aws-load-balancer-controller
 aws-load-balancer-controller copied to clipboard
aws-load-balancer-controller copied to clipboard
Support for kubernetes clusters with multiple VPCs
Is your feature request related to a problem?
Problem - the controller is unable to create load balancers in multiple VPCs.
For example, a cluster is composed of VPC A and VPC B, and the controller deployed in this cluster should create load balancers in VPC A and VPC B... currently, it's not possible to do this.
Describe the solution you'd like
A new annotation, perhaps?
As an example:
service.beta.kubernetes.io/aws-load-balancer-target-vpc-tags - specifies the tags of the target VPC to deploy the NLB in.
alb.ingress.kubernetes.io/target-vpc-tags - specifies the tags of the target VPC to deploy the ALB in.
Happy to contribute, if it's possible to do this and you think it would be useful.
@niall-d-tw, did you intend to create a single load balancer for both VPCs or looking for multiple loadbalancers on each of the VPCs? could you clarify further?
could you clarify further?
Yes.
Looking for the the latter - the load balancer controller could run on a worker in either VPC A, or VPC B, and it would be able to create multiple load balancers in each of the VPCs.
@niall-d-tw, we don't have plans to support one ingress mapping to multiple load balancers at the moment.
Hi @kishorj , one ingress mapping to multiple load balancers is not the request.
Consider the following cluster, which spans two VPCs :
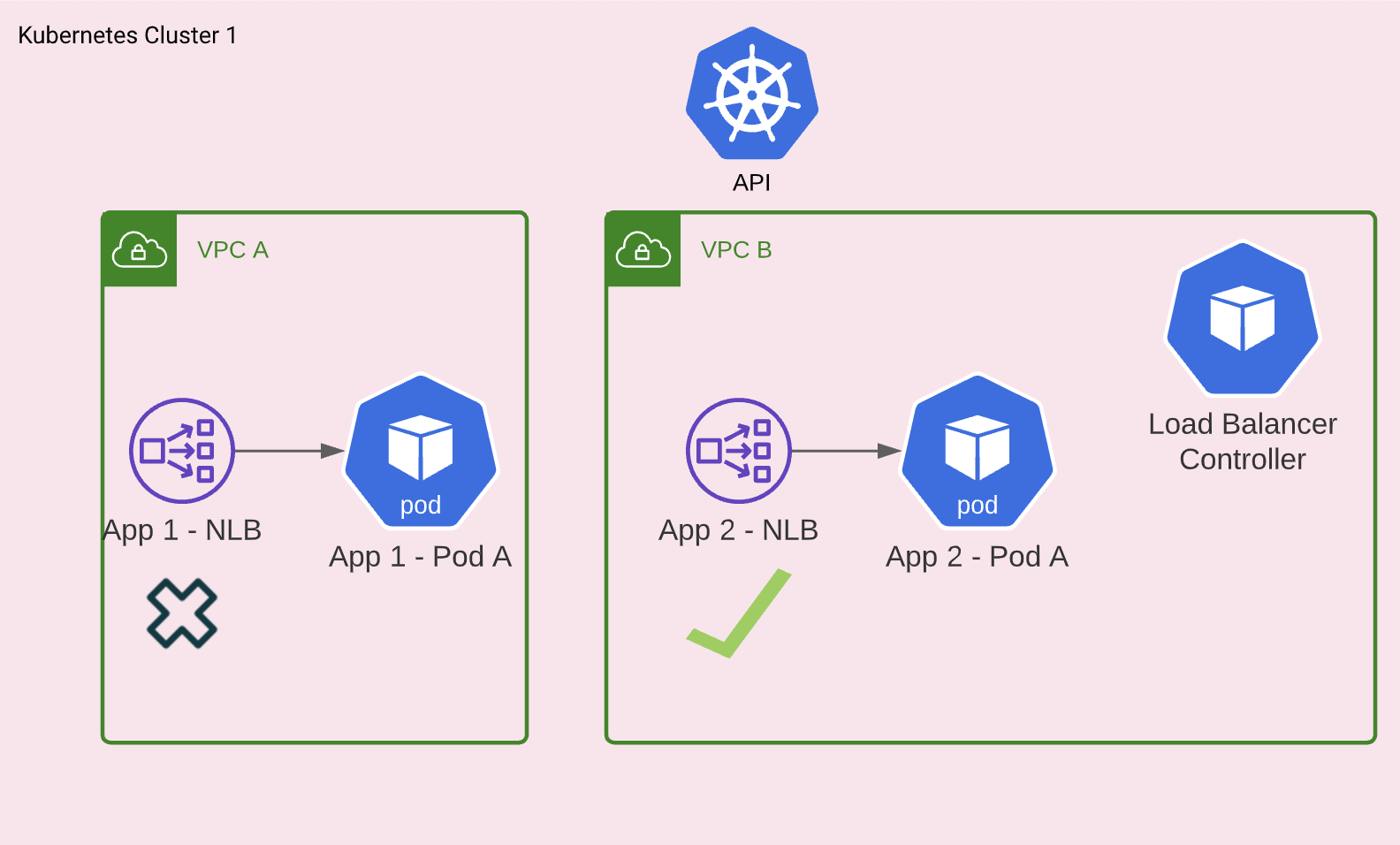
If the load balancer controller is running in VPC B, it won't be able to create "App 1 - NLB" in VPC A.
As I understand the controller only sees the VPC of whatever worker it is running on. This request is to explore if it's possible to declare which VPC the ingress, or service, resource should be created in.
@niall-d-tw
I think it's already possible, the controller by default discovers VPC/Region from EC2 metadata, but we support to overwrite the VPC via flags: --aws-vpc-id
So you can give the controller another VPCID, and it should work as expected.
Hi @M00nF1sh , yes, I've seen the flag. Let's say I configure the controller with the flag --aws-vpc-id=VPC-A - I understand that the controller won't be able to create the NLB in VPC B now.
Hi @kishorj and @M00nF1sh, please respond - do you understand the problem the feature request is trying to solve?
@niall-d-tw Do you mean you want a single controller pod to spin up NLBs in multiple VPCs? e.g. on Ingress have a annotation to denote the intended VPC?
Hi @M00nF1sh - yes, that's it. I guess the crux of the problem is VPC discovery. I would be happy to contribute, if you have any ideas around this.
The Kubernetes project currently lacks enough contributors to adequately respond to all issues and PRs.
This bot triages issues and PRs according to the following rules:
- After 90d of inactivity,
lifecycle/staleis applied - After 30d of inactivity since
lifecycle/stalewas applied,lifecycle/rottenis applied - After 30d of inactivity since
lifecycle/rottenwas applied, the issue is closed
You can:
- Mark this issue or PR as fresh with
/remove-lifecycle stale - Mark this issue or PR as rotten with
/lifecycle rotten - Close this issue or PR with
/close - Offer to help out with Issue Triage
Please send feedback to sig-contributor-experience at kubernetes/community.
/lifecycle stale
Hi @kishorj and @M00nF1sh - I think adding something like this first -> https://github.com/kubernetes-sigs/aws-load-balancer-controller/issues/2430#issuecomment-1042412589 would make a feature like this easy to implement. I'd be happy to work on #2430 before this issue, if you think the comment is still the correct approach.
The Kubernetes project currently lacks enough contributors to adequately respond to all issues and PRs.
This bot triages issues and PRs according to the following rules:
- After 90d of inactivity,
lifecycle/staleis applied - After 30d of inactivity since
lifecycle/stalewas applied,lifecycle/rottenis applied - After 30d of inactivity since
lifecycle/rottenwas applied, the issue is closed
You can:
- Mark this issue or PR as fresh with
/remove-lifecycle stale - Mark this issue or PR as rotten with
/lifecycle rotten - Close this issue or PR with
/close - Offer to help out with Issue Triage
Please send feedback to sig-contributor-experience at kubernetes/community.
/lifecycle stale
The Kubernetes project currently lacks enough active contributors to adequately respond to all issues and PRs.
This bot triages issues and PRs according to the following rules:
- After 90d of inactivity,
lifecycle/staleis applied - After 30d of inactivity since
lifecycle/stalewas applied,lifecycle/rottenis applied - After 30d of inactivity since
lifecycle/rottenwas applied, the issue is closed
You can:
- Mark this issue or PR as fresh with
/remove-lifecycle rotten - Close this issue or PR with
/close - Offer to help out with Issue Triage
Please send feedback to sig-contributor-experience at kubernetes/community.
/lifecycle rotten
The Kubernetes project currently lacks enough active contributors to adequately respond to all issues and PRs.
This bot triages issues according to the following rules:
- After 90d of inactivity,
lifecycle/staleis applied - After 30d of inactivity since
lifecycle/stalewas applied,lifecycle/rottenis applied - After 30d of inactivity since
lifecycle/rottenwas applied, the issue is closed
You can:
- Reopen this issue with
/reopen - Mark this issue as fresh with
/remove-lifecycle rotten - Offer to help out with Issue Triage
Please send feedback to sig-contributor-experience at kubernetes/community.
/close not-planned
@k8s-triage-robot: Closing this issue, marking it as "Not Planned".
In response to this:
The Kubernetes project currently lacks enough active contributors to adequately respond to all issues and PRs.
This bot triages issues according to the following rules:
- After 90d of inactivity,
lifecycle/staleis applied- After 30d of inactivity since
lifecycle/stalewas applied,lifecycle/rottenis applied- After 30d of inactivity since
lifecycle/rottenwas applied, the issue is closedYou can:
- Reopen this issue with
/reopen- Mark this issue as fresh with
/remove-lifecycle rotten- Offer to help out with Issue Triage
Please send feedback to sig-contributor-experience at kubernetes/community.
/close not-planned
Instructions for interacting with me using PR comments are available here. If you have questions or suggestions related to my behavior, please file an issue against the kubernetes/test-infra repository.
I'd love to work on that one, I've got a mostly working proof of concept for this
@sebltm: You can't reopen an issue/PR unless you authored it or you are a collaborator.
In response to this:
/reopen
Instructions for interacting with me using PR comments are available here. If you have questions or suggestions related to my behavior, please file an issue against the kubernetes/test-infra repository.