape[0])
r = 0
trans = get_affine_transform(c, s, r, cfg.MODEL.IMAGE_SIZE)
input = cv2.warpAffine(
data_numpy,
trans,
(int(cfg.MODEL.IMAGE_SIZE[0]), int(cfg.MODEL.IMAGE_SIZE[1])),
flags=cv2.INTER_LINEAR)
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225]),
])
input = transform(input).unsqueeze(0)
# switch to evaluate mode
model.eval()
with torch.no_grad():
# compute output heatmap
output = model(input)
preds, maxvals = get_final_preds(cfg, output.clone().cpu().numpy(), np.asarray([c]), np.asarray([s]))
image = data_numpy.copy()
for mat in preds[0]:
x, y = int(mat[0]), int(mat[1])
cv2.circle(image, (x, y), 2, (255, 0, 0), 2)
# vis result
cv2.imwrite("test_h36m.jpg", image)
cv2.imshow('res', image)
cv2.waitKey(10000)
if name == 'main': main()
Maybe your box format is not as it should be (x, y, width, height)? This is the version without the Mask RCNN annotation reading.
and I'm calling it like this: python /tools/demo.py --cfg /experiments/coco/hrnet/w48_384x288_adam_lr1e-3.yaml --img-file 1.jpg TEST.MODEL_FILE /models/pytorch/pose_coco/pose_hrnet_w48_384x288.pth
if you are using Mask RCNN as well, change the bbox format with this function:
def change_box_to_coco_format(mask_box): """mask rcnn box structure looks as follows: y1,x1,y2,x2 where y1,x1 refer to the left upper coordinates and y2,x2 to the right lower coordinates of the bbox. coco however expects boxes in this format: x,y, width, height where x, y, refers to the left upper coordinates of the bbox."""
coco_box = [0,0,0,0]
coco_box[0]=mask_box[1]
coco_box[1]=mask_box[0]
coco_box[2]= mask_box[3]-mask_box[1]
coco_box[3]= mask_box[2]-mask_box[0]
return coco_box
@carlottaruppert , I found the problem. because of the bbox, my bbox is [0, 0, 130, 410], yours is
[0, 0, 410, 130 ], the input image' width is 130, height is 410. as u said "Maybe your box format is not as it should be (x, y, width, height)" , i think your box is wrong, but I don't know why with your box the key points is right.
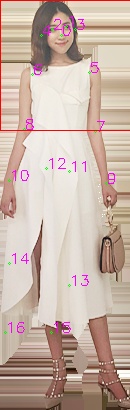
@carlottaruppert , I have found the solution after I read the code carefully. Actually,it shoud be: c, s = _box2cs(box, cfg.MODEL.IMAGE_SIZE[0], cfg.MODEL.IMAGE_SIZE[1]) instead of: c, s = _box2cs(box, data_numpy.shape[1], data_numpy.shape[0])
now, every thing is ok.

