cloud-provider-azure
 cloud-provider-azure copied to clipboard
cloud-provider-azure copied to clipboard
[BUG] Private Link deletion gets stuck on existing Private Endpoint connections
What happened:
When using the new managed Private Link Service (https://github.com/kubernetes-sigs/cloud-provider-azure/issues/872), a cluster (or just the Private Link itself, too, I guess) cannot be deleted until all Private Endpoint Connections to that PLS are deleted beforehand. If you attemp to delete AKS, all the resources from the managed RG get deleted - expect the PLS and in the internal LB. After this the deletion process just gets stuck until the connections are manually deleted.
What you expected to happen:
AKS should automatically remove any Private Endpoint Connections when the managed Private Link Service is to be deleted. Since all other resources do get deleted, incoming requests will fail anyway. So it's not like we need to block deletion because of these connections.
How to reproduce it (as minimally and precisely as possible):
- Expose a k8s service with the PLS annotation
- create an Private Endpoint against that PLS
- Try to delete the AKS cluster
Environment:
- Kubernetes version (use
kubectl version): 1.23.5
@feiskyer
This is actually the common behavior for most Azure services. To avoid unexpected deletion of Azure resources, the deletion would be blocked if they are still referenced by another resources. In this case, because PrivateEndpoint is managed by customer, customer should delete the PrivateEndpoint before deleting AKS cluster.
hmm but since all the other resources of the cluster also get deleted, what is the point in keeping the PLS? At that point it cannot be recovered anymore
hmm but since all the other resources of the cluster also get deleted, what is the point in keeping the PLS? At that point it cannot be recovered anymore
I ran into the same issue yesterday. When the PLS is created (and managed) by AKS (via AKS PLS integration) it's by default created within the AKS-owned/managed MC_ resource group next to the LB. Wouldn't it be natural/logical then to share the same lifecycle as the AKS cluster including getting deleted together with the AKS cluster?
If the PE is created in the MC_ resource group, then they should share the same lifecycle. But if the PE is outside, then AKS would not have the permission to operate the PE.
I might be wrong, but I would assume as the owner of the PLS (which AKS is), you have all the permissions to revoke/delete any Private Endpoint Connections I do not mean the actual Private Endpoint resource. That will just end up in a Disconnected state, which is expected behavior)
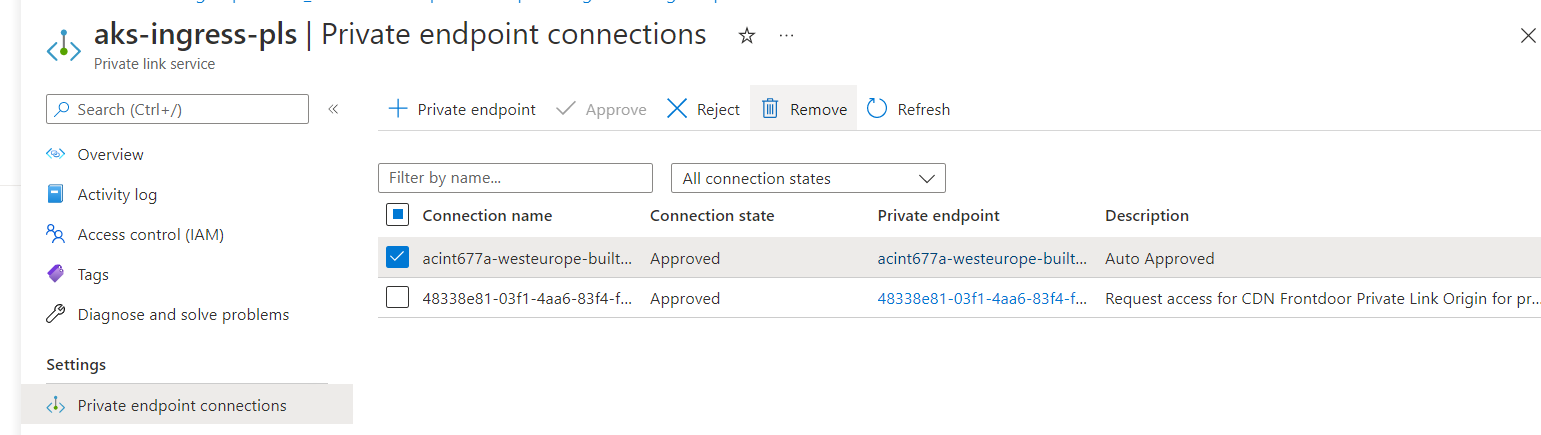
any update on this @feiskyer? I still strongly believe AKS deletion should not get stuck on this
No, it is actually same for other resources under node resource group. If they are referenced by other things outside of node resource group, customers need to unlink them before deleting the cluster.
hm ok I see. But what is the reasoning behind this? As the cluster deletion itself is not being stopped, any other resources become stale and are not recoverable anyway.
The Kubernetes project currently lacks enough contributors to adequately respond to all issues and PRs.
This bot triages issues and PRs according to the following rules:
- After 90d of inactivity,
lifecycle/staleis applied - After 30d of inactivity since
lifecycle/stalewas applied,lifecycle/rottenis applied - After 30d of inactivity since
lifecycle/rottenwas applied, the issue is closed
You can:
- Mark this issue or PR as fresh with
/remove-lifecycle stale - Mark this issue or PR as rotten with
/lifecycle rotten - Close this issue or PR with
/close - Offer to help out with Issue Triage
Please send feedback to sig-contributor-experience at kubernetes/community.
/lifecycle stale
The Kubernetes project currently lacks enough active contributors to adequately respond to all issues and PRs.
This bot triages issues and PRs according to the following rules:
- After 90d of inactivity,
lifecycle/staleis applied - After 30d of inactivity since
lifecycle/stalewas applied,lifecycle/rottenis applied - After 30d of inactivity since
lifecycle/rottenwas applied, the issue is closed
You can:
- Mark this issue or PR as fresh with
/remove-lifecycle rotten - Close this issue or PR with
/close - Offer to help out with Issue Triage
Please send feedback to sig-contributor-experience at kubernetes/community.
/lifecycle rotten
The Kubernetes project currently lacks enough active contributors to adequately respond to all issues and PRs.
This bot triages issues according to the following rules:
- After 90d of inactivity,
lifecycle/staleis applied - After 30d of inactivity since
lifecycle/stalewas applied,lifecycle/rottenis applied - After 30d of inactivity since
lifecycle/rottenwas applied, the issue is closed
You can:
- Reopen this issue with
/reopen - Mark this issue as fresh with
/remove-lifecycle rotten - Offer to help out with Issue Triage
Please send feedback to sig-contributor-experience at kubernetes/community.
/close not-planned
@k8s-triage-robot: Closing this issue, marking it as "Not Planned".
In response to this:
The Kubernetes project currently lacks enough active contributors to adequately respond to all issues and PRs.
This bot triages issues according to the following rules:
- After 90d of inactivity,
lifecycle/staleis applied- After 30d of inactivity since
lifecycle/stalewas applied,lifecycle/rottenis applied- After 30d of inactivity since
lifecycle/rottenwas applied, the issue is closedYou can:
- Reopen this issue with
/reopen- Mark this issue as fresh with
/remove-lifecycle rotten- Offer to help out with Issue Triage
Please send feedback to sig-contributor-experience at kubernetes/community.
/close not-planned
Instructions for interacting with me using PR comments are available here. If you have questions or suggestions related to my behavior, please file an issue against the kubernetes/test-infra repository.