Simplify load test
With migration to CL2 being roughly done, I would like to simplify and evolve load test a bit to:
- create a service in a bundle with RC
- that creates a problem that we currently have a service only for half of RCs, but fortunately in new enough releases we can solve that by using the mechanism introduced here: https://github.com/kubernetes/kubernetes/pull/71355
- switch to using Deployment instead of RC
/assign @krzysied
The problem I see here is that running this simplified load test for older k8s versions will not work. I think we need to split tests into legacy/ head/. This change will also be required when we switch to new api responsiveness metric. Wdyt?
- [x] Creating legacy and head directories with copies of test configs #450
- [x] Changing scalability jobs config
- [x] Removing all test configs
I'm fine with legacy/ and head/ for other reasons (e.g. responsiveness metric).
But I don't understand why you need it for the purpose of this issue?
IIUC we want to use kubernetes/kubernetes#71355 which will not be available for older k8s version, right?
Ahh - that's what you meant. Yeah, though given that we only run older releases on 100-node tests, even if that would have no effect, it should still be fine...
Actually, I think that PR that was submitted wasn't exactly what we want. We should create head/ and legacy/ subdirectories within individual tests, as needed.
Or rather, I would say we should even go one step further:
- create a legacy/ directory (within tests that we need to modify, so probably both actually)
- migrate old branches to use configs from that directory
- leave everything else as is Once this is done, we may start modifying the current configs.
Point (2) from original description is mostly done in #488
However, as discussed offline with @krzysied while this fixes kube-proxy issues, it still leads to much higher resource usage of DNS which leads to OOMs. So in order to make this change, we would need to adjust DNS resource limits based on size of the cluster somehow.
So the remaining stuff to do is:
- adjust DNS resource limits
- bundle service together with RC
- switch from RC to Deployment
With https://github.com/kubernetes/kubernetes/pull/77918 adjusting DNS resource limits will be possible.
@krzysied - once we get out of regressions, it's an important thing to look at.
@mm4tt - you did a part of it (which is switching to deployments).
Would you mind taking the other parts to (adjust dns limits and bundle service together with Deployment)? [that would make it clear other bundling later too, like secrets or configmaps]
/assign @mm4tt
I've run the experimental load config on 5K node cluster over weekend. Some observations below
-
CoreDNS memory went up (expected, as we have more services): Baseline
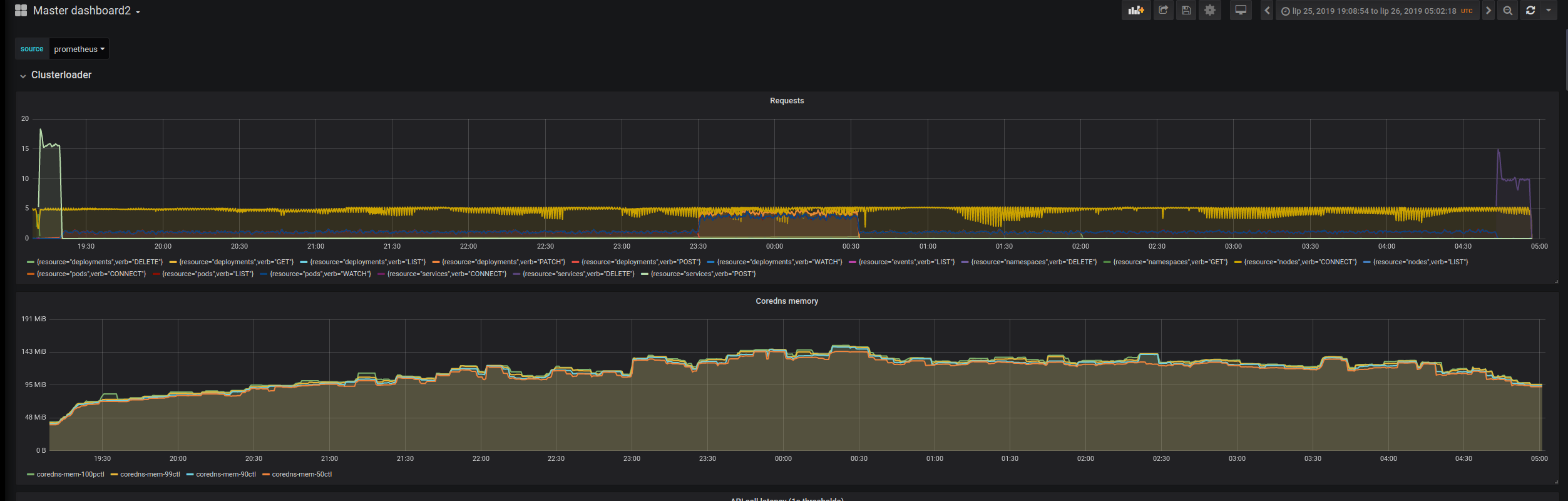 Simplified Load
Simplified Load
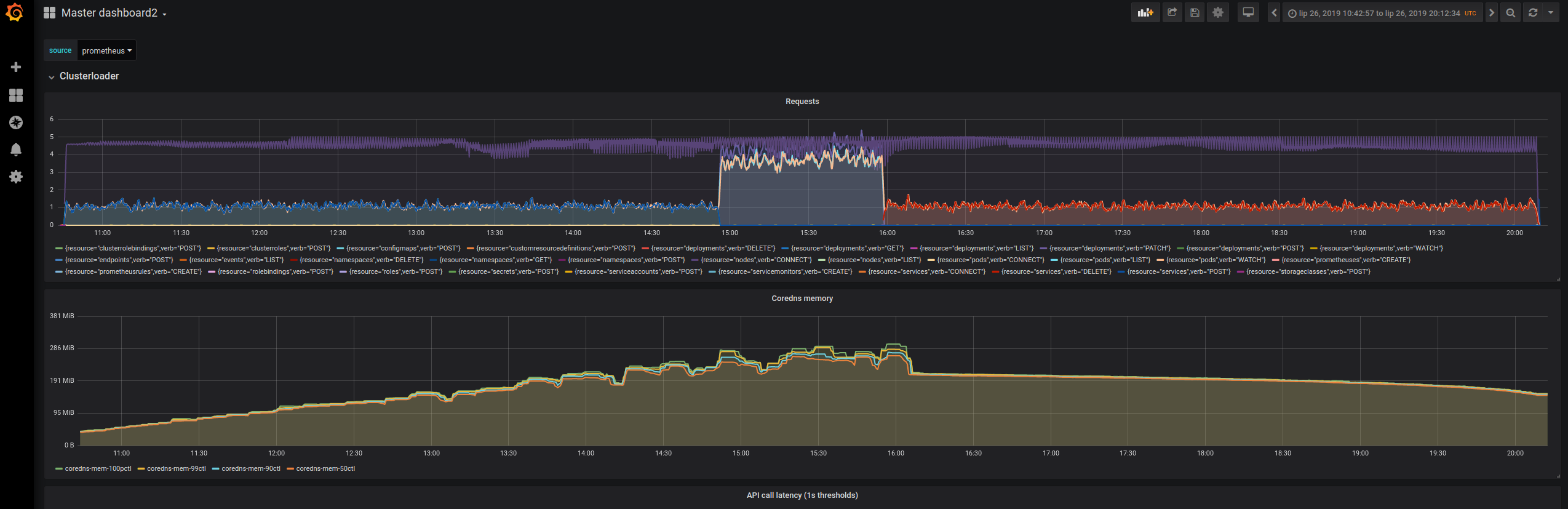
-
Network traffic went significantly down during delete deployment phase (expected, as we send much less endpoints objects updates due to the fact that services are deleted together with deployments), it also made the api-server cpu usage visibly less spiky Baseline
 Simplified Load
Simplified Load
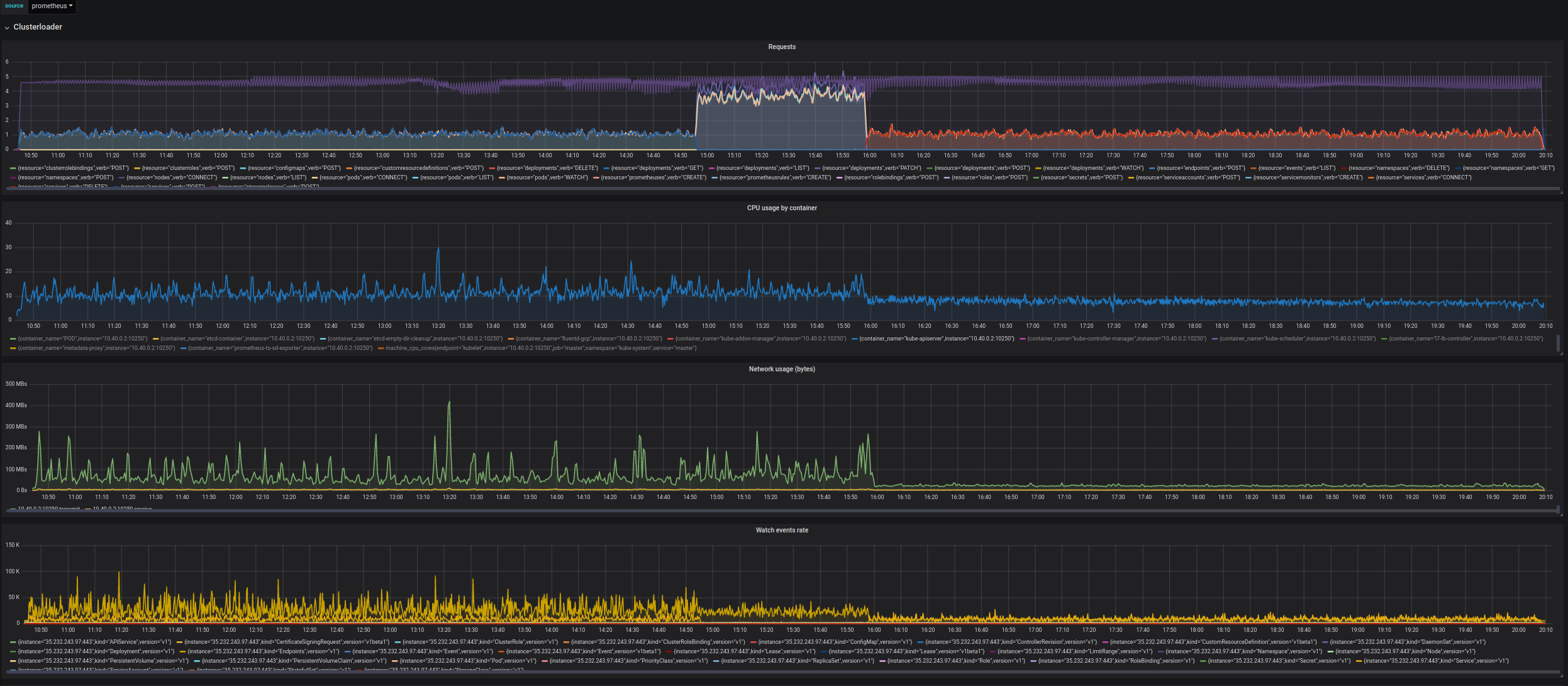
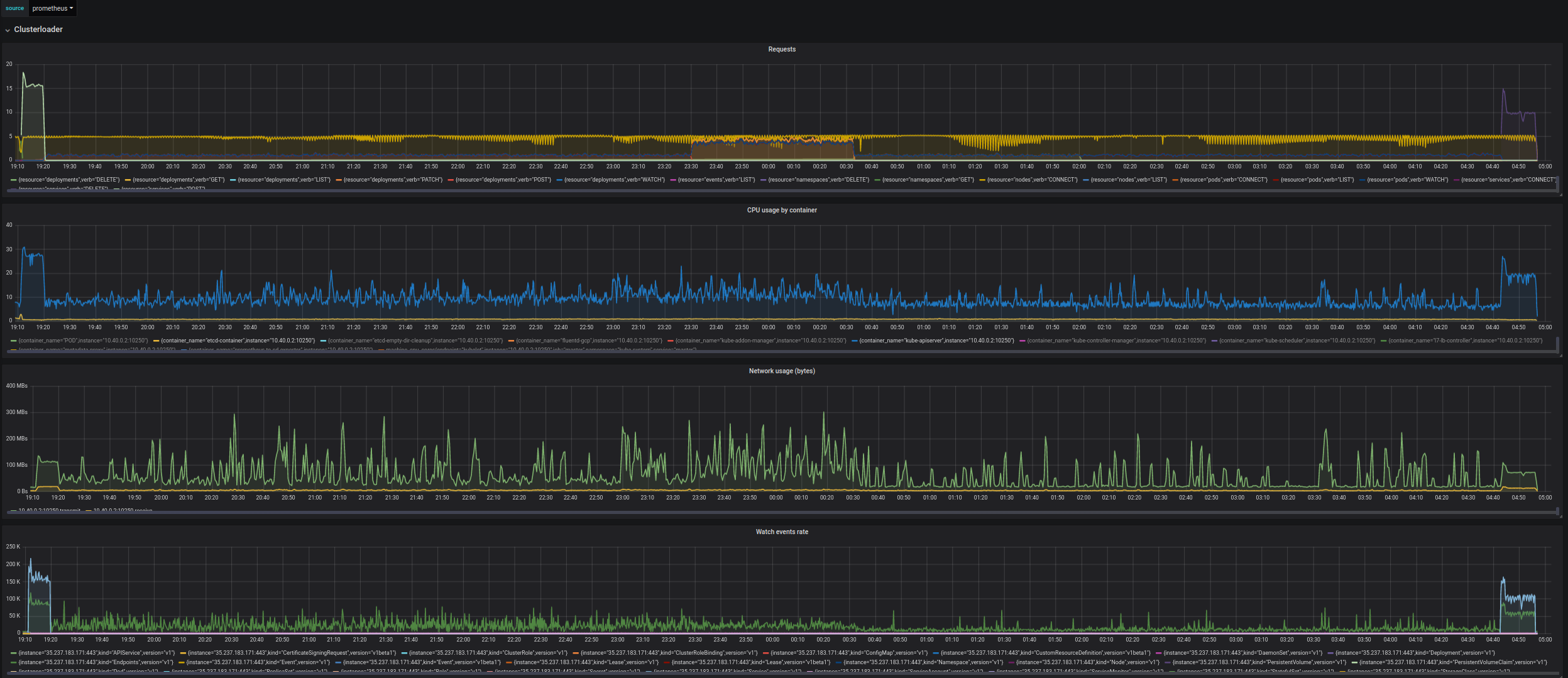
- API Call Latency SLI of POST/DELETE Services went significantly up (and it's considered a blocker for enabling simplified load in the current form). The increase in latency seems to be coming from etcd, it looks like it's getting overloaded (which may be related to https://github.com/kubernetes/kubernetes/issues/80209), in the experimental run the latency of operations is much higher than in the baseline where services are created before/after deployments (and load on etcd is much lower).
The important thing is that Service objects are unique in k8s, creating/deleting them requires 3 etcd writes (Service and two RangeAllocators). Increase in etcd latency is very strongly reflected in api call latency for Services.
Overall it ruins the Api-Call-Latency SLO for DELETE (both prometheus and old measurement) and POST (old measurement seems fine, but prometheus is above 1s).
Baseline
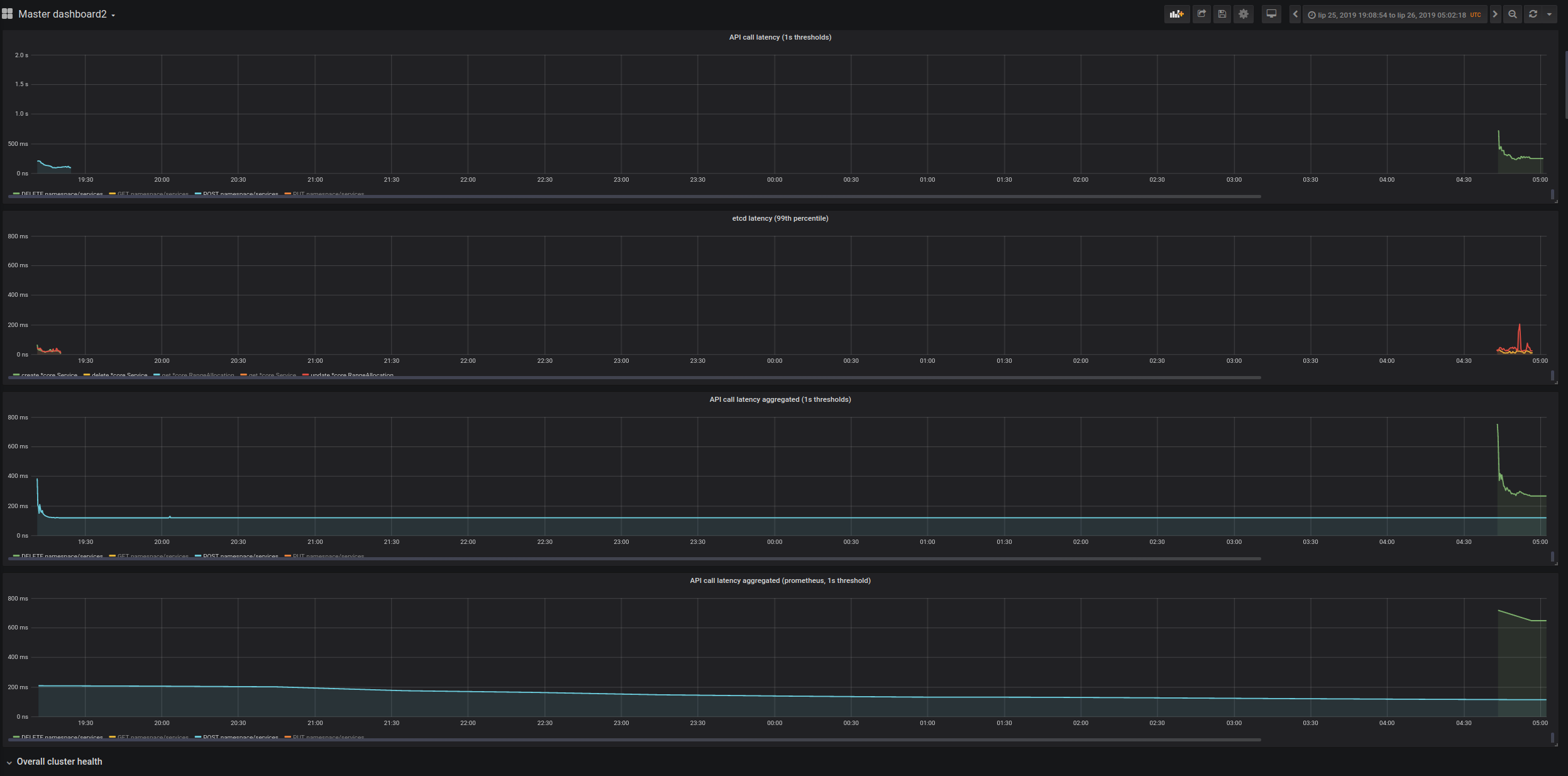 Simplified Load
Simplified Load
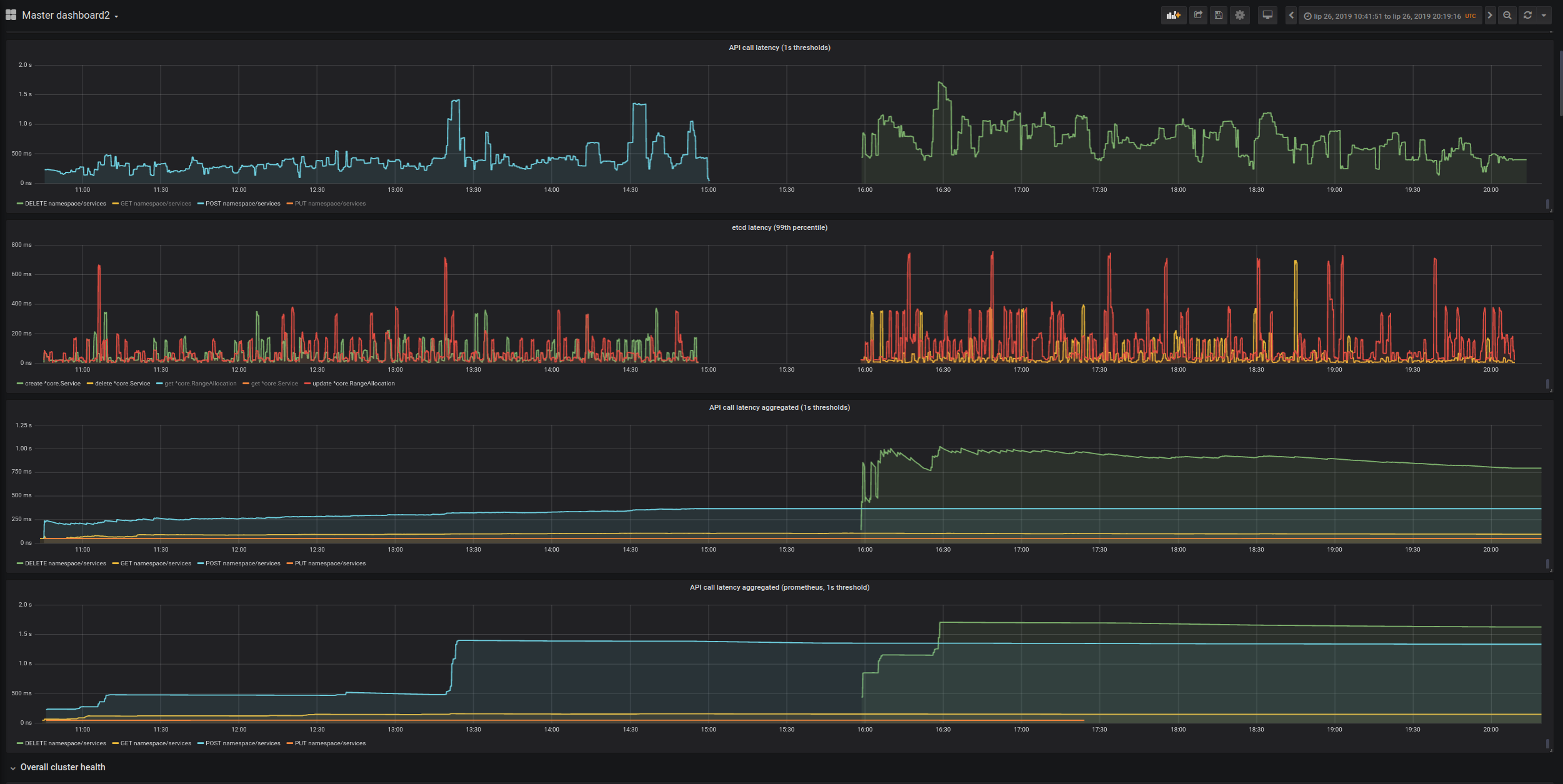
Given 3, this is currently blocked. We can get back to it once etcd performance gets improved (e.g. https://github.com/kubernetes/kubernetes/issues/80209 gets fixed).
Issues go stale after 90d of inactivity.
Mark the issue as fresh with /remove-lifecycle stale.
Stale issues rot after an additional 30d of inactivity and eventually close.
If this issue is safe to close now please do so with /close.
Send feedback to sig-testing, kubernetes/test-infra and/or fejta. /lifecycle stale