metrics-server
 metrics-server copied to clipboard
metrics-server copied to clipboard
Does metrics-server scrape node metrics too early ?
Hello !
I would like to share a problem about node scraping : metrics-server seems to scrape node before it's in nodeready state.
Logs are showing scraping error of a new node during a minute and then scraping is done correctly.
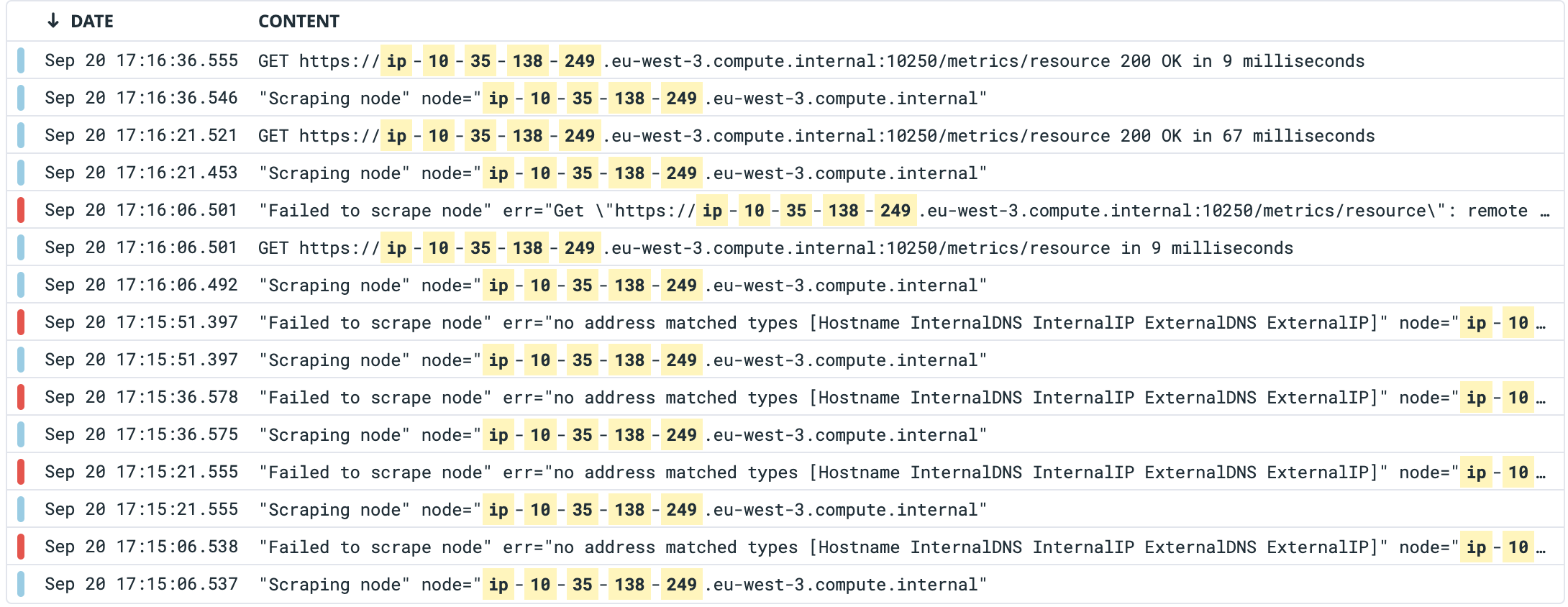
Is there any way to delay node scraping ? Or does metrics-server start do scrape metrics before the node is in nodeready state ?
We are watching this on all our EKS cluster.
Thank you!
Hi, @jeanmercierswile, Thanks for the feedback, I'm sure that metrics-server just lists all the nodes in the cluster from kubernetes, and then scrapes it, it doesn't judge the status of the nodes. I wonder, Is it necessary for us to filter node states? /cc @serathius
Hello and thank you @yangjunmyfm192085 ! Does it deserve a feature request if these error logs are useless ?
The Kubernetes project currently lacks enough contributors to adequately respond to all issues and PRs.
This bot triages issues and PRs according to the following rules:
- After 90d of inactivity,
lifecycle/staleis applied - After 30d of inactivity since
lifecycle/stalewas applied,lifecycle/rottenis applied - After 30d of inactivity since
lifecycle/rottenwas applied, the issue is closed
You can:
- Mark this issue or PR as fresh with
/remove-lifecycle stale - Mark this issue or PR as rotten with
/lifecycle rotten - Close this issue or PR with
/close - Offer to help out with Issue Triage
Please send feedback to sig-contributor-experience at kubernetes/community.
/lifecycle stale
The Kubernetes project currently lacks enough active contributors to adequately respond to all issues and PRs.
This bot triages issues and PRs according to the following rules:
- After 90d of inactivity,
lifecycle/staleis applied - After 30d of inactivity since
lifecycle/stalewas applied,lifecycle/rottenis applied - After 30d of inactivity since
lifecycle/rottenwas applied, the issue is closed
You can:
- Mark this issue or PR as fresh with
/remove-lifecycle rotten - Close this issue or PR with
/close - Offer to help out with Issue Triage
Please send feedback to sig-contributor-experience at kubernetes/community.
/lifecycle rotten
As @yangjunmyfm192085 pointed out, metrics-server simply lists the nodes, and gets their usage metrics, however, suppressing transient errors could lead to false positives in other cases.
@rexagod: Closing this issue.
In response to this:
Closing for now. /close
Instructions for interacting with me using PR comments are available here. If you have questions or suggestions related to my behavior, please file an issue against the kubernetes/test-infra repository.