【Shader篇】Shader性能深入分析 - 知乎
1、前言
前文(GPU架构与其逻辑管线)分析了Shader的运行机制,并指出了与其性能相关的硬件单元 - 流多处理器(SM)。本篇文章将更具体地阐明Shader在SM中的执行流程,然后分析在这个流程中有哪些关键的性能因素,最后通过Debugger软件来分析Shader的性能瓶颈。接下来本文按这3部分顺序进行分析。
参考NVIDIA资料:Issue Efficiency 。
2、Shader执行流程
在启动一个Shader时,GPU会按启动配置把一个个Block分配给SM,SM又会将Block分成一个个Warp,然后由Warp调度器派发执行Shader的指令。这里以一次ComputeShader(以下简称CS)的调用,说明一下Shader的执行流程:
- CPU阶段,CPU侧调用Dispatch(GirdX,GirdY,GirdZ),让GPU启动 GirdX * GirdY * GirdZ 个Block(任务块);
- 定义每个Block的三维大小(在CS入口函数处使用[numthreads(GroupX,GroupY,GroupZ)]);
- 将CS的一个个Block负载均衡地分配给SM;
- SM把Block中的任务以32个为一组,封装成Warp,要注意的是,不同Block的任务不能混在一个Warp里;
- SM中的Warp调度器对Warp进行调度(丢到内核执行);
- 被调度到的Warp,会以SIMT & lock-step的形式执行;
2.1、第一步:Shader封装为Warp
首先,根据Shader定义的任务配置(Grid与Block),GPU将Shader任务组(Block)均衡分配给SM,然后每个SM会将拿到任务组再度转化为一个个Warp。每个Warp由32个GPU线程组成,这些GPU线程可以在同一时钟周期内执行相同的指令(SIMT),而这些指令正是从Warp绑定的Shader提供而来的。可以说Warp与硬件相关联,驱动内核执行Shader指令。
详细步骤:
- SM的 Block Slots 接收Blocks(Turing架构中64个Block Slots,Block数量不能超过该硬件上限);
- SM将每个Block以32个任务为一组划分成Warp,然后将得到的Warps放于Warp调度器的Warp Slots(Turing架构中每个调度器有256个Warp Slots,Warp数量不能超过该硬件上限);
- 完善Warp配置:每个Warp绑定任务组对应的Shader,即绑定该Warp的指令。
- 最后得到SM的Warp列表,总数为:每个Warp调度器的Warp数量总和。
- Warp里的32个任务以SIMT形式执行同一个Warp指令(即同一个Shader)。
2.2、第二步:执行Warp指令
在上一步中,SM得到了需要执行的Warp列表,该Warp列表将交由Warp调度器进行管理调度。
首先,Warp调度器会根据Warp的Stalled状态,标记该Warp为:StalledWarp或者EligibleWarp。
- Stalled Warp:Warp列表里因各种原因(下文再行分析)被阻塞的Warp;
- Eligible Warp:Warp列表里在下一个周期可以派发指令的Warp。
接下来,在每个周期中,每个Warp调度器会从EligibleWarp列表中选择一个Warp进行执行。被选中的Warp称为SelectedWarp。Warp调度器的调度策略通常采用GTO策略(即Greedy-Then-Oldest策略),即尽可能地连续地派发同一个Warp的执行,直到该Warp出现某条阻塞指令,此时该Warp将被标记为StalledWarp,Warp调度器会重新从EligibleWarp列表中选择等待时间最长的Warp作为新的SelectedWarp。
2.3、小结
SM的每个Warp调度器在每个周期会从自己的Eligible Warps中调度一个Warp进行派发,发出该Warp的一条或多条指令。这些被派发的Warp就叫Selected Warps,在当前周期的数量为[0 .. Warp调度器的数量]。故而当Warp调度器的Warps中不存在Eligible Warps时,相关的内核资源会处于空闲状态,这导致SM整体的指令派发效率下降。
所以,下文将进一步分析Stall原因,想办法提高EligibleWarp 数量或者占比。
3、优化理论
经过以上分析,我们可以得出结论:EligibleWarp是GPU性能的关键要素。为了提高计算性能,我们需要采取措施,增加EligibleWarp的数量,这样一来,每个周期内内核就可以得到足够的任务,从而提高计算性能。我们可以从两个方向思考:
- 增加SM中Warp的总数,那么EligibleWarp多少也会增加;
- 将StalledWarp转化为EligibleWarp,增加EligibleWarp数。
3.1、提高Warp的总数
参考NVIDIA资料:Achieved Occupancy。
在最佳情况下,内核执行中的活跃Warp数应该等于或接近理论上限。然而,如果调度器无法在Warp调度器之间均衡地调度,或者根本没有剩余的Warp调度出来填充内核,则实际的活跃Warp数量可能会大大低于理论占用率。根据NVIDIA官方的建议,每个Warp调度器至少应有8个活跃Warp。此外,更多的活跃Warp可以更有效地隐藏Warp的延迟,从而提高GPU的性能。
影响Warp数量的因素:
- Blocks per SM:每个SM只能接受固定上限的Blocks。这个限制会直接影响一个SM可以处理的Warp数量(例如,Warps=ceil(Blocks/32));
- Warps per SM:对于每个SM来说,每个Warp调度器能够接受固定上限的Warps;
- Registers per SM:每个SM有一定数量的寄存器可供分配给该SM内的所有线程。现代GPU每个SM通常配备几万个32位的寄存器,用于存储每个线程定义的变量、结构体等数据;
- Shared Memory per SM:在一个SM中,所有线程共享同一片共享内存。该内存存储对应Shader里使用关键字groupshared声明的变量。
Warp分配的优化:
- Block间负载均衡:如果不同block的执行时长不同,可能会导致某些block仍在执行,而另一些SM的block已经执行完成,处于空闲状态。不过,只要有足够的block,就可以启动新的block,这样并不会对性能产生太大的影响;
- Block内Warp负载均衡:在同一个Block分配给SM后,会被划分为一组组Warps。如果这些Warps的执行时长不同,就可能导致某些长时间的Warps占用了该Block的执行资源,使得该Block不能释放;
- Block数均衡:如果分配的Block数过少,则可能会导致某些SM空闲,从而影响整个GPU的性能。因此,需要采用合适的算法来保证Block的均衡分配,以此最大化GPU的利用率;
- Block大小合适:在划分Block的时候,Block的大小为32的倍数为宜,否则就会出现某个Warp的任务数不够32个而浪费性能的情况。
按照 NVIDIA 的建议,每个Block(线程组)的大小不应超过 512 线程。这个建议的背后考虑到的是过大的线程组会使用更多的资源,从而增加资源竞争的概率,导致性能下降。另外,我们不应该一味地追求大量的Warp。当使用Profiler查看 EligibleWarp 数量已足够时,我们可以适当增加 Shader 的复杂度,例如增加寄存器使用,合理整合 Shader 等。这样做可能会导致 Warp 数量适当地下降,但不会影响性能。
3.2、解决阻塞问题
我们可以通过优化掉Warps的阻塞,将Stalled Warp转换为Eligible Warp,从而提高Warp调度效率。我们先来分析一些常见的Warp阻塞类型,这里列举的原因是有一些交集的,我们重在理解就好:
- 管线繁忙(Pipeline Busy):管线指的是一条指令从开始到完成的整个流程。这个流程需要使用到一系列的硬件部件,包括各种计算单元(如FP32、SFU等)、LD/ST、纹理单元、分支控制单元等。例如,当一条指令执行需要使用纹理单元采样时,如果SM中的纹理单元都处于繁忙状态,则该条指令将不能派发,处于Stalled状态。
- 纹理繁忙(Texture):纹理子系统已完全被利用或有太多未完成的请求时,纹理单元处于不可用状态,故依赖于纹理单元的指令将处于Stalled状态。
- 常量缓存Miss(Constant):当常量缓存不存在所需的数据时,则该指令stalled,需要等到数据从GlobalMemory拉取。可以考虑修改访问模式,合并访存等方案。
- 获取指令(Instruction Fetch):SM中该Warp的指令需要拉取。
- 内存读写瓶颈(Memory Throttle):大量待处理的内存操作导致Stalled。这可以通过合并访存来优化,即减少内存操作次数,以此减轻内存处理单元的负载。
- 内存依赖(Memory Dependency):由于所需资源不可用或被完全利用,或者有太多内存请求未完成(FIFO队列满了),因此无法进行加载/存储。通过优化内存对齐和访问模式,可以在一定程度上减少内存依赖的阻塞。
- 线程组同步(Synchronization):当调用了线程同步函数,先执行到同步点的线程将Stalled等待其他线程。可以考虑修改线程组大小,以减轻同步负担。
- 执行依赖(Execution Dependency):指令所需的输入尚未准备就绪。通过增加指令级并行性,可以在一定程度上减少执行依赖性阻塞。
4、分析Shader性能
当出现指令阻塞时,GPU硬件支持对最重要的阻塞原因进行计数,然后会提供给各种Debugger软件进行Profile,以便分析GPU的性能瓶颈。本文使用NVIDIA Nsight Graphics(下载链接、Doc文档)进行Profile,评估前文分析的性能。
创建项目,Connect到UE进程,然后截帧,和RenderDoc一样,得到一系列绘制事件以及耗时。因为这部分不是本文重点,这里放一张图就不再赘述了,后文重点分析阻塞原因。
截帧示意图
接下来,通过菜单栏Frame Debugger->Shader Profiler,收集该帧的Shader信息,如下图:
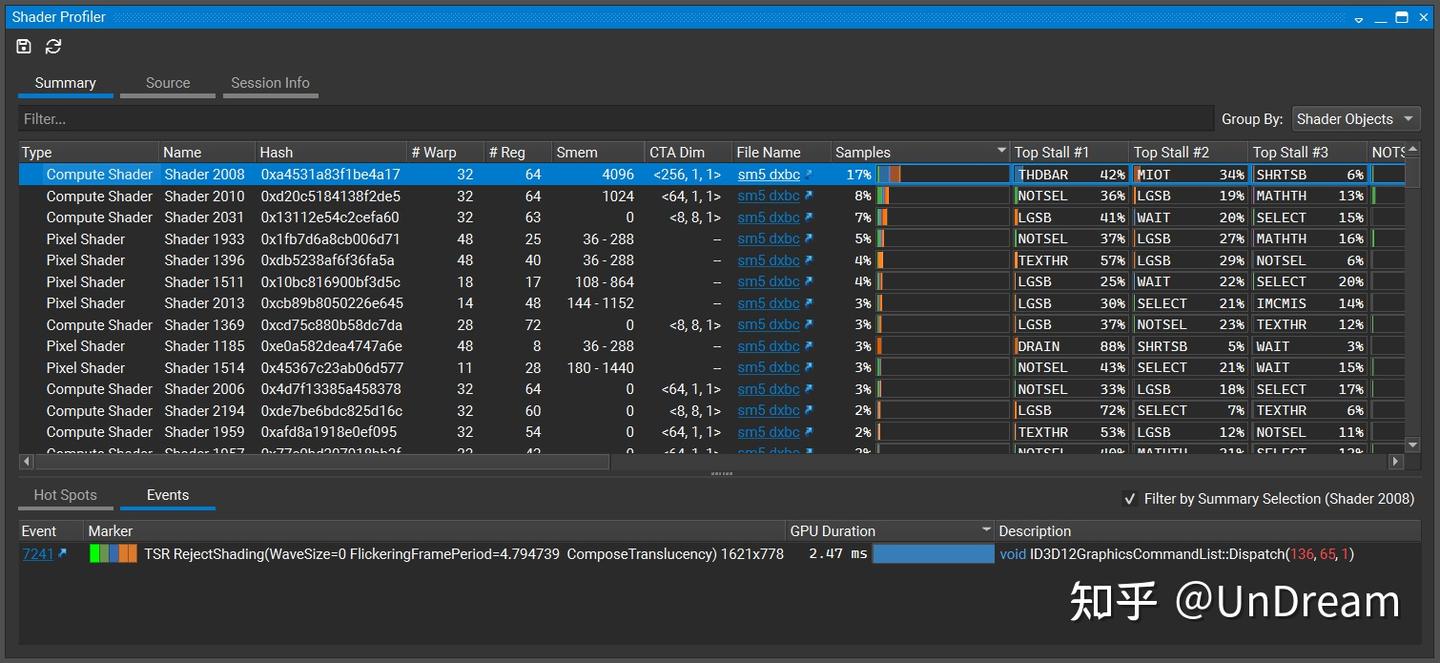
然后重点对Shader Profiler内容展开,分析Shader的阻塞原因以及优化方向。
4.1、# Warp
Shader对应的Warp数量,鼠标移到数字上面,可以显示详细的Limiter,如:
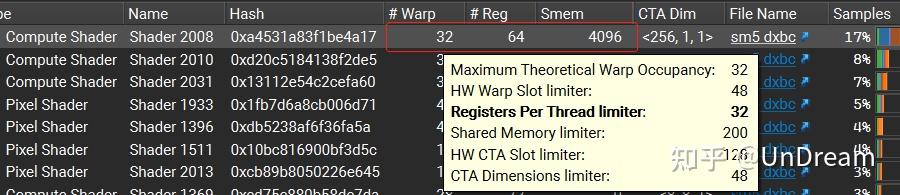
- Maximum Theoretical Warp Occupancy:最大理论占用,由以下limiter的最小值确定该值;
- HW Warp Slot limiter:硬件SM的Warp个数上限;
- Registers Per Thread limiter:根据该Shader使用寄存器个数整除可用寄存器总数得到;
- Shared Memory limiter:该Shader使用Smem整除可用共享内存得到;
- HW CTA Slot limiter:硬件SM的CTA(block)个数上限;
- CTA Dimensions limiter:CTA(block)的size限制。比如其他各项理论为32个,CTA大小计算得到16个,那么可以使用2个CTA,即得32个理论上限;但是如果CTA大小计算得17个Warp,那么容不下2个CTA=34>32,故只能1个CTA,即得理论上限只有17个。
- 3D Attribute Size limiter:渲染时需要的位置、法线、颜色等3D Attribute参数。
利用该调试信息,我们可以进行Warp调度优化(增加Warp数量)。如果Warp的数量过少,需要分析其瓶颈因素,并实施相应的优化措施,以提高Warp的调度效率。
4.3、# Reg(寄存器数量)
可以查看Shader使用了多少个寄存器,如果其Warp数量过少,且寄存器数量为**# Warp**项的瓶颈,那么可以针对寄存器使用进行优化,从而增加Warp数量。
5.3、Smem
共享内存,包括静态共享内存和动态共享内存。静态共享内存通过关键字 groupshared 来声明,其大小在编译期确定。比如大矩阵的计算,一般把该线程组的数据fetch到共享内存,然后计算存储中间结果,最后再一次性把结果写回global memory,这样可以减少对全局内存的访问次数,降低延迟。而动态共享内存类似于指针在运行时分配,如 groupshared float* shared_data; ,然后在运行时通过malloc申请,free释放。
4.4、CTA Dim(Block Dimension)
Compute Shader的线程组(Block)大小也是影响程序性能的一个关键因素。在确定线程组大小时,需要考虑其大小的合理性。通常建议线程组大小不要大于512个线程。如果存在比较多的线程同步,这时可以考虑减小线程组的大小,以减少组内同步的线程数量,提高Shader的性能。
4.5、Samples
NVIDIA的硬件对每种Warp阻塞原因进行了计数。NVIDIA Nsight Graphics工具可以从大量的Samples中统计某个Shader在该帧中阻塞的占比,并给出详细的阻塞原因占比情况:
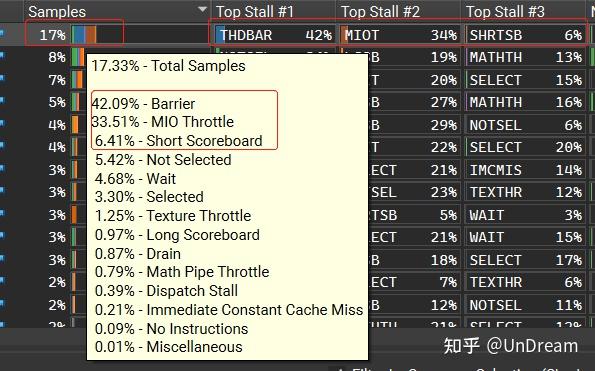
第一行的Shader占总Samples的17.33%,表明该Shader Stall时长占该帧的比例。鼠标移到上面之后,我们可以看到各类排名。在其右侧的Column显示了排名前3的Stall事件(Top Stall #1 2 3)。
- Barrier:线程组同步导致的阻塞,如果这项占比高,可以考虑把线程组改小,减轻同步负担;
- MIO Throttle:Multiple Input/Output瓶颈,它是处理多路数据输入输出的单元。其接收的请求来源包括local, global, shared, attribute, IPA, indexed constant loads (LDC)等。分析是哪一类数据导致的,是否可以换成其他形式获取数据,比如使用代码计算生成;
- Short Scoreboard:Scoreboard计分板是调度器用来管理线程依赖,记录了某Warp指令是否可派发。一些比较短周期的资源竞争导致线程阻塞,比如那些访问共享内存而产生bank冲突的线程将会以串行方式执行。包括3D attribute load/store, pixel attribute interpolation, compute shared memory load/store, indexed constant loads等;
- Long Scoreboard:等待获取本地、全局、纹理等周期比较长的数据。可以考虑将查表/纹理采样转换为计算,以及将所有线程读取相同地址的全局内存改为常量缓冲区。
- Not Selected:合格Warp但是没有被Warp调度器选中。如果该项占比高说明有很多Eligible Warp,即使减少些也不会影响性能的话,可以增加某些Shader复杂度,如寄存器使用量。
- Wait:程序计数器(PC)为了使分支收敛而发出Wait指令。当分支都同步之后,才继续锁步(lock-step)执行下一条指令。
更多的Stall原因,参考NVIDIA资料:User Guide :: Nsight Graphics Documentation。
5、总结
结合上一篇文章GPU架构知识,进一步梳理Shader划分为Warps后是如何调度的,进而探究Warps的调度效率。最终列举了一些常见的Stalled原因,包括线程同步、数据依赖、缓存命中等等。实践上,我们通过NVIDIA Nsight Graphics工具进行Shader Profiler,可以轻易拿到Shader的性能统计数据,包括该Shader的Warp数量、寄存器数量、共享内存大小、以及Stalled原因等,然后我们就可以针对性地优化Shader。
参考:
User Guide :: Nsight Graphics Documentation。