cluster-api-provider-vsphere
 cluster-api-provider-vsphere copied to clipboard
cluster-api-provider-vsphere copied to clipboard
VsphereMachine.Status seems out of date, "unable to find template", but was cloned machine, exists...
/kind bug
(screenshot attached) tldr,
-
vspheremachine.status -> out of date WHEN vspheremachine template cloning fails and never gets fixed even after vspheremachinetemplate name is fixed ...
-
This results in the PowerON step never occuring, I THINK because capv controller manager, reading the status of vspheremachien, thinks "oh, i dont need to power this thing on , it doesnt exist, bc cloning failed...."
Workaround: dont modify vspheremachine template name in Vsphere after creating a new CAPV cluster, but instead, make sure its correct, beforehand...
What steps did you take and what happened:
A slightly circuitous but valid path to creating a Vsphere cluster:
- Create a new CAPV mgmt cluster w a wrong template name (uncloneable, misnamed in the input to VSPHERE_TEMPLATE)
- Check vspheremachine.status, note that the template cloning failed...
- RENAME (i.e. fix) the name of the template manually in the Vsphere UI or using govc
- RESTART the capv pod, just to make sure reconcilation happens
- Now, the bug: Even though we fixed the template, and capv cloned it down, the vspheremachine.status ISNT UPDATED.
Ok, now, after we fixed the vsphere template name , the VM was created BUT
kubectl describe vspheremachine data was out of date, the STATUS was never updated.
We fixed a vsphere template name after the vspheremachine template was created...
Installing CAPV on a TKG 1.6 cluster, i see
Owner References:
API Version: controlplane.cluster.x-k8s.io/v1beta1
Kind: KubeadmControlPlane
Name: mgmt-lt8hr
UID: ddb4ba26-bfac-442c-a794-8660f20c96f6
API Version: cluster.x-k8s.io/v1beta1
Block Owner Deletion: true
Controller: true
Kind: Machine
Name: mgmt-lt8hr-dpgcs
Spec:
Clone Mode: fullClone
Datacenter: /dc0
Datastore: /dc0/datastore/sharedVmfs-0
Disk Gi B: 20
Folder: /dc0/vm
Memory Mi B: 8192
Network:
Devices:
dhcp4: true
Network Name: /dc0/network/VM Network
Num CP Us: 4
Resource Pool: /dc0/host/cluster0/Resources
Server: 10.182.58.166
Template: /dc0/vm/photon-3-kube-v1.23.8+vmware.2-tkg.2-81d1a7892ad39f017fbaf59f9907cbe7
Status:
Conditions:
Last Transition Time: 2022-09-09T17:49:00Z
Message: unable to find template by name "/dc0/vm/photon-3-kube-v1.23.8+vmware.2-tkg.2-81d1a7892ad39f017fbaf59f9907cbe7": vm '/dc0/vm/photon-3-kube-v1.23.8+vmware.2-tkg.2-81d1a7892ad39f017fbaf59f9907cbe7' not found
Reason: CloningFailed
Severity: Warning
Status: False
Type: Ready
Last Transition Time: 2022-09-09T17:49:00Z
Message: unable to find template by name "/dc0/vm/photon-3-kube-v1.23.8+vmware.2-tkg.2-81d1a7892ad3
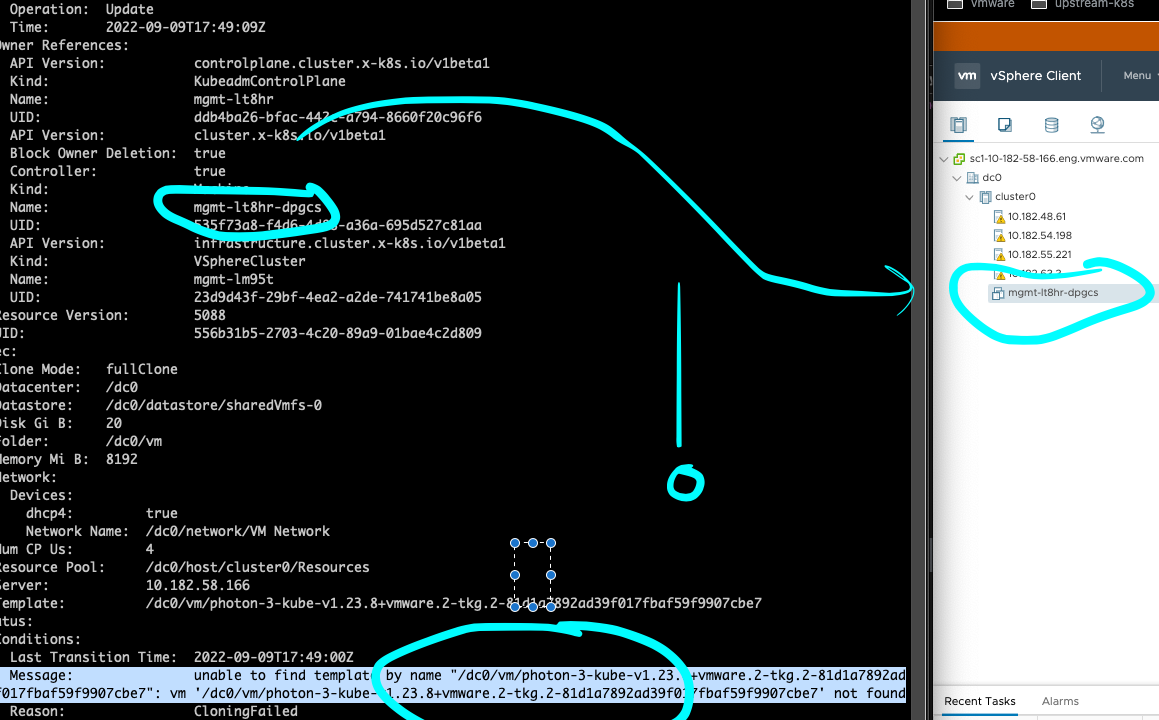
Nothing wrong with this per se - but clearely (Screenshot attached)
if i look in vsphere, the VM mgmt-lt8hr-dpgcs ... exists...
What did you expect to happen:
Vspheremachine.Status would reflect what i see in the VSphere console, and what govc has
ubuntu-ci-1804-001 :: ~/9-9-2022 » govc find | grep dp
./vm/mgmt-lt8hr-dpgcs
Anything else you would like to add: [Miscellaneous information that will assist in solving the issue.]
Environment:
- Cluster-api-provider-vsphere version: v1.3.1
Checked the controller code, we mimic the status of the condition from the VSphereVM object. Can you post the relevant Status snippet of the VSphereVM object as well?
I think we always set the condition to False in case of an error but never remove it if that particular error is resolved. The idea is eventually, either another error occurs at a different step in cloning which would update the Condition state or the Condition will be marked True if there are no errors and the steps complete.
this cluster is gone now....
I guess, that the issue is more that a new status isnt posted and maybe the root cause is that the VSphereVM is stale ?
The Kubernetes project currently lacks enough contributors to adequately respond to all issues and PRs.
This bot triages issues and PRs according to the following rules:
- After 90d of inactivity,
lifecycle/staleis applied - After 30d of inactivity since
lifecycle/stalewas applied,lifecycle/rottenis applied - After 30d of inactivity since
lifecycle/rottenwas applied, the issue is closed
You can:
- Mark this issue or PR as fresh with
/remove-lifecycle stale - Mark this issue or PR as rotten with
/lifecycle rotten - Close this issue or PR with
/close - Offer to help out with Issue Triage
Please send feedback to sig-contributor-experience at kubernetes/community.
/lifecycle stale
The Kubernetes project currently lacks enough active contributors to adequately respond to all issues and PRs.
This bot triages issues and PRs according to the following rules:
- After 90d of inactivity,
lifecycle/staleis applied - After 30d of inactivity since
lifecycle/stalewas applied,lifecycle/rottenis applied - After 30d of inactivity since
lifecycle/rottenwas applied, the issue is closed
You can:
- Mark this issue or PR as fresh with
/remove-lifecycle rotten - Close this issue or PR with
/close - Offer to help out with Issue Triage
Please send feedback to sig-contributor-experience at kubernetes/community.
/lifecycle rotten
Hi Friends!
We're also seeing a case where VMs are never powered on. We're not seeing cloning fail, it seems the clone succeeds in our case, but we do not ever see a task queued that would Power On the vm. Did anything more ever come of this issue?
I checked this issue and it does not for me on main, also not reproducible for me on v1.5.0 or even v1.3.1.
What I did (v1.3.1):
- init kind cluster and create capv cluster using a VSPHERE_TEMPLATE which does not exist
export EXP_CLUSTER_RESOURCE_SET=true
clusterctl init --infrastructure=vsphere:v1.3.1
export VSPHERE_TEMPLATE=ubuntu-2004-kube-v1.26.2-doesnotexist
clusterctl generate cluster capi-quickstart --infrastructure=vsphere:v1.3.1 \
--kubernetes-version v1.26.2 \
--control-plane-machine-count=1 \
--worker-machine-count=1 > cluster-vsphere.yaml
kubectl apply -f cluster-vsphere.yaml
- Wait for cluster provisioned and check that vspherevm does not get provisioned with condition:
- lastTransitionTime: "2023-07-26T09:19:09Z"
message: 'unable to find template by name "ubuntu-2004-kube-v1.26.2-doesnotexist":
vm ''ubuntu-2004-kube-v1.26.2-doesnotexist'' not found'
reason: CloningFailed
severity: Warning
status: "False"
type: VMProvisioned
- Create the template in vsphere
- Delete capv pod to trigger reconciliation (resync period of the controller would do the same after some time)
kubectl delete po -n capv-system capv-controller-manager-784c57cb6d-jp8t7
- See that the vm gets powered on and conditions get cleaned up too:
❯ kubectl get vspherevms.infrastructure.cluster.x-k8s.io capi-quickstart-589kg -o yaml | grep status -A 20
status:
addresses:
- 10.206.182.74
- fd01:3:7:103:250:56ff:fea0:e809
cloneMode: fullClone
conditions:
- lastTransitionTime: "2023-07-26T09:23:42Z"
status: "True"
type: Ready
- lastTransitionTime: "2023-07-26T09:19:02Z"
status: "True"
type: VCenterAvailable
- lastTransitionTime: "2023-07-26T09:23:42Z"
status: "True"
type: VMProvisioned
network:
- connected: true
ipAddrs:
- 10.206.182.74
- fd01:3:7:103:250:56ff:fea0:e809
macAddr: 00:50:56:a0:e8:09
networkName: VM Network
ready: true
@sbueringer: Closing this issue.
In response to this:
/close
as it's not reproducible on recent versions
Instructions for interacting with me using PR comments are available here. If you have questions or suggestions related to my behavior, please file an issue against the kubernetes/test-infra repository.