fairing
 fairing copied to clipboard
fairing copied to clipboard
Better Tekton support (possibly replace ClusterBuilder)
/kind feature
A common task for fairing Kubeflow is building docker images in cluster.
Right now we use ClusterBuilder and some of the other libraries to do this.
I wonder if it might not be better to offer Tekton as an option.
In kubeflow/examples#723 I'm creating an E2E example for mnist that runs inside Jupyter on Kubeflow. This needs to build a bunch of Docker images and is currently using Cluster Builder.
Here's how this might work using Tekton
- We provide utilities for producing a context to pass to Kaniko or some other builder
- On GCP this amounts to creating a tarball and uploading it to GCS
- We define in YAML the spec for the Tekton task to run Kaniko
- We launch the Tekton task using some python utilities like apply_k8s_specs mentioned in kubeflow/fairing#453
I find the ClusterBuilder to be doing a lot of magic that can get in the way; e.g. it tries to autogenerate Dockerfiles and makes other assumptions about context.
I think it might be simpler just to give people Tekton and some other low level tools (like routines for creating contexts on GCS, S3, etc...) rather than reverse engineer the magic in fairing.
The other advantage of Tekton is that it has a lot of built in support that could be useful. For example, we can leverage Tekton's git support to easily support the use case where people build from git rather than a context.
Issue-Label Bot is automatically applying the labels:
| Label | Probability |
|---|---|
| feature | 0.98 |
Please mark this comment with :thumbsup: or :thumbsdown: to give our bot feedback! Links: app homepage, dashboard and code for this bot.
+1.
Given the overall wide array of tasks in Kubeflow which are being done using Tekton, including CI/CD, it will make sense to use it as a common tooling where we have common scenarios which require build et all be handled by Tekton, and leverage wide support of features which Tekton provides to expose Kube native resources.
cc @jinchihe
Im new to this project, but I have a bunch of experience with Tekton. Id love to be assigned this one, as a way to get better oriented with this project :)
@iancoffey sorry for later. Yeah, any process from your sides already done? I also started investigating with @mochiliu3000 for this, as for as know, @mochiliu3000 did a design for this for reviewing now.
@jlewi In fact, I have some concerns about this:
- If so, user needs to install Tekton CRD in clusters, this may increase user time overhead and complexity, may not be good for user experience. And for some user envionment, User cannot install CRD without Cluster Admin agreement.
- If user define YAML, user may like to use the Tekton directly, If only use Fairing to apply the YAML, seems it's bit extra circle.
- User may has ML code, just want to build a image quickly, do not like to learn Tekton and Kaniko, user only want to inputs the ML script path and base image etc... If we use Tekton, better to encapsulate Tekton (generate YAML?) and Kaniko for good user experience.
I admit the advantage of Tekton is support more build source such as git, but we may implement that for Cluster build.
If we decide to implement that, I suggest keeping the Cluster Builder, user can choose that.
I got some idea for this and made a simple design. From my understanding, fairing ClusterBuilder now deploys job in 4 steps:
- Initiate: Gather runtime config, initiate preprocessor, builder and deployer
- Preprocess: Wrap training code, generate build context and upload build context to PV or S3, GCS...
- Build and Push: Build image with build context and push image to registry in a Kanico container
- Deploy: Pull the image and deploy job to another cluster using K8S API. Keep tracking the job running status
The problem is which steps are better to run in container, not on local machine and can be standardized as Tekton tasks. I am thinking maybe No.2 and No.3. We may create PV to mount user's training code and ConfigMaps to store user's docker config and remote K8S config during initiation. Then we mount them to a Tekton task to do preprocess, and then give the context to another Tekton task to build and push image. For deployment, run it in container or locally seems make no difference. By re-writing preprocess as a Tekton task, we can better support training code sources like Github. By re-writing build and push as a Tekton task, we may simplify the code with yaml templates.
Agree with @jinchihe that Tekton and Kanico are better to be encapsulated and not exposed directly to user. As I am new to Tekton, please comment and do correct me if I'm wrong. Thanks!
If so, user needs to install Tekton CRD in clusters, this may increase user time overhead and complexity, may not be good for user experience. And for some user envionment, User cannot install CRD without Cluster Admin agreement.
Couldn't we just install Tekton when we deploy Kubeflow?
If user define YAML, user may like to use the Tekton directly, If only use Fairing to apply the YAML, seems it's bit extra circle.
So fairing is currently creating a K8s Job. https://github.com/kubeflow/fairing/blob/e0d44e870b467bbd773f836a8b1b648b79019dd1/kubeflow/fairing/builders/cluster/cluster.py#L82
So one way to think about is it should we use a K8s Job or a Tekton Task? You could still wrap it in whatever python SDK you want to provide a higher level API.
I think a Tekton task is preferable because
i) It is parameterizable ii) Comes with built in support for git
I think to @mochiliu3000 's point I think ClusterBuilder is doing a lot of things today; e.g. it is generating a Dockerfile, preprocessing the files, and then preparing a context.
When this works its great but often times I find its too magical and reverse engineering it is complicated.
So I think there are two separate issues being discussed here
i) Should we use Tekton Tasks as opposed to K8s Jobs to execute in cluster builds? ii) Is ClusterBuilder doing too many things? Should we replace ClusterBuilder with lower level functions that a user would chain together? (e.g. preprocess, build_context, launch_build)?
i) Should we use Tekton Tasks as opposed to K8s Jobs to execute in cluster builds?
I picture Tekton fitting nicely as an additional, optional Builder and not a wholesale replacement for the simpler ClusterBuilder Job based builder - which will still be very useful to have. As an optional builder, it could be possible to have no hard dependency on Tekton being installed on cluster, if the user does not need it.
Some workloads will not need the horsepower Tekton brings - but it would be great for production workflows to be able to specify a Tekton builder.
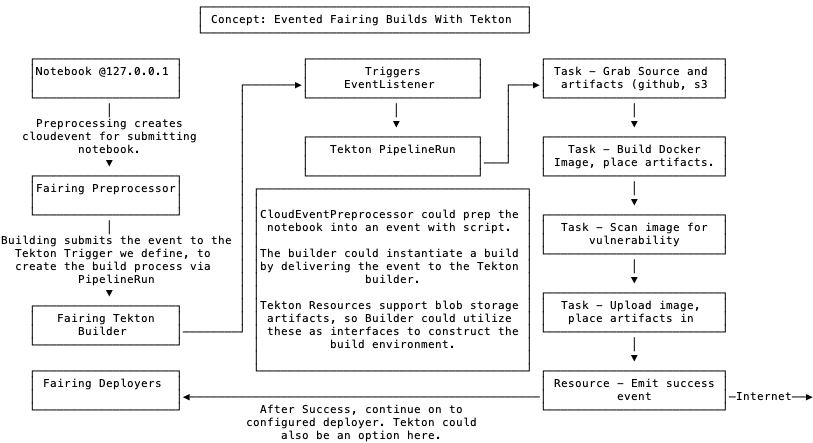
As for integration, I think the Tekton Triggers project opens a lot of interesting options here for instantiating builds from notebooks hosted anywhere. It is possible to integrate an event-style building architecture and fetch resources from contexts and build them remotely, with the tools we already have. I helped propose the Triggers project and always envisioned this sort of integration.
As an aside, I think the generic name ClusterBuilder is not helpful in this context. I think it would be beneficial for the builders to be named something more scoped, like: JobBuilder, TektonBuilder, etc.
Im going work on a diagram of this concept, I would love input on these thoughts!
@iancoffey Thanks. so user define the Tekton YAML and and then use fairing to submit them no notebook? if so, seems not much efforts needed, just use below function to apply namespaced objects (if have cluster object, we need to enhance the function or implement new one).
https://github.com/kubeflow/fairing/blob/6717b3d3806c8093adf1186bc819ad887238f287/kubeflow/fairing/kubernetes/manager.py#L407
@jinchihe Directly submitting TaskRuns/PipelineRuns via apply_namespaced_objects is one integration option, but another (imo more flexible) option would be to treat the EventListener as the interface between the fairing and the build system. In this scenario, what happens on the other end of the Trigger is sort of behind the curtain - it could create a bunch of a resources and a PipelineRun, or just run our default TaskRun with Kaniko (or other).
In this instance, Fairing could submit CloudEvents with the processed script and artifact references as the body contents. So I suppose it comes down to whether to integrate with Tekton Pipelines directly or to integrate with Tekton Triggers - and Im proposing exploring Triggers first due to it being low hanging fruit (and very interesting too imo). Would it be useful for me to create a POC of this?
Great thanks! @iancoffey Yeah, that's very useful if have a POC for the implement plans. And I suggest keeping the current Builder and Deployer, as far as I know, there are some users are taking the Builder, instead of replacing it, we should do it incrementally.
@iancoffey Nice diagram. It is good to have an event-style builder that maps
field and configuration of online event using Tekton Triggers.
I've also made a simple Tekton clusterbuilder pipeline here following Kubeflow CD. It uses kustomize to instantiate builds and it is trivial to map build configuration. Is there a way to also use event and trigger for local build and local context? I think this event-style builder can help better moniter the pipeline status right? Looking forward to seeing the POC.
Thanks @iancoffey I think there are a lot of potential integration points between Tekton Triggers and Kubeflow (possibly kubeflow/kfp-tekton#82). We have started to use Tekton to make certain ML tasks repeatable e.g. running a notebook and uploading its output as HTML (kubeflow/testing#613).
I opened this issue though less about the underlying implementation (e.g. Triggers vs. calling APIServer) vs. directly calling the K8sAPIServer and more about the user facing API.
One of the big motivations for fairing was to create a more idiomatic python experience that would be familiar to datascientists and not force datascientists to learn about K8s. So we created an API consisting of
- Preprocessors
- Builders
- Deployers
The question I'm wondering is whether those abstractions are proving valuable or if they just end up getting in the way?
This is also not a one size fits all.
@jinchihe added a bulk apply.
So given that method it should be fairly easy for users (or Kubeflow) examples to start using Tekton to launch builds.
It looks to me like the big pieces would be
- Integrating Tekton into the KF install process so that users have it available
- Starting to build a catalog of useful tasks (e.g. for the ones @mochiliu3000) created.
@animeshsingh you have been driving a lot of the work around Tekton and Kubeflow; WDYT?
Is there a way to also use event and trigger for local build and local context? I think this event-style builder can help better moniter the pipeline status right? Looking forward to seeing the POC.
Yes, one big plus to this via this event-driven build system is that it does not matter where the Tekton cluster is located - locally on microk8s will work identically to a large production cluster. This is invaluable for keeping dev->staging->production pipelines sane and stable. This would also avoid having to mess with kubeconfig/rbac access things for every user who just wants a build.
This also introduces a really nice separation of concerns, where data scientists do not interact with k8s or Tekton at all while building images, and k8s administrators have a clear boundary to work with and sane environment to troubleshoot with.
Anothet thing - what exactly happens on the other end during the build process (pipelines/tasks/resources) can be customized without any modification to Fairing or notebooks. To me, this feels like a big long-term advantage.
I opened this issue though less about the underlying implementation (e.g. Triggers vs. calling APIServer) vs. directly calling the K8sAPIServer and more about the user facing API.
Is there another issue where implementation should be discussed, or a document somewhere with more words on the greater Tekton related plans?
One of the big motivations for fairing was to create a more idiomatic python experience that would be familiar to datascientists and not force datascientists to learn about K8s.
Regarding Tekton, moving away from the pattern of fairing directly spawning/managing tekton resources and toward a pattern of making use of standard data structures and existing resources is great way to achieve this. If Fairing had the ability to instantiate builds by sending (relatively) small bits of notebook data and having it auto-populate, create and execute predefined resources - then the interface between fairing and tekton becomes simpler, and reproducible. Data scientist would not need to care about (or even have access to) to the clusters running the builds and users could even sanely share the same Tekton infrastructure by referencing a single eventlistener interface to fulfill the needs of many data scientists. Users gain task/pipeline(run)/resource templating. The prod k8s cluster administrators should also get a saner experience.
So I think easier is maybe not the best metric - it will surely be faster to just submit some yaml into k8s_client and move on - but thinking more about this as a system for both data scientists and data engineers to use for production systems - pursuing a more decentralized and flexible/template-able solution seems like a viable solution.
The question I'm wondering is whether those abstractions are proving valuable or if they just end up getting in the way?
Ive no strong feelings here, the existing interface works this context. If there was more data around where it falls down, maybe that could inform a proposal.
Ill keep pulling on this thread of a poc and see where this all goes, while this discussion evolves. thanks all!
its an interesting discussion - will take a step back and point to few things, which have come up many times
- Fairing providing abstractions for data scientists to do some common tasks, which can be executed on a remote cluster - the concept itself is a bit overlapping with Kubeflow Pipelines and KFP Python SDK. The work we are doing here https://github.com/kubeflow/kfp-tekton essentially is integrating Python DSL for KFP with Tekton backend.
So high level question which keeps coming back to me is why not extend the KFP SDK, given its the most widely adopted for to provide these helper functions? Will make our story simpler and frankly remove duplication. Orthogonal to the discussion here, but keeps coming back to me. But for rest of the discussion, lets assume its needed...
-
Triggers are typically more useful when you have a producer/subscriber model, and typically when there are "multiple" subscribers who need to act on "one" trigger or action. Using them as as a "boundary" between a caller and backend will only make sense if are relying on multiple subscribers . Also fwiw, logging and ensuring logs are coming back while backend execution is going has always been problematic if we introduce eventing in between
-
Catalog: We have built an internal 'Components Registry' using components.yaml which defines KFP components. Planning to extend that to include Tekton tasks as well, so as to have one task registry where you can pull lower level tekton tasks for ci/cd functionalities, or higher level kfp 'components' for ML/AI tasks.