Stata displays #chars per line by bytes, not number of characters
Problem description
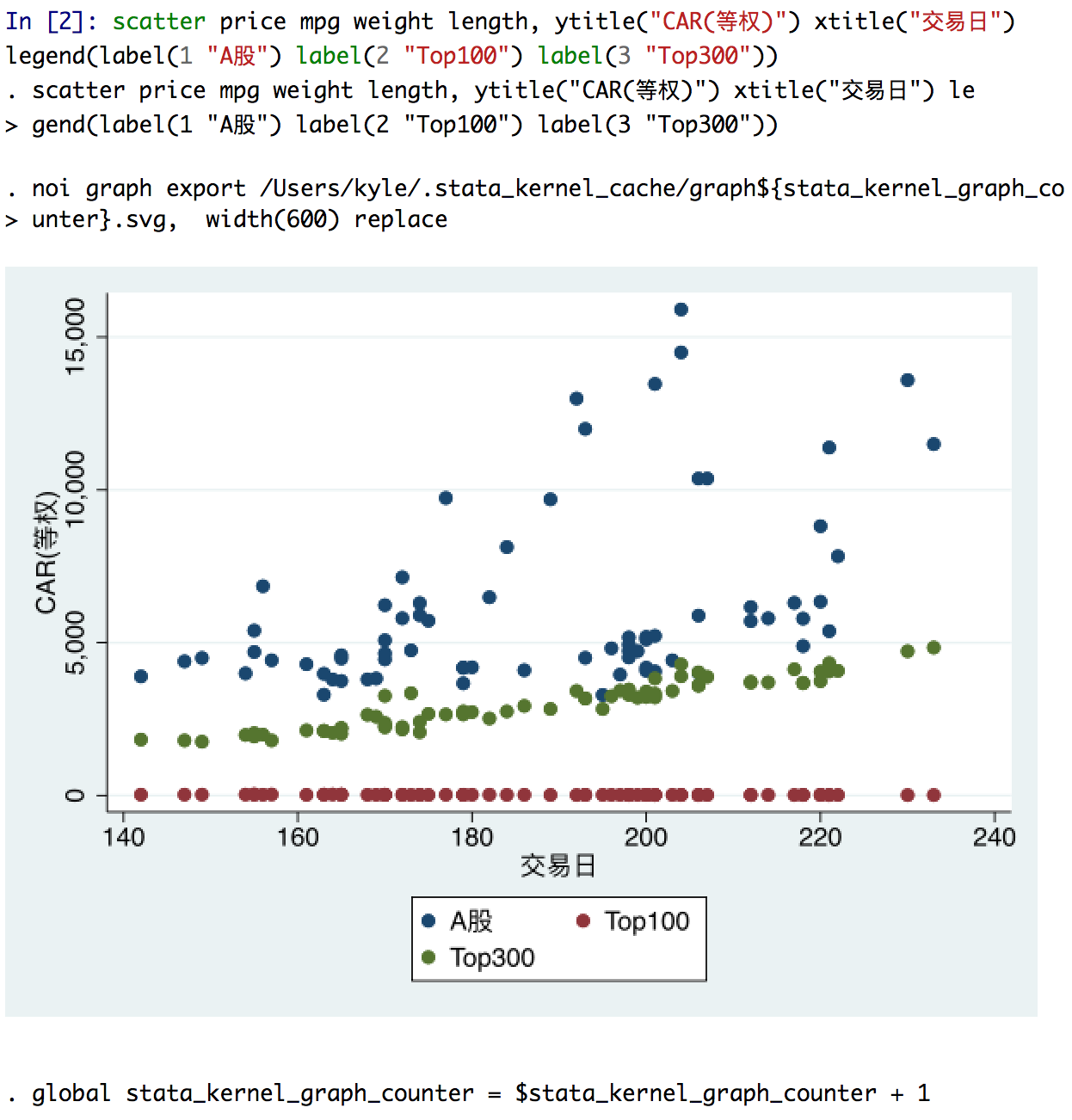
Related to #161, every (?) unicode non-ascii character printed in the console is defined by more than one byte. So with 5 Chinese characters, Stata displays 75 characters, not 80.


This messes up hiding code lines.
Possible fixes
I could try to count the number of multi-byte characters that I send to Stata, and modify what string I expect to see returned from Stata
Take the following text:
line mcar car100 car300 trddt, ytitle("CAR(等权)") xtitle("交易日") legend(label
With Stata, the unicode string length is 75, while the unicode display string length is 80. The udstrlen is what Stata must use to determine how many characters to display on a line.

Apparently CJK characters need two display columns:

Python library that measures the width of unicode strings rendered to a terminal: https://github.com/jquast/wcwidth