gocookbook
 gocookbook copied to clipboard
gocookbook copied to clipboard
Go语言中的字符串
虽然字符串往往被看做一个整体,但是它实际上是一片连续的内存空间,我们也可以将它理解成一个由字符组成的数组。C 语言中的字符串使用字符数组 char[] 表示。数组会占用一片连续的内存空间,而内存空间存储的字节共同组成了字符串,Go 语言中的字符串只是一个只读的字节数组,下图展示了 "hello" 字符串在内存中的存储方式:

Go 语言只是不支持直接修改 string 类型变量的内存空间,我们仍然可以通过在 string 和 []byte 类型之间反复转换实现修改这一目的:
- 先将这段内存拷贝到堆或者栈上;
- 将变量的类型转换成
[]byte后并修改字节数据; - 将修改后的字节数组转换回
string;
Java、Python 以及很多编程语言的字符串也都是不可变的,这种不可变的特性可以保证我们不会引用到意外发生改变的值。
Go语言字符串的结构表示
字符串在 Go 语言中的接口其实非常简单,每一个字符串在运行时都会使用如下的 reflect.StringHeader 表示,其中包含指向字节数组的指针和数组的大小:
type StringHeader struct {
Data uintptr
Len int
}
与切片的结构体相比,字符串只少了一个表示容量的 Cap 字段,而正是因为切片在 Go 语言的运行时表示与字符串运行时表示高度相似,所以我们经常会说字符串是一个只读的切片类型。
type SliceHeader struct {
Data uintptr
Len int
Cap int
}
因为字符串作为只读的类型,我们并不能直接向字符串直接追加元素改变其本身的内存空间,所有在字符串上的写入操作都是通过拷贝实现的。
字符串的拼接和拷贝
在正常情况下,运行时会调用 copy 将输入的多个字符串拷贝到目标字符串所在的内存空间。新的字符串是一片新的内存空间,与原来的字符串也没有任何关联,一旦需要拼接的字符串非常大,拷贝带来的性能损失是无法忽略的。
string 与 []byte 转换
当我们使用 Go 语言解析和序列化 JSON 等数据格式时,经常需要将数据在 string 和 []byte 之间来回转换,类型转换的开销并没有想象的那么小,我们经常会看到 runtime.slicebytetostring 等函数出现在性能分析(pprof)的火焰图中,成为程序的性能热点。
从字节数组到字符串的转换需要使用 runtime.slicebytetostring 函数,例如:string(bytes),该函会根据传入的缓冲区大小决定是否需要为新字符串分配一片内存空间,runtime.stringStructOf 会将传入的字符串指针转换成 runtime.stringStruct 结构体指针,然后设置结构体持有的字符串指针 str 和长度 len,最后通过 runtime.memmove 将原 []byte 中的字节全部复制到新的内存空间中。
当我们想要将字符串转换成 []byte 类型时,需要使用 runtime.stringtoslicebyte 函数,该函数的实现非常容易理解:
func stringtoslicebyte(buf *tmpBuf, s string) []byte {
var b []byte
if buf != nil && len(s) <= len(buf) {
*buf = tmpBuf{}
b = buf[:len(s)]
} else {
b = rawbyteslice(len(s))
}
copy(b, s)
return b
}
上述函数会根据是否传入缓冲区做出不同的处理:
- 当传入缓冲区时,它会使用传入的缓冲区存储
[]byte; - 当没有传入缓冲区时,运行时会调用
runtime.rawbyteslice创建新的字节切片并将字符串中的内容拷贝过去;
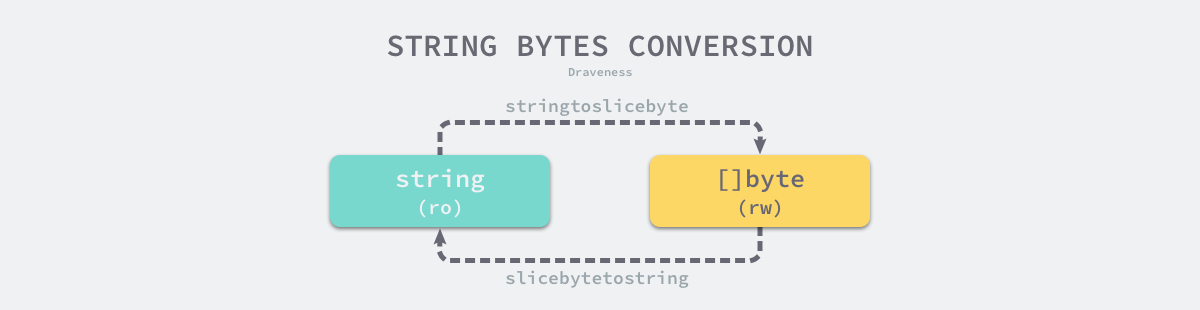
字符串和 []byte 中的内容虽然一样,但是字符串的内容是只读的,我们不能通过下标或者其他形式改变其中的数据,而 []byte 中的内容是可以读写的。不过无论从哪种类型转换到另一种都需要拷贝数据,而内存拷贝的性能损耗会随着字符串和 []byte 长度的增长而增长。
所有内容摘录自Go语言设计与实现