human-learn
 human-learn copied to clipboard
human-learn copied to clipboard
Idea for a simple rule based classifier
Ideas for a rule based classifier after discussion with
@koaning: The hope with that idea is that you can define case_when like statements that can be used as a rule based system.
This has a few benefits.
- It's simple to create for a domain person.
- It's possible to create a ui/webapp for it.
- You might even be able to generate SQL so that the ML system can also "be deployed" in a database.
This classifier would not have the full power of Python, but is rather a collection of rules entered by domain experts who are not necessarily technical people.
Rules
Rules have no structure and are always interpreted as disjunctions (or) and can be composed of conjunctions (and). To resolve conflict they can have a simple priority field.
Format of the rules could be
term:
feature_name op value
op: '=', '<>', '<', '>', '<=', '>='
expr: term
| term 'and' term
rule : term '=>' prediction (prio)?
Examples
- age < 60 => low
- sex = 'f' and fare <> => high 10
Rules need not be expressed as plain text, but also a structured format of nested lists/arrays. A parser for a text format like this would be possible with a very simple recursive descent parser.
API
class ClassifierBase:
def predict(self, X):
return np.array([ self.predict_single(x) for x in X])
def predict_proba(self, X):
return np.array([probas[xi] for xi in self.predict(X)])
def score(self, X, y):
n = len(y)
correct = 0
predictions = self.predict(X)
for prediction, ground_truth in zip(predictions, y):
if prediction == ground_truth:
correct = correct + 1
return correct / n
class CaseWhenClassifier(ClassifierBase):
def predict_single(self, x):
...
def .from_sklearn_tree(self, tree):
...
def .to_sklearn_tree(self):
...
def to_python_code(self, code_style):
...
def parse(self, rules_as_text):
...
rules = ...
rule_clf = CaseWhenClassifier(features, categories, rules)
Debugging support for plotting pairwise decision boundaries would be helpful.
I'm wondering if it makes sense to make a distinction between rule-based systems. In my mind, there are two kinds of systems possible when we consider trees.
Case When
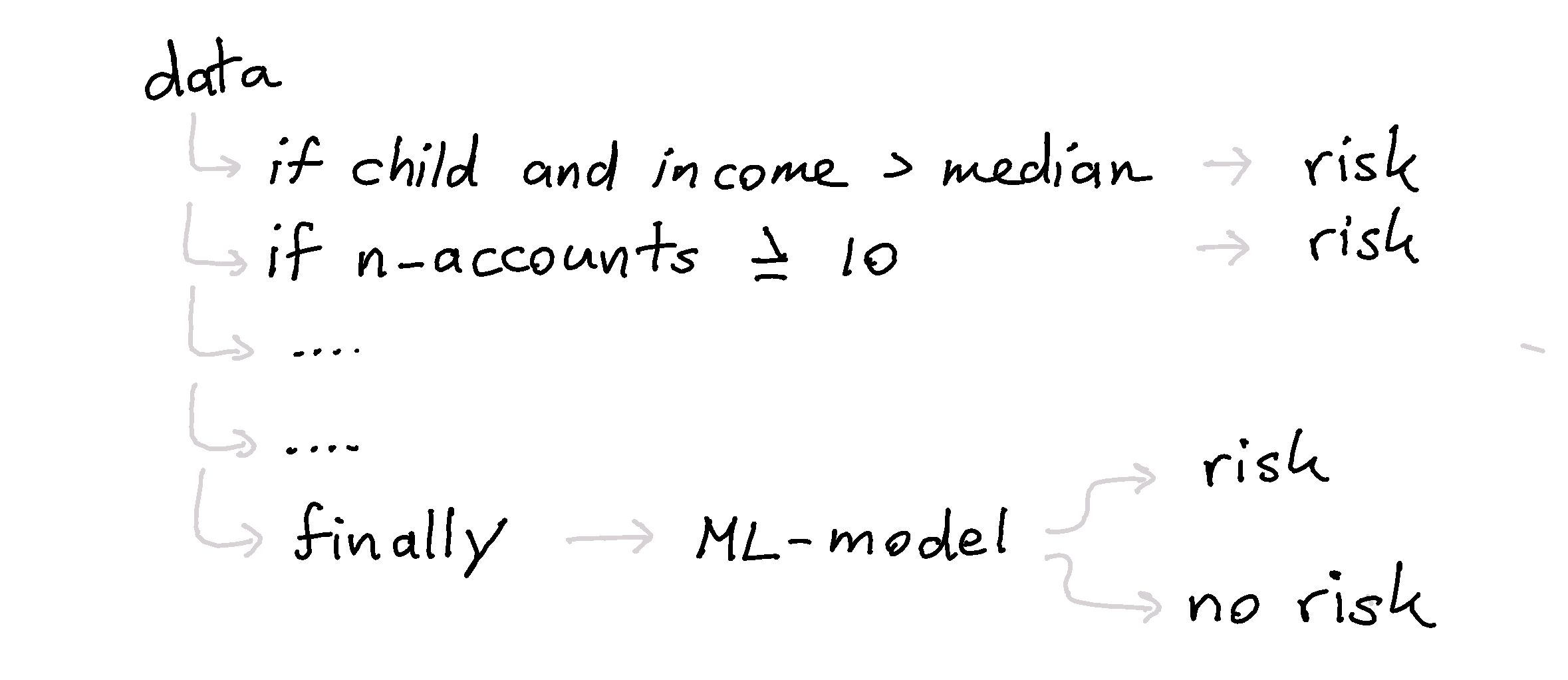
Tree When
Differences
Both systems are trees. However, the case_when is a particular type of tree. There is one branch that goes quite deep and has many leaves, but each leaf does not become a tree of its own. There are a few benefits.
- The
case_whenapproach is much easier to understand. Deep trees are technically interpretable, but they are not comprehensible. The case-when tree on the other hand will maintain an overview of sorts. - The
case_whenapproach is much easier to declare. In my experience, it's usually easier to pinpoint subsets of your data for which clear rules apply than it is to construct a tree that covers all of your data. - The
case_whenapproach is much easier to tweak in production. If we've ever introduced a bad leaf, it's easy to remove.
I'm curious, what's your take on this? There's something to be said to make a distinction between these two classes of trees at the user-interface level. But I'm curious if I'm missing something.
A minor comment: your operators ('=', '<>', '<', '>', '<=', '>=') seem sound, but should we perhaps add a is in operator as well so that we may accommodate non-numeric features as well?
I'm wondering if it makes sense to make a distinction between rule-based systems. In my mind, there are two kinds of systems possible when we consider trees.
Case When
Tree When
Differences
Both systems are trees. However, the
case_whenis a particular type of tree. There is one branch that goes quite deep and has many leaves, but each leaf does not become a tree of its own. There are a few benefits.
- The
case_whenapproach is much easier to understand. Deep trees are technically interpretable, but they are not comprehensible. The case-when tree on the other hand will maintain an overview of sorts.- The
case_whenapproach is much easier to declare. In my experience, it's usually easier to pinpoint subsets of your data for which clear rules apply than it is to construct a tree that covers all of your data.- The
case_whenapproach is much easier to tweak in production. If we've ever introduced a bad leaf, it's easy to remove.I'm curious, what's your take on this? There's something to be said to make a distinction between these two classes of trees at the user-interface level. But I'm curious if I'm missing something.
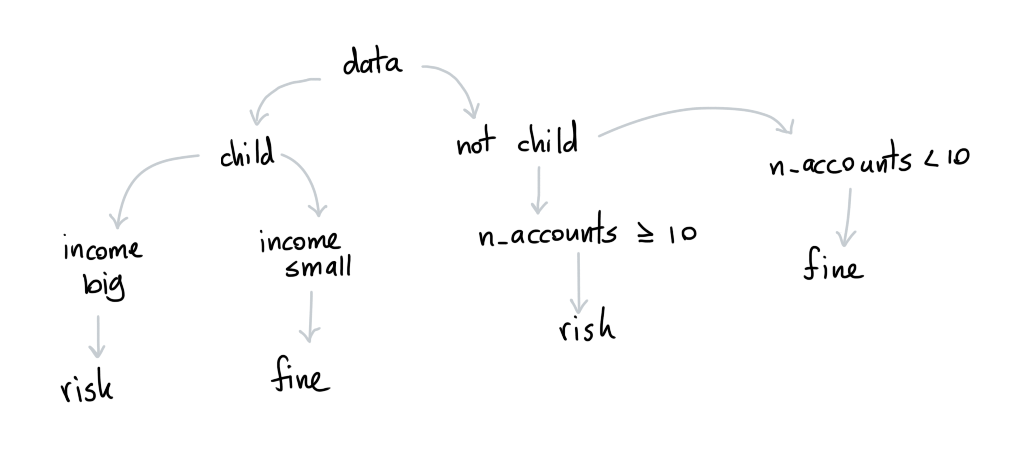
I guess technically one can be transformed to the other and I also have some code that spits out both representations and also a third one from any decision tree. So it boils down to user interface. While both would be possible even there, I do not see non-technical people being able to create what you describe as "tree when". The third representation I was talking might be worth considering, though. It goes like: like case-when but have all the possible rules that will lead to a certain prediction batched up at one place and not scattered around.
A minor comment: your operators ('=', '<>', '<', '>', '<=', '>=') seem sound, but should we perhaps add a
is inoperator as well so that we may accommodate non-numeric features as well?
in could be expressed with a combination of terms, but I also like the in as a convenience operator.
I guess technically one can be transformed to the other ...
Yeah, the underlying implementation should certainly be done by a parent class. But a long-term plan for this library is to add a user-interface so that folks may more easily declare rules. With that in mind, I might prefer child classes that might make a distinction.
It goes like: like case-when but have all the possible rules that will lead to a certain prediction batched up at one place and not scattered around.
Is it possible to make a conceptual drawing of this? Jjust make sure we'll be talking about the same thing, I often find pictures say more than words.
I guess technically one can be transformed to the other ...
Yeah, the underlying implementation should certainly be done by a parent class. But a long-term plan for this library is to add a user-interface so that folks may more easily declare rules. With that in mind, I might prefer child classes that might make a distinction.
I meant, all three representations are equivalent, so internally it does not matter how we store the rules.
It goes like: like case-when but have all the possible rules that will lead to a certain prediction batched up at one place and not scattered around.
Is it possible to make a conceptual drawing of this? Jjust make sure we'll be talking about the same thing, I often find pictures say more than words.
my drawings tend to suck, but I tried:
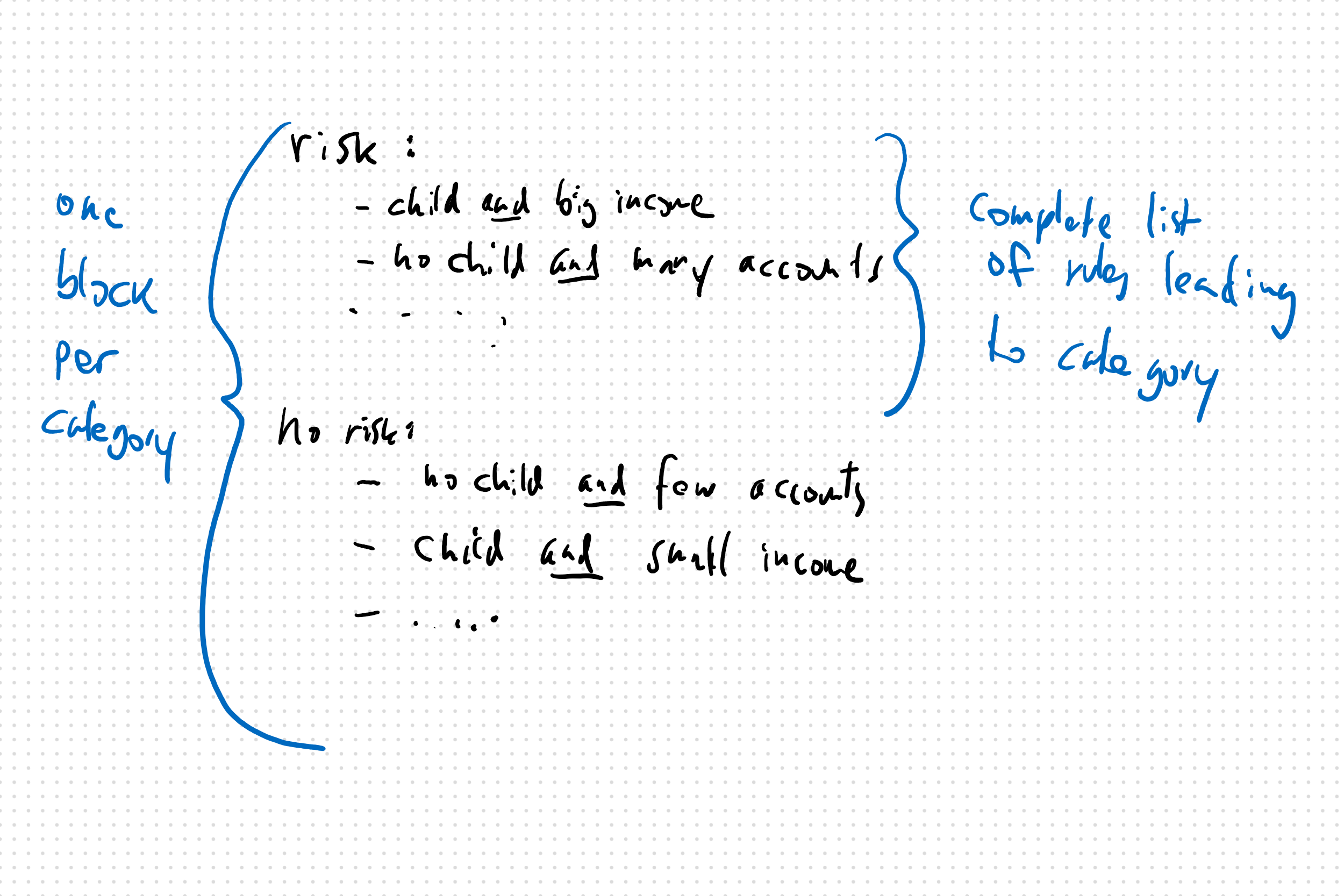
Have you thought about a pythonic API to declare these rules?
I tried doing something like this before.
clf = (Rules(dataf=df)
.casewhen(lambda d: d['age'] < 16 & d['income'], "risk")
.casewhen(lambda d: d['n_accounts'] >= 10, "risk"))
This kind of works in python. It's relatively clear to write but it's tricky to get it into a nice set of serialized rules because of all the lambdas.
We could also say, "let's just assume shallow sklearn trees for now and see if we can get that translated into SQL first". But I worry things will get nitty-gritty fast with all the SQL variants out there.
First thought: wouldn't this be somewhat inside of the fit method? Seems like sklearn has some thoughts about where a model learns, and this would be in fit, no?
Having Python Code for rules sounds off to me: If the author of rules can write Python, why noy just let them write arbitrary Python Code?
Also, as I mentioned: it is pretty straight forward to translate shallow rules in deep ones and the other way around, so I am sure we can generate SQL from any sort of tree representation.
Is it possible to make a conceptual drawing of this? Jjust make sure we'll be talking about the same thing, I often find pictures say more than words.
my drawings tend to suck, but I tried:
Just wondering Vincent, what tool do you use to make your awesomely simple drawings?
I thought about wipping something like this together, but then remembered to google first and found these libraries:
The library lets you define variables that business rules can act on, and the potential actions that can be taken, and then you define the actual business rules as a json file that can be executed:
https://github.com/venmo/business-rules
They then have this simple UI to generate the JSON files:
https://github.com/venmo/business-rules-ui
I was thinking of something similar but then having BusinessRules defined as python classes and then a RulesEngine that is scikit-learn compatible that consists of a collection of BusinessRules (either a list or a dictionary to define a tree like structure). You could then both export this to (engine.to_yaml("rules.yaml") and instantiate from yaml as a classmethod (RulesEngine.from_yaml("rules.yaml")) similar to what I did in the explainerdashboard library.
Then you would have to develop a UI on top of that to make it truly user friendly.
So I made a quick demo here: https://github.com/oegedijk/rule_estimator
It is a slightly different approach as the user would have to define classes instead of functions and then wrapping those functions in estimators.
For now you can define simple gt/ge/lt/le BusinessRules, string them together using CaseWhen, and define BinaryDecisionNodes.
@oegedijk there's some user interface elements that I am experimenting with in line with that you're suggesting, but with a slightly different vantage point. A first demo can be found as part of my csvconf talk. It starts at 40:00.
I think the problem isn't that we're not capable of translating casewhen-style domain rules into python. That's a syntax problem and that's solved. I think the problem lies more in the user interface, which is in-line with the ui demo, but it's not just the declaration of rules. It's two main issues:
- How can we make it easier for folks to discover meaningful rules? I really want a flow where exploratory data analysis can just become the model. Mental models still need to be challenged and visualisation seems like the best technique to have people learn from data. Less need for model explainability tools that way.
- How can we make a system that is expressive also for low tech people who cannot do python? It's not just case-when, but also selecting areas on a chart, parallel coordinates, maps and rules with aggregations.
I've got some ideas in this realm as well as small local demos, but nothing is ready for prime time just yet. There is one demo live though that I've made on behalf of my employer, Rasa, in case you're interested (check out the Bulk Labelling demo).