cluster-api-provider-openstack
 cluster-api-provider-openstack copied to clipboard
cluster-api-provider-openstack copied to clipboard
Support failure domains for all OpenStack services
/kind feature
Goals
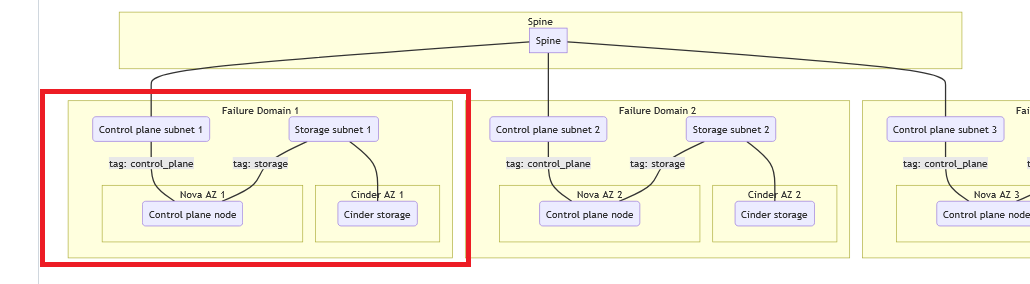
This feature intends to support deployments where the user wants to distribute their cluster's control plane across multiple failure domains. A failure domain describe a set of OpenStack services which are replicated in each failure domain covering compute, storage, and network. Currently we only support distributing the control plane across compute availability zones.
An example control plane deployment with 3 failure domains is shown below:
graph BT
subgraph Spine
spine[Spine]
end
subgraph Failure Domain 1
direction TB
control_plane_net_1(Control plane subnet 1)
storage_net_1(Storage subnet 1)
subgraph Nova AZ 1
control_1(Control plane node)
end
subgraph Cinder AZ 1
storage_1(Cinder storage)
end
control_1 -- tag: control_plane --- control_plane_net_1
control_1 -- tag: storage --- storage_net_1
storage_1 --- storage_net_1
end
subgraph Failure Domain 2
direction TB
control_plane_net_2(Control plane subnet 2)
storage_net_2(Storage subnet 2)
subgraph Nova AZ 2
control_2(Control plane node)
end
subgraph Cinder AZ 2
storage_2(Cinder storage)
end
control_2 -- tag: control_plane --- control_plane_net_2
control_2 -- tag: storage --- storage_net_2
storage_2 --- storage_net_2
end
subgraph Failure Domain 3
direction TB
control_plane_net_3(Control plane subnet 3)
storage_net_3(Storage subnet 3)
subgraph Nova AZ 3
control_3(Control plane node)
end
subgraph Cinder AZ 3
storage_3(Cinder storage)
end
control_3 -- tag: control_plane --- control_plane_net_3
control_3 -- tag: storage --- storage_net_3
storage_3 --- storage_net_3
end
control_plane_net_1 --- spine
control_plane_net_2 --- spine
control_plane_net_3 --- spine
User stories
User A wants to deploy a cluster to multiple failure domains. A failure domain comprises none or more of the following:
- Distinct compute hosts
- Distinct backend storage
- Distinct network fabric
User A wants CAPI to spread control planes across these failure domains according to its default behaviour.
User B wants the current behaviour based exclusively on Nova availability zones.
User C is not interested in failure domains. User C wants server deployment to use OpenStack’s default scheduling rules.
Current API
In OpenStackClusterSpec:
// ControlPlaneAvailabilityZones is the az to deploy control plane to
// +listType=set
ControlPlaneAvailabilityZones []string `json:"controlPlaneAvailabilityZones,omitempty"`
// Indicates whether to omit the az for control plane nodes, allowing the Nova scheduler
// to make a decision on which az to use based on other scheduling constraints
ControlPlaneOmitAvailabilityZone bool `json:"controlPlaneOmitAvailabilityZone,omitempty"`
In MachineSpec:
// FailureDomain is the failure domain the machine will be created in.
// Must match a key in the FailureDomains map stored on the cluster object.
// +optional
FailureDomain *string `json:"failureDomain,omitempty"`
Behaviour
On cluster reconcile:
- Get a list of all AZs from OpenStack
- For each AZ
- We add it to
OpenStackCluster.Status.FailureDomains[az name] - If it’s listed in
controlPlaneAvailabilityZoneswe setControlPlane: true - Otherwise we set
ControlPlaneaccording toControlPlaneOmitAvailabilityZone
- We add it to
In the OpenStack machine controller we copy Machine.Spec.FailureDomain to instanceSpec.FailureDomain. This is used both for server create and the default root volume AZ.
Proposed API Changes
We define a new FailureDomain struct to describe the supported properties of a failure domain:
type FailureDomain struct {
// ComputeAvailabilityZone is the name of a valid nova availability zone. The server will be created in this availability zone.
// +optional
ComputeAvailabilityZone string `json:"computeAvailabilityZone,omitempty"`
// StorageAvailabilityZone is the name of a valid cinder availability
// zone. This will be the availability zone of the root volume if one is
// specified.
// +optional
StorageAvailabilityZone string `json:"storageAvailabilityZone,omitempty"`
// Ports defines a set of ports and their attached networks. These will be prepended to any another ports attached to the server.
// +optional
Ports []PortOpts `json:"ports,omitempty"`
}
We additionally define a FailureDomainDefinition struct which embed a FailureDomain and adds metadata required by CAPI:
type FailureDomainDefinition struct {
// Name is a string by which a failure domain is referenced at creation
// time.
// As this is only a reference, it is not safe to assume that all
// machines created using this name were also using the same failure
// domain.
// +required
Name string `json:"name"`
// MachinePlacement defines which machines this failure domain is suitable for.
// 'All' specifies that the failure domain is suitable for all machines. Control plane machines will be automatically distributed across failure domains with a MachinePlacement of All.
// 'NoControlPlane' specifies that the failure domain will not be used by control plane machines. The failure domain may be referenced by worker machines, but will not be used by control plane machines.
// If not specified, the default is 'All'.
// +kubebuilder:default:="All"
// +optional
MachinePlacement FailureDomainMachinePlacement `json:"machinePlacement,omitempty"`
FailureDomain `json:",inline"`
}
We include a list of FailureDomainDefinitions in OpenStackClusterSpec:
// FailureDomains defines a set of failure domains that can be
// referenced by machines in this cluster. These are in addition to
// automatically discovered Nova availability zones.
// +listType=map
// +listMapKey=name
FailureDomains []FailureDomainDefinition `json:"failureDomains,omitempty"`
There are now 2 ways a failure domain can be defined:
- the existing way, by automatically discovering nova availability zones
- a new way, by explicitly defining the failure domain in
OpenStackClusterSpec
We distinguish between these two by setting a Type attribute on the CAPI-defined FailureDomains field in OpenStackClusterStatus. The currently supported types are AvailabilityZone, and Cluster.
There is risk associated with Cluster failure domain, as a machine definition now depends on a reference to an external object which is not guaranteed to be immutable. To mitigate this we also add a copy of the machine's failure domain to OpenStackMachineStatus:
// FailureDomain is a copy of the failure domain used to create the
// machine. Properties specified in FailureDomain substitute for the
// equivalent values in the OpenStackMachineSpec. See the FailureDomain
// type for details of the supported substitutions.
// +optional
FailureDomain *FailureDomain `json:"failureDomain,omitempty"`
We add code to the webhook to ensure that OpenStackMachineStatus.FailureDomain is immutable once set. This ensures that the definition of an individual machine doesn't change over its lifetime, even if the failure domain it is defined in is later modified or removed.
Proposed Behaviour
The cluster controller is responsible for populating failure domains. It now has 2 ways of doing this:
- automatic detection of nova availability zones, as before
- explicit definition of failure domains in the cluster spec
The behaviour of availability zone discovery is unchanged. That is, if the user doesn't define any explicit failure domains there is no change in functionality. ControlPlaneAvailabilityZones and ControlPlaneOmitAvailabilityZone have the same behaviour as before.
After discovering availability zones the cluster controller adds explicit failure domains. This allows an explicit failure domain to 'override' a discovered availability zone with the same name.
Additionally, the cluster controller adds a Type attribute to the failure domain declaration in the cluster spec specifying either AvailabilityZone or Cluster according to how the failure domain was defined.
The machine controller must be able to handle both types of failure domain definition. It does this by translating the failure domain definition, if any, into a FailureDomain struct when first reconciled and storing the result in the machine status. Subsequent reconciles only ever refer to the failure domain definition in the machine status. A failure domain of type AvailabilityZone is translated into a FailureDomain which defines only a ComputeAvailabilityZone. A failure domain of type Cluster is copied from the cluster spec.
The machine controller will merge failure domain parameters with machine parameters. Defining an ambiguous configuration will immediately put the machine into a Failed state. Specifically, it is an error to define RootVolume.AvailabilityZone on a machine with a failure domain which defines StorageAvailabilityZone.
Failure domain ports will be prepended to machine ports, so there is no conflict there. Note that if a port is defined in both places it will be added twice.
Upgrades
Upgrading happens automatically and safely the first time an OpenStackCluster or OpenStackMachine is reconciled by its respective controller.
OpenStackCluster
When the cluster controller runs the first time after upgrade the failure domains in the status will be updated as before. Assuming no explicit failure domains have been added the output will be identical to before, except that the failure domains will now have a Type: AvailabilityZone attribute. The only controller which reads this value is the machine controller. As the machine controller will treat a failure domain with no Type attribute as AvailabilityZone there is no race with the machine controller.
OpenStackMachine
The first time the machine controller reconciles an existing machine after upgrade it will discover that failureDomain in the status is not set and will set it. There is different behaviour for an upgrading machine than for a newly created machine in this case. We must not accidentally redefine a previously created machine. The previous behaviour was that if failureDomain is defined on the MachineSpec it was used as a Nova availability zone. This is the behaviour we copy.
If a machine does not have its failure domain defined but does have a providerID then we assume we are upgrading. In this case we do not attempt to lookup the referenced Machine failure domain in the cluster object, but instead assume it was used as a Nova availability zone and create a corresponding failure domain for the machine.
Caveats
Interaction with higher order controllers
Machine deployments are not currently able to watch any of their dependent infrastructure objects for changes. This currently includes OpenStackMachineTemplate, but with the addition of this feature it will also include failure domains. Specifically, if a user modifies a failure domain which is referenced by a machine template which is referenced by a machine deployment, modifications to the failure domain will not result in those changes being rolled out to machines which reference it.
If a user makes a change to a failure domain and needs that change to be rolled out, they must create a new machine template which references a new failure domain with a different name. This will cause the change to be rolled out deterministically.
Future expansion
Inclusion of flavors in a failure domain
In addition to availability zones, it is possible to confine servers by specifying a host aggregate on a flavor. The first draft of this proposal included a flavor in the failure domain, but in retrospect this would not allow flexibility to use multiple flavors in the failure domain. If were to include flavors in the failure domain we may need to supply a map containing multiple flavors. However, at this point it may just be simpler to ensure that where a failure domain specifies an availability zone, any flavor host aggregate is valid in that availability zone.
Something along these lines may be added in the future if the use case becomes clearer.
Examples
Nova AZ, Cinder AZ, control plane and storage subnets
In this scenario we place control plane nodes in explicit nova and cinder AZs, and attach them to specific control plane and storage subnets. Subnets are specified by name. Note that we must also explicitly prevent the control plane from being scheduled to discovered nova availability zones.
openStackCluster:
spec:
controlPlaneOmitAvailabilityZone: true
failureDomains:
- name: failure_domain_1:
computeAvailabilityZone: nova_az_1
storageAvailabilityZone: cinder_az_1
ports:
- tags:
- control_plane
fixedIPs:
- subnet:
name: control_plane_subnet_1
- tags:
- storage
fixedIPs:
- subnet:
name: storage_subnet_1
- name: failure_domain_2:
computeAvailabilityZone: nova_az_2
storageAvailabilityZone: cinder_az_2
ports:
- tags:
- control_plane
fixedIPs:
- subnet:
name: control_plane_subnet_2
- tags:
- storage
fixedIPs:
- subnet:
name: storage_subnet_2
- name: failure_domain_3:
computeAvailabilityZone: nova_az_3
storageAvailabilityZone: cinder_az_3
ports:
- tags:
- control_plane
fixedIPs:
- subnet:
name: control_plane_subnet_3
- tags:
- storage
fixedIPs:
- subnet:
name: storage_subnet_3
Explicitly ignore failure domains
This has not changed:
openStackCluster:
spec:
controlPlaneOmitAvailabilityZone: true
Spread over 3 specific nova AZs
This has not changed:
openStackCluster:
spec:
controlPlaneAvailabilityZones:
- nova_az_1
- nova_az_2
- nova_az_3
Spread over all available nova AZs
This has not changed, and is the current default behaviour. No explicit availability zone or failure domain config is required.
Edits
2023-02-16
- Rewrite to reflect the implementation in #1466
2022-10-10
- Added Open Questions section with Machine Deployment discussion
- Replaced NoControlPlane with MachinePlacement
- Removed flavor
- Filled in Upgrade section with an example
- Added open question about attributes status.FailureDomains
An initial set of folks I hope might be interested in this idea: /cc @mkjpryor /cc @pierreprinetti /cc @EmilienM /cc @JoelSpeed
[Note] Interaction with MachineDeployment. What if we want to update the failure domain and have all machines using the failure domain rebuilt. Is this worthwhile? Would it require an API change?
guess it's a second step thing? at least at first step seems it's over complicated
Specifically all of the following are errors and will result in the creation being rejected:
my understanding webhook is usually used for incorrect param or immutable update but seems this need deep understand the meaning of each param like AZ etc, currently those logic seems in controller instead of webhook
// Flavor is the name of a valid nova flavor // +optional Flavor string
json:"flavor,omitempty"
curious why the flavor is related to a failuredomain ,from the sample seems it's comparing with flavor but very curious on the design as flavor to me is a pure logic definition and should not related to any physical things like AZ/failure domain
and I Think the API is about to describe the red rectangle logically, but do those resource good enough? e.g any other resource might be in such Failuredomain such as LB or other entites?
// NoControlPlane specifies that this failure domain must not be used for control plane nodes // +optional NoControlPlane bool `json:"noControlPlane,omitempty"`
Typically, in terms of API design, we prefer enums over bools. Bools do not expand well if there are any changes in the future. Have you considered an enum that determines the placement? For example, machinePlacement: ControlPlane | Worker | All to allow restricting failure domains to ControlPlane, Worker or any Machine type?
// Flavor is the name of a valid nova flavor // +optional Flavor string `json:"flavor,omitempty"`
Not clear to me from reading this why the flavour is relevant here, could do with some expansion on this
@jichenjc @JoelSpeed I agree the inclusion of flavor here looks weird. This came out of earlier discussion with @mkjpryor about how they are using flavors in practise.
Flavors in OpenStack can encapsulate a whole ton of stuff (probably too much, tbh, but that discussion is out of scope). Amongst other things they can specify host aggregates which define where a server is allowed to run the same way AZ does. I intended to capture this in the example 'Nova placement by host aggregate on flavor, control plane subnet only'.
IIRC Matt's use case was actually restricted to workers rather than the control plane. From memory the issue was that CAPI was setting a failure domain which we translated into an AZ which was then incompatible with certain flavors due to the defined host aggregate. The implication here is that different failure domains require different flavors. However, I wonder if including a single flavor still isn't expressive enough for this use case. Perhaps we should remove it until we understand it better.
@mkjpryor very interested in your thoughts on this.
[Note] Interaction with MachineDeployment. What if we want to update the failure domain and have all machines using the failure domain rebuilt. Is this worthwhile? Would it require an API change?
guess it's a
second stepthing? at least at first step seems it's over complicated
I put this in as a placeholder for an incomplete thought. It's still incomplete, but I'll try to expand:
Machines are immutable. We will never attempt to update a machine because the failure domain definition changed. However, the purpose of a Machine Deployment (IIUC) is to achieve essentially this, except by deleting the old machines and creating new ones with the new definition. Typically this would be visible to the MD controller because you will have modified the template. But for a failure domain change you won't have modified the template because it only refers to the FD by name, which hasn't changed; you'll have modified the cluster object.
Is there any way we could cleanly represent in an API that a change to a FD should cause machines controlled by a machine deployment to be replaced?
Specifically all of the following are errors and will result in the creation being rejected:
my understanding webhook is usually used for incorrect param or immutable update but seems this need deep understand the meaning of each param like AZ etc, currently those logic seems in controller instead of webhook
There's no deep understanding required here. All of these use cases are 'incorrect parameters'. None require an OpenStack API call. We're just rejecting cases where the user has specified the same thing twice. Doing this in a webhook makes this more immediately obvious to the user.
@jichenjc As for whether the implementation of failure domains is complete: very possibly not! It looks like Octavia also has availability zones, but I'm not personally familiar with them.
If we added support for Octavia AZs, would they fit neatly into this API with the addition of a loadBalancerAZ field? If so I think we're good for now. We can add things later.
@JoelSpeed An enum does sound better. I think I'd want 'All' to be the zero value.
How about: All = 0 WorkerOnly = 1
I don't think we currently have any way to use ControlPlaneOnly. This logic is only used to tell CAPI which FDs to use for the control plane. I don't think we currently have a hook we could use to prevent its use by a worker. However, by using an enum we would be able to represent that if it ever became a thing, and in the meantime the naming is still better.
machinePlacement also seems like a good name.
@pierreprinetti does 👆 sound better to you?
How about: All = 0 WorkerOnly = 1
Enums in kube apis are represented as typed strings rather than integers but yep, otherwise LGTM. You would set the default value to All or define that when omitted, the behaviour is the same as All
However, I wonder if including a single flavor still isn't expressive enough for this use case. Perhaps we should remove it until we understand it better.
yes, If we need define some thing just for Fauilre domain, we may define in our struct directly instead of flavor .. and agree to remove it first until we know what's exactly to be added
If we added support for Octavia AZs, would they fit neatly into this API with the addition of a loadBalancerAZ field?
ok, probably let's go with current first, seems so far nothing block us in adding more stuffs later
MachinePlacement defines which machines this failure domain is suitable for.
I may be missing something here, but when reading the description for
MachinePlacement, it sounds more like a "MachineSelector" to me. Do you think it would make sense to use labels to select the Machines instead of this enum?
It's an interesting idea. However, I don't think we can do this for a couple of reasons:
- machinePlacement is used before machine creation, so we don't have those labels
- We'd need to teach the control plane controller about it: right now it's just setting ControlPlane: (true|false)
The Kubernetes project currently lacks enough contributors to adequately respond to all issues and PRs.
This bot triages issues and PRs according to the following rules:
- After 90d of inactivity,
lifecycle/staleis applied - After 30d of inactivity since
lifecycle/stalewas applied,lifecycle/rottenis applied - After 30d of inactivity since
lifecycle/rottenwas applied, the issue is closed
You can:
- Mark this issue or PR as fresh with
/remove-lifecycle stale - Mark this issue or PR as rotten with
/lifecycle rotten - Close this issue or PR with
/close - Offer to help out with Issue Triage
Please send feedback to sig-contributor-experience at kubernetes/community.
/lifecycle stale
The Kubernetes project currently lacks enough contributors to adequately respond to all issues.
This bot triages un-triaged issues according to the following rules:
- After 90d of inactivity,
lifecycle/staleis applied - After 30d of inactivity since
lifecycle/stalewas applied,lifecycle/rottenis applied - After 30d of inactivity since
lifecycle/rottenwas applied, the issue is closed
You can:
- Mark this issue as fresh with
/remove-lifecycle stale - Close this issue with
/close - Offer to help out with Issue Triage
Please send feedback to sig-contributor-experience at kubernetes/community.
/lifecycle stale
The Kubernetes project currently lacks enough contributors to adequately respond to all issues.
This bot triages un-triaged issues according to the following rules:
- After 90d of inactivity,
lifecycle/staleis applied - After 30d of inactivity since
lifecycle/stalewas applied,lifecycle/rottenis applied - After 30d of inactivity since
lifecycle/rottenwas applied, the issue is closed
You can:
- Mark this issue as fresh with
/remove-lifecycle stale - Close this issue with
/close - Offer to help out with Issue Triage
Please send feedback to sig-contributor-experience at kubernetes/community.
/lifecycle stale
The Kubernetes project currently lacks enough contributors to adequately respond to all issues.
This bot triages un-triaged issues according to the following rules:
- After 90d of inactivity,
lifecycle/staleis applied - After 30d of inactivity since
lifecycle/stalewas applied,lifecycle/rottenis applied - After 30d of inactivity since
lifecycle/rottenwas applied, the issue is closed
You can:
- Mark this issue as fresh with
/remove-lifecycle stale - Close this issue with
/close - Offer to help out with Issue Triage
Please send feedback to sig-contributor-experience at kubernetes/community.
/lifecycle stale