kops
 kops copied to clipboard
kops copied to clipboard
Removed force_tcp flag from node template.
This aimed to remove leftovers of the fix from https://github.com/kubernetes/kops/pull/9917
Welcome @dene14!
It looks like this is your first PR to kubernetes/kops 🎉. Please refer to our pull request process documentation to help your PR have a smooth ride to approval.
You will be prompted by a bot to use commands during the review process. Do not be afraid to follow the prompts! It is okay to experiment. Here is the bot commands documentation.
You can also check if kubernetes/kops has its own contribution guidelines.
You may want to refer to our testing guide if you run into trouble with your tests not passing.
If you are having difficulty getting your pull request seen, please follow the recommended escalation practices. Also, for tips and tricks in the contribution process you may want to read the Kubernetes contributor cheat sheet. We want to make sure your contribution gets all the attention it needs!
Thank you, and welcome to Kubernetes. :smiley:
Hi @dene14. Thanks for your PR.
I'm waiting for a kubernetes member to verify that this patch is reasonable to test. If it is, they should reply with /ok-to-test on its own line. Until that is done, I will not automatically test new commits in this PR, but the usual testing commands by org members will still work. Regular contributors should join the org to skip this step.
Once the patch is verified, the new status will be reflected by the ok-to-test label.
I understand the commands that are listed here.
Instructions for interacting with me using PR comments are available here. If you have questions or suggestions related to my behavior, please file an issue against the kubernetes/test-infra repository.
[APPROVALNOTIFIER] This PR is NOT APPROVED
This pull-request has been approved by:
Once this PR has been reviewed and has the lgtm label, please assign mikesplain for approval by writing /assign @mikesplain in a comment. For more information see:The Kubernetes Code Review Process.
The full list of commands accepted by this bot can be found here.
Approvers can indicate their approval by writing /approve in a comment
Approvers can cancel approval by writing /approve cancel in a comment
@hakman @olemarkus
force_tcp is questionable solution in general, it makes all requests (even those were done with UDP on client side) initiated in TCP.
As per DNS RFC, TCP should be used only in certain situations, e.g. when DNS payload is too big (usually more than 512 bytes), since it's a subject of IP packet fragmentation, requester may not be able to receive response and have to retry in TCP mode.
TCP mode is a last resort attempt to resolve something, it's slower (due to 3-way TCP handshake initiation).
For AWS it's even more critical, because in-VPC resolvers by AWS don't work well with TCP, and their support team recommends to use UDP instead. In particular we may be hitting AWS resolver packet limit: https://aws.amazon.com/premiumsupport/knowledge-center/vpc-find-cause-of-failed-dns-queries/ with UDP two-way packet limit will end up with ~512 resolves per second, with TCP it will be less than 256...
And again, I expect that coredns follows RFC standard and initiates TCP connection whenever applicable, I'm not asking to do something like prefer_udp (yes, there also such option). I just want resolver to work as it should according to RFC, reduce pressure of AWS per-instance throttling and increased resolve times caused by TCP-mode.
Right now after each cluster update, kops overrides my local changes (there is no way to modify this flag other than completely override coreDNS configuration block) and reverts everything back to TCP. There is how dashboard looks like after force_tcp flag has been set up again:
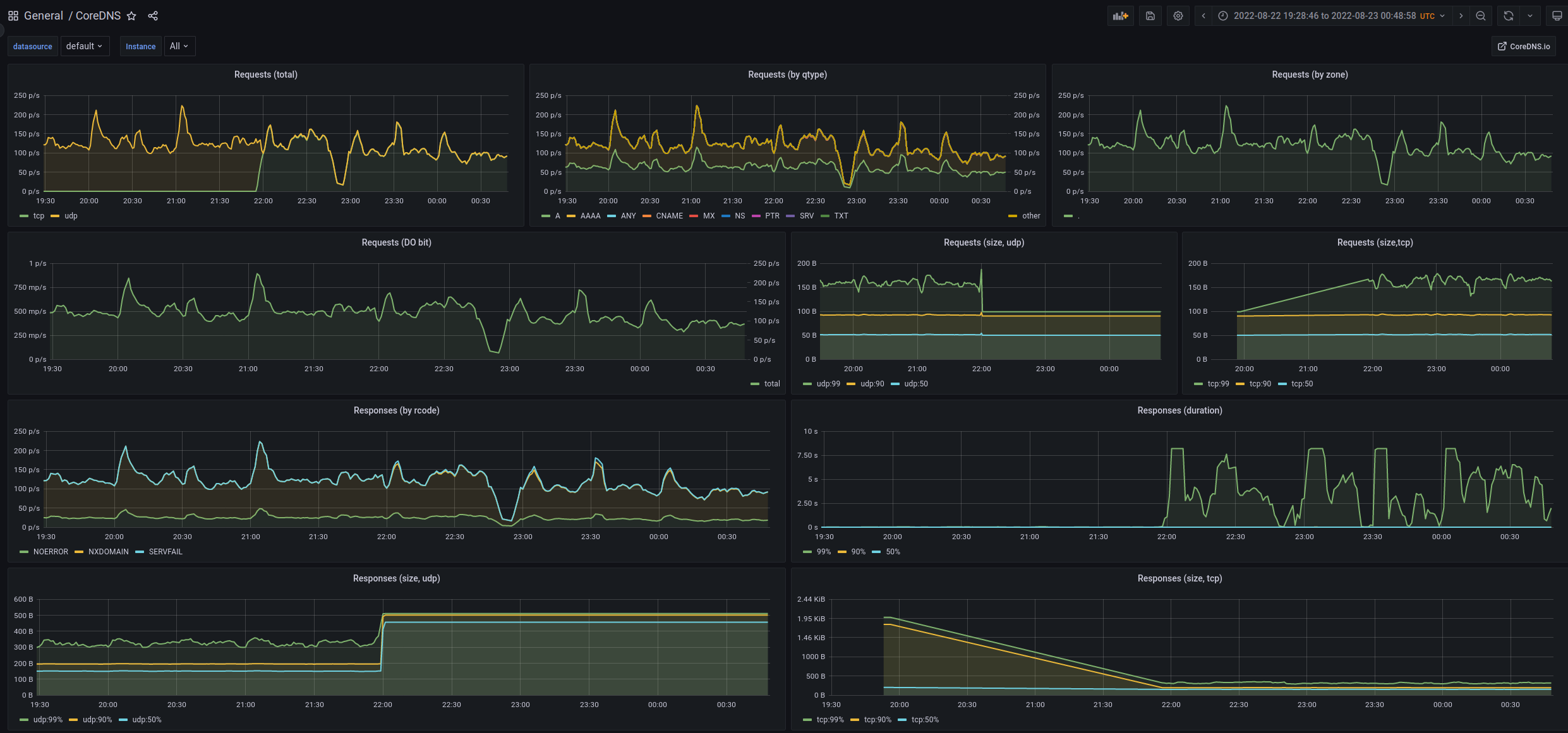
For anyone who advocate for force_tcp I would recommend install metrics collection and also check logs of coreDNS in AWS environment for timeouts. Any meaningful reasoning for force_tcp flag would be also highly appreciated.
I don't know about the reasoning for force_tcp flag in upstream repo (once again, it violates RFC), but for AWS environments (where probably 95% of Kops installations used) it causing problems...
Rancher: https://github.com/rancher/rancher/issues/32180
Another article about increased latency due to force_tcp: https://build.thebeat.co/yet-another-kubernetes-dns-latency-story-2a1c00ebbb8d
This doesn't sound quite right.
The force_tcp flag is only between the dns cache and kubedns (cordedns). If you see DNS queries over TCP going to AWS then that is coming from elsewhere.
By default, dnscache also sends out-of-cluster traffic to upstream (i.e AWS resolvers), but that is handled by this section:
}
.:53 {
errors
cache 30
reload
loop
bind {{ KubeDNS.NodeLocalDNS.LocalIP }}
forward . __PILLAR__UPSTREAM__SERVERS__
prometheus :9253
{{- if IsIPv6Only }}
dns64
{{- end }}
}
No force_tcp there. This part was fixed by https://github.com/kubernetes/kops/pull/9917,
@olemarkus this is actually right and expected... local_cache forcefully uses TCP to send queries to KubeDNS (CoreDNS in my case). KubeDNS configured w/o force_tcp but it behaves according to RFC, since client query came in TCP it relays it to upstream (AWS resolver) in TCP, to alleviate that we have to set prefer_udp on KubeDNS, so that regardless of incoming connection we first try with UDP and if it fails then retry in TCP. And again RFC is pretty clear about how DNS infrastructure should work. If there is no strong reason behind force_tcp then it shouldn't be set. Otherwise it creates absolute nonsense behavior and configuration that violates DNS RFC in the roots.
This is what I have in my local_cache configmap after recent cluster update (kops-1.24.1), I don't override this configuration anywhere and force_tcp was defaulted:
$ kubectl --context prod.dbcc.local -n kube-system get cm -o yaml node-local-dns
apiVersion: v1
data:
Corefile: |-
cluster.local:53 {
errors
cache {
success 9984 30
denial 9984 5
}
reload
loop
bind 169.254.20.10
forward . __PILLAR__CLUSTER__DNS__ {
force_tcp
}
prometheus :9253
health 169.254.20.10:3989
}
.:53 {
errors
cache 30
reload
loop
bind 169.254.20.10
forward . __PILLAR__CLUSTER__DNS__ {
force_tcp
}
prometheus :9253
}
So you are setting kubeDNS.nodeLocalDNS.forwardToKubeDNS: true?
The reason for using forece_tcp, if I remember correctly` is that it greatly offloads connection tracking in kube-proxy. Instead of tracking a significant amount of UDP packets, it can track a few TCP connections.
The 1.24 configmap after a 1.23 -> 1.24 upgrade can be found here: https://storage.googleapis.com/kubernetes-jenkins/logs/e2e-kops-aws-upgrade-k123-ko123-to-k124-ko124-many-addons/1562102772201951232/artifacts/cluster-info/kube-system/configmaps.yaml
As far as I can tell from the history, the configmap has never looked like yours.
@olemarkus this is the diff that I'm getting if I set forwardToKubeDNS: false:
ManagedFile/dev.liveintent.local-addons-nodelocaldns.addons.k8s.io-k8s-1.12
Contents
...
health 169.254.20.10:3989
}
+ in-addr.arpa:53 {
- .:53 {
errors
cache 30
...
prometheus :9253
}
+ ip6.arpa:53 {
+ errors
+ cache 30
+ reload
+ loop
+ bind 169.254.20.10
+ forward . __PILLAR__CLUSTER__DNS__ {
+ force_tcp
+ }
+ prometheus :9253
+ }
+ .:53 {
+ errors
+ cache 30
+ reload
+ loop
+ bind 169.254.20.10
+ forward . __PILLAR__UPSTREAM__SERVERS__
+ prometheus :9253
+ }
kind: ConfigMap
metadata:
...
@dene14: The following test failed, say /retest to rerun all failed tests or /retest-required to rerun all mandatory failed tests:
| Test name | Commit | Details | Required | Rerun command |
|---|---|---|---|---|
| pull-kops-e2e-aws-karpenter | 8a331061f9f39b05a0ee0b567c76ab1df4609be2 | link | true | /test pull-kops-e2e-aws-karpenter |
Full PR test history. Your PR dashboard. Please help us cut down on flakes by linking to an open issue when you hit one in your PR.
Instructions for interacting with me using PR comments are available here. If you have questions or suggestions related to my behavior, please file an issue against the kubernetes/test-infra repository. I understand the commands that are listed here.
Thanks for the PR and the discussions. I think this is the wrong place to discuss the optimisations of using TCP with known-good resolvers (i.e the kube-dns service). If upstream changes their preferences, we will almost certainly follow them, so I suggest trying to send the analog of this PR there.
A PR that adds prefer_udp to the primary nameservers may be interesting though.
/close
@olemarkus: Closed this PR.
In response to this:
Thanks for the PR and the discussions. I think this is the wrong place to discuss the optimisations of using TCP with known-good resolvers (i.e the kube-dns service). If upstream changes their preferences, we will almost certainly follow them, so I suggest trying to send the analog of this PR there.
A PR that adds
prefer_udpto the primary nameservers may be interesting though./close
Instructions for interacting with me using PR comments are available here. If you have questions or suggestions related to my behavior, please file an issue against the kubernetes/test-infra repository.
If upstream changes their preferences, we will almost certainly follow them
@olemarkus I think guys in upstream made it quite clear, that code that you were referring to in upstream repo is deprecated, not going to be maintained and not used anywhere in k8s itself. Whereas kops use that actively, more over provides feature of routing queries from node-local-cache to kubeDns, which is broken right now.
Maybe you can point to some references. I'm not sure what you mean is deprecated. If you refer to forwarding all queries to the cluster dns, then that is opt-in feature for those relying on stub domains and such. By default those queries are forwarded out of cluster immediately.
@olemarkus this is the reference https://github.com/kubernetes/kubernetes/pull/111975#issuecomment-1228194806
and again, prefer_udp looks more like a workaround to the problem, not the fix. Fix would be remove force_tcp in the first place.
You got literally the same answer in your referenced link as I gave above.
What we can allow is adding prefer_udp to CoreDNS iff you have set:
kubeDNS:
nodeLocalDNS:
forwardToKubeDNS: true
But unconditionally removing force_tcp is not the right thing to do.