dashboard pod state not sync to the commond line kubectl
Environment
Dashboard version: gcr.io/google_containers/kubernetes-dashboard-amd64:v1.6.0
Kubernetes version: Client Version: version.Info{Major:"1", Minor:"6", GitVersion:"v1.6.4+coreos.0", GitCommit:"8996efde382d88f0baef1f015ae801488fcad8c4", GitTreeState:"clean", BuildDate:"2017-05-19T21:11:20Z", GoVersion:"go1.7.5", Compiler:"gc", Platform:"linux/amd64"}
Server Version: version.Info{Major:"1", Minor:"6", GitVersion:"v1.6.4+coreos.0", GitCommit:"8996efde382d88f0baef1f015ae801488fcad8c4", GitTreeState:"clean", BuildDate:"2017-05-19T21:11:20Z", GoVersion:"go1.7.5", Compiler:"gc", Platform:"linux/amd64"}
Operating system: CentOS Linux release 7.3.1611 (Core)
Node.js version:
Go version: go1.7.5
Steps to reproduce
I install 2 masters and 2nodes, now shutdown master 1(10.110.20.98), and check pods state on master 2(10.110.20.99), kubectl command result is
kube-system fluentd-es-v1.22-6xr0n 1/1 NodeLost 1 15h 10.233.102.130 node1
but check on dashboard url : http://10.110.20.99:8080/api/v1/proxy/namespaces/kube-system/services/kubernetes-dashboard/#!/pod?namespace=kube-system
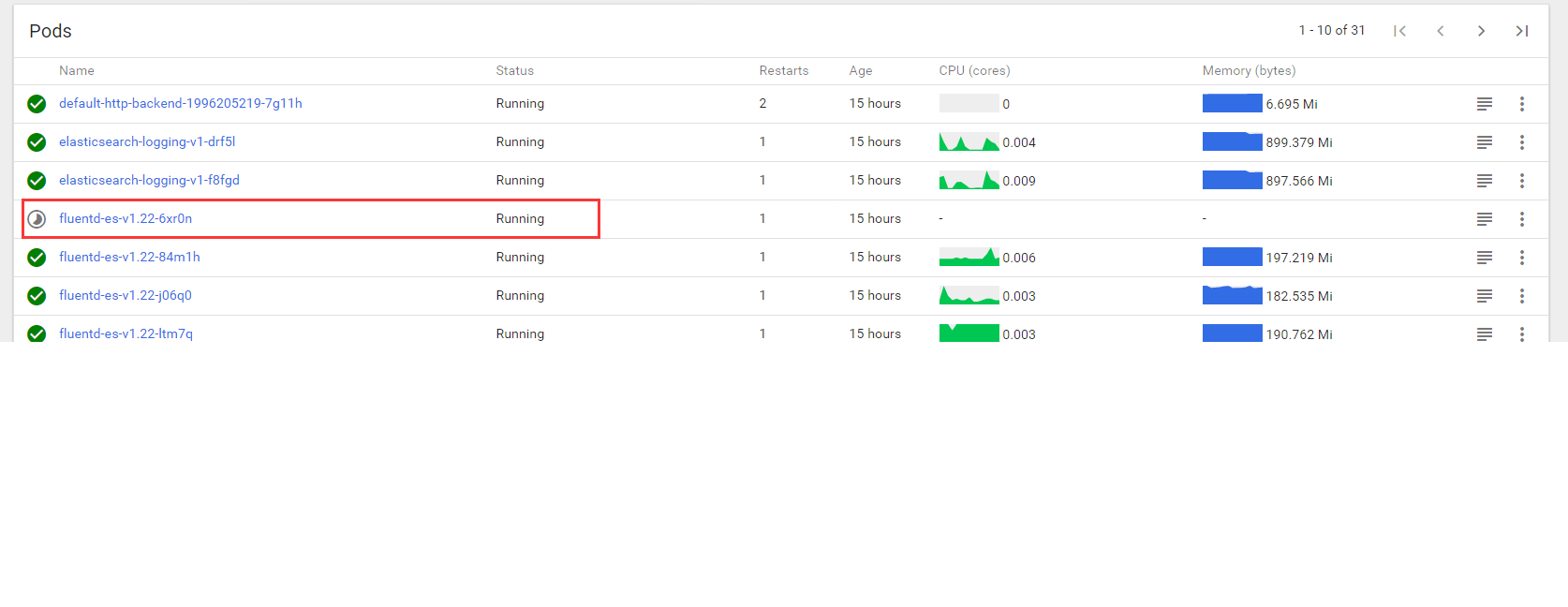 fluentd-es-v1.22-6xr0n Running
fluentd-es-v1.22-6xr0n Running
Observed result
dashboard web check pod state is still running
Expected result
dashboard web check pod state shuld be NodeLost , the same to "kubectl get pod " result
Comments
Interesting. We do not recognize such state for sure. I guess it is only displayed for a few seconds if other node is available because it will get rescheduled anyway.
Hi. I've waited for a long time. State is still running, but icon is changed correctly. Maybe there is something wrong with state for this case
Issues go stale after 90d of inactivity.
Mark the issue as fresh with /remove-lifecycle stale.
Stale issues rot after an additional 30d of inactivity and eventually close.
Prevent issues from auto-closing with an /lifecycle frozen comment.
If this issue is safe to close now please do so with /close.
Send feedback to sig-testing, kubernetes/test-infra and/or @fejta.
/lifecycle stale
Stale issues rot after 30d of inactivity.
Mark the issue as fresh with /remove-lifecycle rotten.
Rotten issues close after an additional 30d of inactivity.
If this issue is safe to close now please do so with /close.
Send feedback to sig-testing, kubernetes/test-infra and/or fejta. /lifecycle rotten /remove-lifecycle stale