python
 python copied to clipboard
python copied to clipboard
Extremely slow deserialization due to lock contention and logging module
We are experiencing performance issues when doing API calls in many threads at the same time. The issue only occurs on certain clusters and we suspect it is happens when a high number of API calls occur simultaneously.
When looking at stack traces, we see contention around a lock in the logging module.
Thread XYZ (most recent call first):
File \"/usr/local/lib/python3.9/logging/__init__.py\", line 225 in _acquireLock
File \"/usr/local/lib/python3.9/logging/__init__.py\", line 1298 in getLogger
File \"/usr/local/lib/python3.9/logging/__init__.py\", line 2042 in getLogger
File \"/usr/local/lib/python3.9/site-packages/kubernetes/client/configuration.py\", line 112 in __init__
File \"/usr/local/lib/python3.9/site-packages/kubernetes/client/models/v1_container_image.py\", line 48 in __init__
File \"/usr/local/lib/python3.9/site-packages/kubernetes/client/api_client.py\", line 641 in __deserialize_model
File \"/usr/local/lib/python3.9/site-packages/kubernetes/client/api_client.py\", line 303 in __deserialize
File \"/usr/local/lib/python3.9/site-packages/kubernetes/client/api_client.py\", line 280 in <listcomp>
File \"/usr/local/lib/python3.9/site-packages/kubernetes/client/api_client.py\", line 280 in __deserialize
File \"/usr/local/lib/python3.9/site-packages/kubernetes/client/api_client.py\", line 639 in __deserialize_model
File \"/usr/local/lib/python3.9/site-packages/kubernetes/client/api_client.py\", line 303 in __deserialize
File \"/usr/local/lib/python3.9/site-packages/kubernetes/client/api_client.py\", line 639 in __deserialize_model
File \"/usr/local/lib/python3.9/site-packages/kubernetes/client/api_client.py\", line 303 in __deserialize
File \"/usr/local/lib/python3.9/site-packages/kubernetes/client/api_client.py\", line 280 in <listcomp>
File \"/usr/local/lib/python3.9/site-packages/kubernetes/client/api_client.py\", line 280 in __deserialize
File \"/usr/local/lib/python3.9/site-packages/kubernetes/client/api_client.py\", line 639 in __deserialize_model
File \"/usr/local/lib/python3.9/site-packages/kubernetes/client/api_client.py\", line 303 in __deserialize
File \"/usr/local/lib/python3.9/site-packages/kubernetes/client/api_client.py\", line 264 in deserialize
File \"/usr/local/lib/python3.9/site-packages/kubernetes/client/api_client.py\", line 192 in __call_api
File \"/usr/local/lib/python3.9/site-packages/kubernetes/client/api_client.py\", line 348 in call_api
File \"/usr/local/lib/python3.9/site-packages/kubernetes/client/api/core_v1_api.py\", line 16517 in list_node_with_http_info
File \"/usr/local/lib/python3.9/site-packages/hikaru/model/rel_1_16/v1/v1.py\", line 46011 in listNode
... application specific stuff
The above is from a single thread. Each stack trace contains about 20 threads like that, all stuck on different API calls in the client library, all waiting in _acquireLock. (There are several paths to _acquireLock - it's not just getLogger but also functions like _clear_cache(), setLeve() etc.)
Is there a fundamental reason why deserializing a Kubernetes object must involve a call to getLogger() and other logging functions?
If not, it would be great to improve the performance here and allow not calling any lockful logging functions during deserialization.
The Kubernetes project currently lacks enough contributors to adequately respond to all issues and PRs.
This bot triages issues and PRs according to the following rules:
- After 90d of inactivity,
lifecycle/staleis applied - After 30d of inactivity since
lifecycle/stalewas applied,lifecycle/rottenis applied - After 30d of inactivity since
lifecycle/rottenwas applied, the issue is closed
You can:
- Mark this issue or PR as fresh with
/remove-lifecycle stale - Mark this issue or PR as rotten with
/lifecycle rotten - Close this issue or PR with
/close - Offer to help out with Issue Triage
Please send feedback to sig-contributor-experience at kubernetes/community.
/lifecycle stale
The Kubernetes project currently lacks enough active contributors to adequately respond to all issues and PRs.
This bot triages issues and PRs according to the following rules:
- After 90d of inactivity,
lifecycle/staleis applied - After 30d of inactivity since
lifecycle/stalewas applied,lifecycle/rottenis applied - After 30d of inactivity since
lifecycle/rottenwas applied, the issue is closed
You can:
- Mark this issue or PR as fresh with
/remove-lifecycle rotten - Close this issue or PR with
/close - Offer to help out with Issue Triage
Please send feedback to sig-contributor-experience at kubernetes/community.
/lifecycle rotten
py-spy screenshoot

from kubernetes import client
from os import getenv
from time import sleep
configuration = client.Configuration()
configuration.api_key_prefix['authorization'] = 'Bearer'
configuration.api_key['authorization'] = getenv('TOKEN') or ''
configuration.host = getenv('HOST') or ''
configuration.verify_ssl = False
import urllib3
urllib3.disable_warnings(urllib3.exceptions.InsecureRequestWarning)
with client.ApiClient(configuration) as api_client:
core_v1 = client.CoreV1Api(api_client)
for i in range(1, 20001):
secrets = core_v1.list_secret_for_all_namespaces().items
~1000 TLS secrets
Here's a solution, just hack out the lines in the rest.py file that is the root of all evil in a dockerfile during build:
find /usr/local/lib/python*/dist-packages/kubernetes/client/rest.py -type f -exec sed -i 's:^\(.*logger.*\)$:#\1:' {} \;
Hey @roycaihw - we ran a benchmark on our pod to quantify the memory leak from this bug if you run an infinite loop for 5 minutes calling K8s API over and over and over, our Pod went from 200 MB base to 38 GB of memory spill:
t=0

t=5 mins
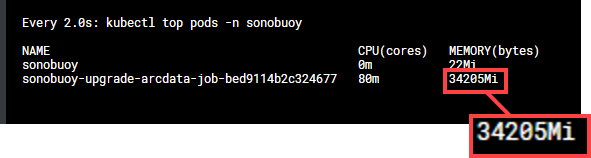
This was Sonobuoy running on an AKS cluster, but I'm sure it's reproducible on GKE as well.
This pretty much makes the Python client unusable.
If you just run an infinite loop inside a Kubernetes Pod and run malloc, you will see the same behavior.
Here's a quick script you can run to get at the culprit in the rest.py:
import gc
import tracemalloc
tracemalloc.start(25)
while True:
print(f"Duration elapsed: {delta}/{timeout} seconds, interval of {interval} seconds.")
# ++++++++++++++++++++++++++++++++++++++++++++++++++++++++
# >>>>>>>>>>> Make some K8s API calls here <<<<<<<<<<<<<<
# ++++++++++++++++++++++++++++++++++++++++++++++++++++++++
snapshot = tracemalloc.take_snapshot()
top_stats = snapshot.statistics('lineno')
print("[ Top 10 ]")
for stat in top_stats[:10]:
print(stat)
top_stats = snapshot.statistics('traceback')
stat = top_stats[0]
print("%s memory blocks: %.1f KiB" % (stat.count, stat.size / 1024))
for line in stat.traceback.format():
print(line)
This is what you'll see, the Python Kubernetes client starts guzzling up RAM:
========================================================================
[ Top 10 ]
/usr/lib/python3.8/logging/__init__.py:1088: size=268 MiB, count=1373, average=200 KiB # <-------------------- CULPRIT
/usr/lib/python3.8/logging/__init__.py:373: size=134 MiB, count=240, average=571 KiB # <-------------------- CULPRIT
/usr/local/lib/python3.8/dist-packages/kubernetes/client/rest.py:229: size=134 MiB, count=240, average=571 KiB # <-------------------- CULPRIT
/usr/lib/python3.8/linecache.py:137: size=785 KiB, count=7484, average=107 B
/usr/lib/python3.8/logging/__init__.py:294: size=267 KiB, count=1366, average=200 B
/usr/lib/python3.8/tracemalloc.py:185: size=225 KiB, count=1001, average=230 B
/usr/lib/python3.8/tracemalloc.py:479: size=55.2 KiB, count=1002, average=56 B
/usr/lib/python3.8/logging/__init__.py:608: size=48.9 KiB, count=686, average=73 B
/usr/lib/python3.8/tracemalloc.py:472: size=39.5 KiB, count=1002, average=40 B
/usr/lib/python3.8/posixpath.py:145: size=38.4 KiB, count=685, average=57 B
========================================================================
24 memory blocks: 36462.6 KiB
monitorstacks = get_latest_custom_resource_list(
File "/tests/util.py", line 851
latest_crd = get_latest_custom_resource_definition(group, kind)
File "/tests/util.py", line 873
for crd in get_latest_custom_resource_definitions()
File "/tests/util.py", line 893
for x in api.list_custom_resource_definition().to_dict()["items"]
File "/usr/local/lib/python3.8/dist-packages/kubernetes/client/api/apiextensions_v1_api.py", line 624
return self.list_custom_resource_definition_with_http_info(**kwargs) # noqa: E501
File "/usr/local/lib/python3.8/dist-packages/kubernetes/client/api/apiextensions_v1_api.py", line 731
return self.api_client.call_api(
File "/usr/local/lib/python3.8/dist-packages/kubernetes/client/api_client.py", line 348
return self.__call_api(resource_path, method,
File "/usr/local/lib/python3.8/dist-packages/kubernetes/client/api_client.py", line 180
response_data = self.request(
File "/usr/local/lib/python3.8/dist-packages/kubernetes/client/api_client.py", line 373
return self.rest_client.GET(url,
File "/usr/local/lib/python3.8/dist-packages/kubernetes/client/rest.py", line 241
return self.request("GET", url,
File "/usr/local/lib/python3.8/dist-packages/kubernetes/client/rest.py", line 232
logger.debug("response body: %s", r.data) # <-------------------- CULPRIT
File "/usr/lib/python3.8/logging/__init__.py", line 1434
self._log(DEBUG, msg, args, **kwargs)
File "/usr/lib/python3.8/logging/__init__.py", line 1589
self.handle(record)
File "/usr/lib/python3.8/logging/__init__.py", line 1599
self.callHandlers(record)
File "/usr/lib/python3.8/logging/__init__.py", line 1661
hdlr.handle(record)
File "/usr/lib/python3.8/logging/__init__.py", line 954
self.emit(record)
File "/usr/local/lib/python3.8/dist-packages/_pytest/logging.py", line 342
super().emit(record)
File "/usr/lib/python3.8/logging/__init__.py", line 1088
stream.write(msg + self.terminator)
========================================================================
This should be a trivial feature for a widely adopted community tool (don't cause massively instable memory leaks), we have the one-liner hack I mentioned above to just comment out the buggy debugging code in rest.py, but ideally this should be fixed in the source code.
the issue was reported back in 2019 https://github.com/kubernetes-client/python/issues/836 and became rotten without any reply I also looked into this because of the memory issue. it's not AKS specific. and it's not bound to the python version used.
The Kubernetes project currently lacks enough contributors to adequately respond to all issues.
This bot triages un-triaged issues according to the following rules:
- After 90d of inactivity,
lifecycle/staleis applied - After 30d of inactivity since
lifecycle/stalewas applied,lifecycle/rottenis applied - After 30d of inactivity since
lifecycle/rottenwas applied, the issue is closed
You can:
- Mark this issue as fresh with
/remove-lifecycle stale - Close this issue with
/close - Offer to help out with Issue Triage
Please send feedback to sig-contributor-experience at kubernetes/community.
/lifecycle stale
@mdrakiburrahman what's the memory usage if you apply that patch vs without it?
@mdrakiburrahman what's the memory usage if you apply that patch vs without it?
With the hack patch, about ~200 MB - steady, as expected for my pod.
Without the hack patch, starts climbing, I've seen it go up to 40 GB+ (I removed limits to see how bad the damage can be, it's bad.).
The Kubernetes project currently lacks enough contributors to adequately respond to all issues.
This bot triages un-triaged issues according to the following rules:
- After 90d of inactivity,
lifecycle/staleis applied - After 30d of inactivity since
lifecycle/stalewas applied,lifecycle/rottenis applied - After 30d of inactivity since
lifecycle/rottenwas applied, the issue is closed
You can:
- Mark this issue as fresh with
/remove-lifecycle stale - Close this issue with
/close - Offer to help out with Issue Triage
Please send feedback to sig-contributor-experience at kubernetes/community.
/lifecycle stale