pdfalto
 pdfalto copied to clipboard
pdfalto copied to clipboard
Feature Request: Additional Styles
Currently the following styles seem to be supported by pdfalto:
- italic
- bold
- subscript
- superscript
Some other styles we would be interested in:
- underline
- sc
- monospace
- strike
- overline
- roman (although not found in bioRxiv dataset)
I also have named-content on the list but I am not sure whether that really falls into the styles category.
Examples:
italic
462929v1 (10.1101/462929)
PDF:

bioRxiv XML:
would start with loss of the <italic>APC</italic> gene, followed by mutations in <italic>KRAS</italic> or <italic>BRAF</italic> genes, mutations or loss of <italic>TP53</italic> gene and of SMAD family member 4 (<italic>SMAD4</italic>) [<xref ref-type="bibr" rid="c4">4</xref>].</p>
GROBID 0.6.1 seems to be missing large sections of the Introduction section.
Using one of the more recent bioRxiv trained models:
would start with loss of the APC gene, followed by mutations in KRAS or BRAF genes, mutations or loss of TP53 gene and of SMAD family member 4 (SMAD4)
No italic in sight.
sc (Small Caps)
188706v1 (10.1101/188706)
PDF:

bioRxiv XML:
<p>Finally, <sc>ndmg</sc> produces a QA plot
473744v1 (10.1101/473744)
PDF:
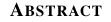
bioRxiv XML, probably not correct:
<title>A<sc>bstract</sc></title>
underline
218479v1 (10.1101/218479)
PDF:

bioRxiv XML:
<contrib-group>
<!-- .... -->
<aff id="a1"><label>1</label><institution>Biology Department, University of Pennsylvania</institution>, Philadelphia, PA 19104</aff>
<aff id="a2"><label>2</label><institution>Neuroscience Graduate Group, University of Pennsylvania</institution>, Philadelphia, PA 19104</aff>
<aff id="a3"><label>3</label><institution>Biological Basis of Behavior Program, University of Pennsylvania</institution>, Philadelphia, PA 19104</aff>
<aff id="a4"><label>4</label><underline>Current Address</underline>: <institution>The Lockwood Group</institution>, Stamford, CT 06901.</aff>
<aff id="a5"><label>5</label><underline>Current Address</underline>: <institution>Department of Neuroscience, University of Pennsylvania</institution>, Philadelphia, PA 19104</aff>
</contrib-group>
<author-notes>
<corresp id="cor1"><underline>Corresponding Author</underline>: <underline>Email</underline>: <email>[email protected]</email></corresp>
<corresp id="cor2"><label>*</label>Both authors contributed equally to this work</corresp>
</author-notes>
monospace
473744v1 (10.1101/473744)
PDF:
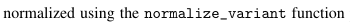
bioRxiv XML:
normalized using the <monospace>Normalize_Variant</monospace> function
strike
Only two documents of the 6000 training examples are containing <strike>.
701052v1 (10.1101/701052)
PDF:

bioRxiv XML:
using antifungals and absence of oral lesions. <strike>The data collection, the oral mucosa examination, were performed according to Pieralisi et al., 2016. This study was conducted according to the Resolution 466/2012 of the National Health Council and was previously approved by the Ethics Committee for the Research Involving Humans of the State University of Maringá, Brazil [COPEP-EMU n° 383979, CAEE resolution n° 17297713.2.0000.0104].</strike></p>
overline
(not many examples)
362053v1 (10.1101/362053)
PDF:
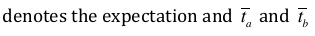
bioRxiv XML:
denotes the expectation and <overline><italic>t<sub>a</sub></italic></overline> and <overline><italic>t<sub>b</sub></italic></overline>
Do you know which style can be obtained from the font full name?
The way to get italic or bold information is actually very hacky https://github.com/kermitt2/pdfalto/blob/master/src/XmlAltoOutputDev.cc#L598 but it's the normal way...
In pdfalto, superscript and subscript are detected by analysing positions wrt. to base line and top of the line and modification of the font size.
I haven't looked into it yet. I imagine it not being trivial. I believe I have seen detection based on the font name elsewhere. In some cases even via a font name map. As the first step I would probably also check what poppler or similar tools can already do.
I suppose if the font name is not sufficient, then perhaps analysing the glyph might do. Might end up with a machine learning model ;-)
Thinking about it, I have some vague recollection someone at the GROBID camp in Paris was going to work on something related. Perhaps Pedro? I am probably just making it up.