PHP正则表达式,断言结束或断言行尾,的疑问
场景
元字符 $ 无法正确的断言结束或者行尾。
正常情况
首先,在单行模式下面。
^ 与 $ 只匹配整个字符串的开始和结束,而不会管实际你的字符串有多少行。
$subject = <<<'EOT'
FN:John Doe
VERSION:3.0
ORG:Example.com Inc
N:Doe;John;;;
FN:John Doe
VERSION:3.0
ORG:Example.com Inc
EOT;
// 企图匹配 `FN:John Doe` 中的 `FN`
// 字符串中包含两个,但结果中只有一个 FN 的匹配
preg_match_all('/^FN:/', $subject, $matchA);
// 企图匹配 `ORG:Example.com Inc` 中的 `Inc`
// 字符串中包含两个,但结果中只有一个 `Inc` 的匹配
preg_match_all('/Inc$/', $subject, $matchB);
// 企图匹配 `VERSION:3.0` 中的 `VERSION:`
// 字符串中包含两个,但没有匹配到任何结果
preg_match_all('/^VERSION:/', $subject, $matchC);
// 企图匹配 `VERSION:3.0` 中的 `3.0`
// 字符串中包含两个,但没有匹配到任何结果
preg_match_all('/3\.0$/', $subject, $matchD);
以上示例都是采用的单行模式去匹配,并且都采用了 preg_match_all 而不是 preg_match。
示例的结果,证实了单行模式下面 ^ 和 $ 分别对应整个字符串的开始和结束。
而不是字符串中某一行的开始和结束。
// 启用多行模式修饰符 `m`,对 `3.0` 进行匹配
// 字符串中包含两个,结果中也包含两个结果
preg_match_all('/3\.0$/m', $subject, $matchD);
非正常情况
你的结果真的能如上面所说的那样子吗? 答案是,有的可以,有的不行。
关于 ^ 和 $ 在 PHP 官方文档上说的很模糊,如下截图
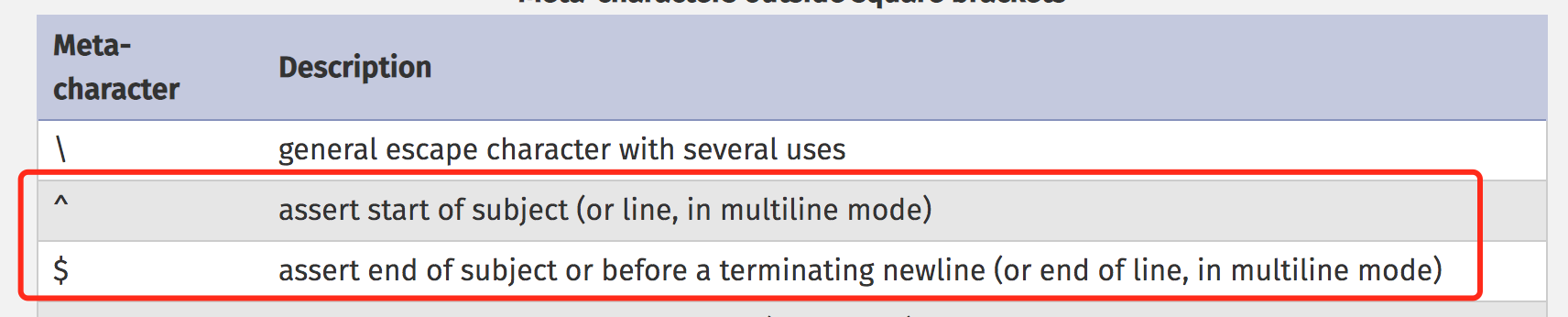 ^ - 断言目标的开始位置(或在多行模式下是行首)
$ - 断言目标的结束位置(或在多行模式下是行尾)
^ - 断言目标的开始位置(或在多行模式下是行首)
$ - 断言目标的结束位置(或在多行模式下是行尾)
好像看起来就是那么回事,但是实际应用中却不是这样,时灵时不灵的。 这主要是受操作系统换行符的影响,windows、 Linux、 OSX 各自一套玩法。
// - Windows uses CR+LF (\r\n);
// - Linux LF (\n);
// - OSX CR (\r).
如上,有个是 \r 有的是 \n 有的又是 \r\n。
然后,也不知搞 PHP 的这一群人是怎么写 PCRE 的。
反正现在的结果就是,我用的 PHP 7.2.x 了,$ 还是有这个匹配行尾失败的问题。
而且,之前的版本也一直有这个问题。

解决方案
一个在 PHP 官方文档的转义序列中貌似没有提到的玩意。
叫做 \R 的转义字符。用这个东西来替代 $ 的位置。
// 启用多行模式修饰符 `m`,对 `3.0` 进行匹配
// 字符串中包含两个,结果中也包含两个结果
preg_match_all('/3\.0\R/m', $subject, $matchD);
后续传说
有些人说这个东西也不能保证百分百成功。 所以断言结束以及断言行尾什么的,自求多福吧。WTF!!!
当然,不怕麻烦的。 也可以先把换行符替换一遍,转换成同一种风格的,再跑正则匹配。
补充说明
关于上面 “后续传说” 中,\R 失效的原因已找到。
首先,如果 \R 出现在 8-bit 的 non-UTF-8 模式 的 非字符集合 时,
相当于下面的表达式
$pattern = "(?>\r\n|\n|\x0b|\f|\r|\x85)";
也就是说这个时候,它能够匹配正确的匹配到 CR, LF, CRLF。但是其他情形下面就会失效。
比如,出现在字符集合中时,\R 和 R 的效果相同。
$pattern = "[0-9\R]"; // 等同于 [0-9R]
