kubectl shows incorrect memory information
What happened: I have a go web application. The application is deployed in the k8s cluster and when I'm stressing the app I do see the following numbers:
kubectl top pod repolite-5f9f6bb846-tx6mj --containers
Mon Apr 4 16:06:47 2022
POD NAME CPU(cores) MEMORY(bytes)
repolite-5f9f6bb846-tx6mj repolite 704m 1545Mi
repolite-5f9f6bb846-tx6mj stash 3m 86Mi
repolite-5f9f6bb846-tx6mj vault-agent 1m 19Mi
What you expected to happen:
After stress tests, I have a slight memory consumption in the app:
│ gc 18 @2014.334s 0%: 0.15+0.98+0.005 ms clock, 1.2+0.24/0.63/0.41+0.043 ms cpu, 2->2->1 MB, 4 MB goal, 8 P
Here is a top output:
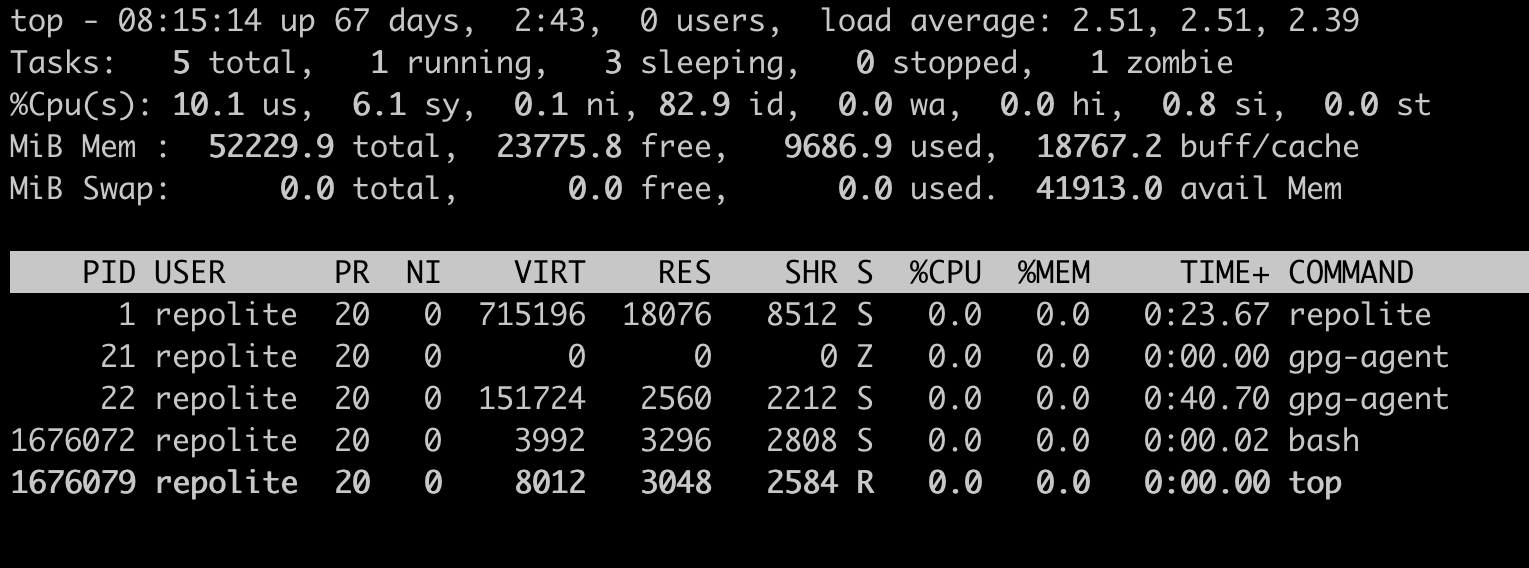
But I still see something around 1.5 GB of memory in use. It confused me a lot. I expected to see something like
MEMORY = (RSS + SHR) * process amount
How to reproduce it (as minimally and precisely as possible):
Anything else we need to know?:
it might be important, under the hood it executes shell script via exec package, I've double checked - I'm waiting for all script executions.
In general, not sure if that is a bug of kubectl, but just want to be sure.
Environment:
- Kubernetes client and server versions (use
kubectl version):
~ k version
Client Version: version.Info{Major:"1", Minor:"23", GitVersion:"v1.23.4", GitCommit:"e6c093d87ea4cbb530a7b2ae91e54c0842d8308a", GitTreeState:"clean", BuildDate:"2022-02-16T12:30:48Z", GoVersion:"go1.17.6", Compiler:"gc", Platform:"darwin/amd64"}
Server Version: version.Info{Major:"1", Minor:"21", GitVersion:"v1.21.6-gke.1503", GitCommit:"2c7bbda09a9b7ca78db230e099cf90fe901d3df8", GitTreeState:"clean", BuildDate:"2022-02-18T03:17:45Z", GoVersion:"go1.16.9b7", Compiler:"gc", Platform:"linux/amd64"}
- Cloud provider or hardware configuration: GKE
- OS (e.g:
cat /etc/os-release): I have no node access :(
Appreciate your time while reading it and thank you in advance for any suggestion.
@ep4sh: This issue is currently awaiting triage.
SIG CLI takes a lead on issue triage for this repo, but any Kubernetes member can accept issues by applying the triage/accepted label.
The triage/accepted label can be added by org members by writing /triage accepted in a comment.
Instructions for interacting with me using PR comments are available here. If you have questions or suggestions related to my behavior, please file an issue against the kubernetes/test-infra repository.
The Kubernetes project currently lacks enough contributors to adequately respond to all issues and PRs.
This bot triages issues and PRs according to the following rules:
- After 90d of inactivity,
lifecycle/staleis applied - After 30d of inactivity since
lifecycle/stalewas applied,lifecycle/rottenis applied - After 30d of inactivity since
lifecycle/rottenwas applied, the issue is closed
You can:
- Mark this issue or PR as fresh with
/remove-lifecycle stale - Mark this issue or PR as rotten with
/lifecycle rotten - Close this issue or PR with
/close - Offer to help out with Issue Triage
Please send feedback to sig-contributor-experience at kubernetes/community.
/lifecycle stale
The Kubernetes project currently lacks enough active contributors to adequately respond to all issues and PRs.
This bot triages issues and PRs according to the following rules:
- After 90d of inactivity,
lifecycle/staleis applied - After 30d of inactivity since
lifecycle/stalewas applied,lifecycle/rottenis applied - After 30d of inactivity since
lifecycle/rottenwas applied, the issue is closed
You can:
- Mark this issue or PR as fresh with
/remove-lifecycle rotten - Close this issue or PR with
/close - Offer to help out with Issue Triage
Please send feedback to sig-contributor-experience at kubernetes/community.
/lifecycle rotten
The Kubernetes project currently lacks enough active contributors to adequately respond to all issues and PRs.
This bot triages issues according to the following rules:
- After 90d of inactivity,
lifecycle/staleis applied - After 30d of inactivity since
lifecycle/stalewas applied,lifecycle/rottenis applied - After 30d of inactivity since
lifecycle/rottenwas applied, the issue is closed
You can:
- Reopen this issue with
/reopen - Mark this issue as fresh with
/remove-lifecycle rotten - Offer to help out with Issue Triage
Please send feedback to sig-contributor-experience at kubernetes/community.
/close not-planned
@k8s-triage-robot: Closing this issue, marking it as "Not Planned".
In response to this:
The Kubernetes project currently lacks enough active contributors to adequately respond to all issues and PRs.
This bot triages issues according to the following rules:
- After 90d of inactivity,
lifecycle/staleis applied- After 30d of inactivity since
lifecycle/stalewas applied,lifecycle/rottenis applied- After 30d of inactivity since
lifecycle/rottenwas applied, the issue is closedYou can:
- Reopen this issue with
/reopen- Mark this issue as fresh with
/remove-lifecycle rotten- Offer to help out with Issue Triage
Please send feedback to sig-contributor-experience at kubernetes/community.
/close not-planned
Instructions for interacting with me using PR comments are available here. If you have questions or suggestions related to my behavior, please file an issue against the kubernetes/test-infra repository.