Show cluster summary of available node resources
What would you like to be added?
I would like the node resources to be aggregated in the "Cluster" view, the same way that pods are in the "Workload" view.
This would show a summary of all the nodes, with their status and their cpu/memory/pods allocation.
Here is a screenshot from my implementation, using pie charts (different colors for requests and for limits):
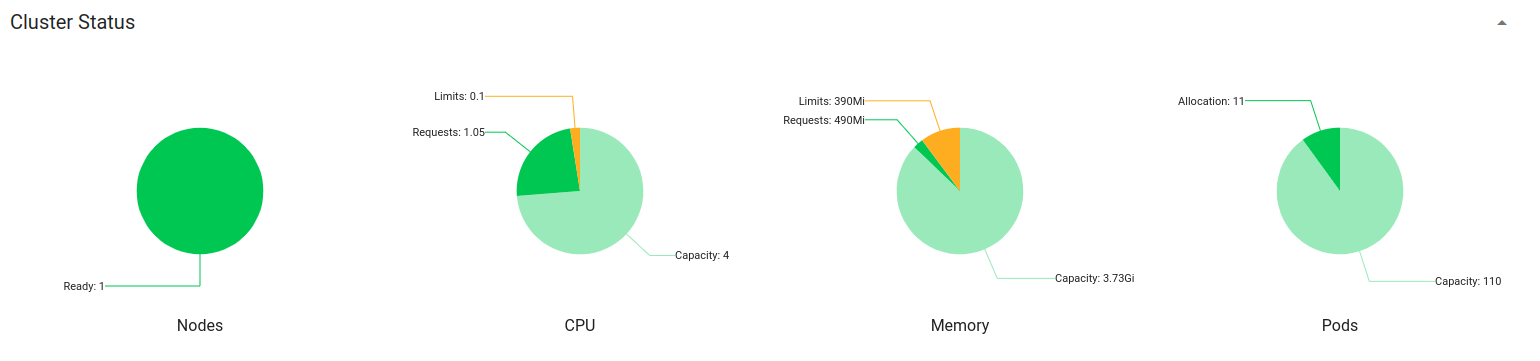
Why is this needed?
Currently there is a list of nodes, and a detail page of each. But there is no cluster summary.
The other pages are also missing the capacity information, but that will be a separate issue.

Reopening as https://github.com/kubernetes/dashboard/pull/7110 was reverted in https://github.com/kubernetes/dashboard/pull/7358.
Reason for reverting was here: https://github.com/kubernetes/dashboard/pull/7110#pullrequestreview-1071013359
It wanted nodes to be handled differently from pods.
You can create cumulative statuses in the frontend code
@maciaszczykm : I don't really understand how this would work...
I can only find the fields on NodeDetail, but not on Node(List) ?
Property 'allocatedResources' does not exist on type 'Node'.
The way I understood it, only a partial set of the nodes is sent - and then paged through with the controls...
Incoming HTTP/1.1 GET /api/v1/node?itemsPerPage=10&page=1&sortBy=d,creationTimestamp request
This makes it unsuitable to aggregate resources over the entire cluster, which was why that data was added.
It works if only wanting to show the status (in Cluster Status), the way it is currently done in Workload Status.
export interface Status {
running: number;
failed: number;
pending: number;
succeeded: number;
}
...
export interface NodeCondition {
true: number;
false: number;
unknown: number;
}
But not for the additional feature of also showing cpu/memory/pod resources, since those needs more data.

If anything, I would like to add more Cluster data in the future. Such as the current Persistent Volume allocation.
Still, it would be confusing to attach metrics of all nodes to paginated response of only 10 nodes for example. If that needs to be done on the backend side then do it as a separate API endpoint.
Hmm, I definitely want to show the entire cluster...
Like how we show the status for all the pods (in Workload Status), but then page through a few at a time in the details ?
Like @maciaszczykm mentioned, I'd also add a new endpoint like api/v1/nodes/metrics that would return cluster-wide metrics.
Ok, I will split into two separate PRs - one for the status, one for the metrics
~~Will also open a separate issue about adding support for node ephemeral storage~~
EDIT: Ephemeral storage added as #7371
The Kubernetes project currently lacks enough contributors to adequately respond to all issues and PRs.
This bot triages issues and PRs according to the following rules:
- After 90d of inactivity,
lifecycle/staleis applied - After 30d of inactivity since
lifecycle/stalewas applied,lifecycle/rottenis applied - After 30d of inactivity since
lifecycle/rottenwas applied, the issue is closed
You can:
- Mark this issue or PR as fresh with
/remove-lifecycle stale - Mark this issue or PR as rotten with
/lifecycle rotten - Close this issue or PR with
/close - Offer to help out with Issue Triage
Please send feedback to sig-contributor-experience at kubernetes/community.
/lifecycle stale
The Kubernetes project currently lacks enough active contributors to adequately respond to all issues and PRs.
This bot triages issues and PRs according to the following rules:
- After 90d of inactivity,
lifecycle/staleis applied - After 30d of inactivity since
lifecycle/stalewas applied,lifecycle/rottenis applied - After 30d of inactivity since
lifecycle/rottenwas applied, the issue is closed
You can:
- Mark this issue or PR as fresh with
/remove-lifecycle rotten - Close this issue or PR with
/close - Offer to help out with Issue Triage
Please send feedback to sig-contributor-experience at kubernetes/community.
/lifecycle rotten