nanoGPT
 nanoGPT copied to clipboard
nanoGPT copied to clipboard
Training on AMD Ryzen 5 5600H with Radeon Graphics, 3301 Mhz (RTX 3050 Laptop), 6 Cores, 12 Threads
*Edit: Here is my Python Version and packages list, including NVIDIA CUDA info.
Python 3.8.10
aiohttp==3.8.3
aiosignal==1.3.1
async-timeout==4.0.2
attrs==22.2.0
blobfile==2.0.0
certifi==2022.12.7
charset-normalizer==2.1.1
colorama==0.4.6
datasets==2.8.0
dill==0.3.6
filelock==3.9.0
frozenlist==1.3.3
fsspec==2022.11.0
huggingface-hub==0.11.1
idna==3.4
lxml==4.9.2
multidict==6.0.4
multiprocess==0.70.14
numpy==1.24.1
packaging==23.0
pandas==1.5.2
Pillow==9.4.0
pyarrow==10.0.1
pycryptodomex==3.16.0
python-dateutil==2.8.2
pytz==2022.7
PyYAML==6.0
regex==2022.10.31
requests==2.28.1
responses==0.18.0
six==1.16.0
tiktoken==0.1.2
torch==1.13.1+cu117
torchaudio==0.13.1+cu117
torchvision==0.14.1+cu117
tqdm==4.64.1
typing-extensions==4.4.0
urllib3==1.26.13
xxhash==3.2.0
yarl==1.8.2
nvcc: NVIDIA (R) Cuda compiler driver
Copyright (c) 2005-2022 NVIDIA Corporation
Built on Tue_May__3_19:00:59_Pacific_Daylight_Time_2022
Cuda compilation tools, release 11.7, V11.7.64
Build cuda_11.7.r11.7/compiler.31294372_0
Following all the protocols in the README.md, upon 'prepare.py' run after the extraction, I started having some problems, I will copy below the console errors:
Loading cached split indices for dataset at C:\Users\jeanc\.cache\huggingface\datasets\openwebtext\plain_text\1.0.0\85b3ae7051d2d72e7c5fdf6dfb462603aaa26e9ed506202bf3a24d261c6c40a1\cache-e592ba88a0d6344c.arrow and C:\Users\jeanc\.cache\huggingface\datasets\openwebtext\plain_text\1.0.0\85b3ae7051d2d72e7c5fdf6dfb462603aaa26e9ed506202bf3a24d261c6c40a1\cache-9fc622ec8039deff.arrow
Traceback (most recent call last):
File "<string>", line 1, in <module>
File "C:\Users\jeanc\AppData\Local\Programs\Python\Python38\lib\site-packages\multiprocess\spawn.py", line 116, in spawn_main
exitcode = _main(fd, parent_sentinel)
File "C:\Users\jeanc\AppData\Local\Programs\Python\Python38\lib\site-packages\multiprocess\spawn.py", line 125, in _main
prepare(preparation_data)
File "C:\Users\jeanc\AppData\Local\Programs\Python\Python38\lib\site-packages\multiprocess\spawn.py", line 236, in prepare
_fixup_main_from_path(data['init_main_from_path'])
File "C:\Users\jeanc\AppData\Local\Programs\Python\Python38\lib\site-packages\multiprocess\spawn.py", line 287, in _fixup_main_from_path
main_content = runpy.run_path(main_path,
File "C:\Users\jeanc\AppData\Local\Programs\Python\Python38\lib\runpy.py", line 265, in run_path
Traceback (most recent call last):
File "<string>", line 1, in <module>
File "C:\Users\jeanc\AppData\Local\Programs\Python\Python38\lib\site-packages\multiprocess\spawn.py", line 116, in spawn_main
exitcode = _main(fd, parent_sentinel)
File "C:\Users\jeanc\AppData\Local\Programs\Python\Python38\lib\site-packages\multiprocess\spawn.py", line 125, in _main
prepare(preparation_data)
File "C:\Users\jeanc\AppData\Local\Programs\Python\Python38\lib\site-packages\multiprocess\spawn.py", line 236, in prepare
_fixup_main_from_path(data['init_main_from_path'])
File "C:\Users\jeanc\AppData\Local\Programs\Python\Python38\lib\site-packages\multiprocess\spawn.py", line 287, in _fixup_main_from_path
main_content = runpy.run_path(main_path,
Traceback (most recent call last):
File "C:\Users\jeanc\AppData\Local\Programs\Python\Python38\lib\runpy.py", line 265, in run_path
File "<string>", line 1, in <module>
return _run_module_code(code, init_globals, run_name,
return _run_module_code(code, init_globals, run_name,
File "C:\Users\jeanc\AppData\Local\Programs\Python\Python38\lib\site-packages\multiprocess\spawn.py", line 116, in spawn_main
File "C:\Users\jeanc\AppData\Local\Programs\Python\Python38\lib\runpy.py", line 97, in _run_module_code
File "C:\Users\jeanc\AppData\Local\Programs\Python\Python38\lib\runpy.py", line 97, in _run_module_code
exitcode = _main(fd, parent_sentinel)
_run_code(code, mod_globals, init_globals,
_run_code(code, mod_globals, init_globals,
File "C:\Users\jeanc\AppData\Local\Programs\Python\Python38\lib\site-packages\multiprocess\spawn.py", line 125, in _main
File "C:\Users\jeanc\AppData\Local\Programs\Python\Python38\lib\runpy.py", line 87, in _run_code
File "C:\Users\jeanc\AppData\Local\Programs\Python\Python38\lib\runpy.py", line 87, in _run_code
prepare(preparation_data)
exec(code, run_globals)
exec(code, run_globals)
File "C:\Users\jeanc\AppData\Local\Programs\Python\Python38\lib\site-packages\multiprocess\spawn.py", line 236, in prepare
File "C:\AI\nanoGPT\data\openwebtext\prepare.py", line 43, in <module>
File "C:\AI\nanoGPT\data\openwebtext\prepare.py", line 43, in <module>
_fixup_main_from_path(data['init_main_from_path'])
tokenized = split_dataset.map(
tokenized = split_dataset.map(
File "C:\Users\jeanc\AppData\Local\Programs\Python\Python38\lib\site-packages\multiprocess\spawn.py", line 287, in _fixup_main_from_path
File "C:\Users\jeanc\AppData\Local\Programs\Python\Python38\lib\site-packages\datasets\dataset_dict.py", line 816, in map
File "C:\Users\jeanc\AppData\Local\Programs\Python\Python38\lib\site-packages\datasets\dataset_dict.py", line 816, in map
main_content = runpy.run_path(main_path,
File "C:\Users\jeanc\AppData\Local\Programs\Python\Python38\lib\runpy.py", line 265, in run_path
return _run_module_code(code, init_globals, run_name,
File "C:\Users\jeanc\AppData\Local\Programs\Python\Python38\lib\runpy.py", line 97, in _run_module_code
_run_code(code, mod_globals, init_globals,
File "C:\Users\jeanc\AppData\Local\Programs\Python\Python38\lib\runpy.py", line 87, in _run_code
exec(code, run_globals)
File "C:\AI\nanoGPT\data\openwebtext\prepare.py", line 43, in <module>
tokenized = split_dataset.map(
File "C:\Users\jeanc\AppData\Local\Programs\Python\Python38\lib\site-packages\datasets\dataset_dict.py", line 816, in map
{
{
{
File "C:\Users\jeanc\AppData\Local\Programs\Python\Python38\lib\site-packages\datasets\dataset_dict.py", line 817, in <dictcomp>
File "C:\Users\jeanc\AppData\Local\Programs\Python\Python38\lib\site-packages\datasets\dataset_dict.py", line 817, in <dictcomp>
File "C:\Users\jeanc\AppData\Local\Programs\Python\Python38\lib\site-packages\datasets\dataset_dict.py", line 817, in <dictcomp>
k: dataset.map(
k: dataset.map(
k: dataset.map(
File "C:\Users\jeanc\AppData\Local\Programs\Python\Python38\lib\site-packages\datasets\arrow_dataset.py", line 2926, in map
File "C:\Users\jeanc\AppData\Local\Programs\Python\Python38\lib\site-packages\datasets\arrow_dataset.py", line 2926, in map
File "C:\Users\jeanc\AppData\Local\Programs\Python\Python38\lib\site-packages\datasets\arrow_dataset.py", line 2926, in map
with Pool(nb_of_missing_shards, initargs=initargs, initializer=initializer) as pool:
with Pool(nb_of_missing_shards, initargs=initargs, initializer=initializer) as pool:
with Pool(nb_of_missing_shards, initargs=initargs, initializer=initializer) as pool:
File "C:\Users\jeanc\AppData\Local\Programs\Python\Python38\lib\site-packages\multiprocess\context.py", line 119, in Pool
File "C:\Users\jeanc\AppData\Local\Programs\Python\Python38\lib\site-packages\multiprocess\context.py", line 119, in Pool
File "C:\Users\jeanc\AppData\Local\Programs\Python\Python38\lib\site-packages\multiprocess\context.py", line 119, in Pool
return Pool(processes, initializer, initargs, maxtasksperchild,
return Pool(processes, initializer, initargs, maxtasksperchild,
return Pool(processes, initializer, initargs, maxtasksperchild,
File "C:\Users\jeanc\AppData\Local\Programs\Python\Python38\lib\site-packages\multiprocess\pool.py", line 212, in __init__
File "C:\Users\jeanc\AppData\Local\Programs\Python\Python38\lib\site-packages\multiprocess\pool.py", line 212, in __init__
File "C:\Users\jeanc\AppData\Local\Programs\Python\Python38\lib\site-packages\multiprocess\pool.py", line 212, in __init__
self._repopulate_pool()
self._repopulate_pool()
self._repopulate_pool()
File "C:\Users\jeanc\AppData\Local\Programs\Python\Python38\lib\site-packages\multiprocess\pool.py", line 303, in _repopulate_pool
File "C:\Users\jeanc\AppData\Local\Programs\Python\Python38\lib\site-packages\multiprocess\pool.py", line 303, in _repopulate_pool
File "C:\Users\jeanc\AppData\Local\Programs\Python\Python38\lib\site-packages\multiprocess\pool.py", line 303, in _repopulate_pool
return self._repopulate_pool_static(self._ctx, self.Process,
return self._repopulate_pool_static(self._ctx, self.Process,
return self._repopulate_pool_static(self._ctx, self.Process,
File "C:\Users\jeanc\AppData\Local\Programs\Python\Python38\lib\site-packages\multiprocess\pool.py", line 326, in _repopulate_pool_static
File "C:\Users\jeanc\AppData\Local\Programs\Python\Python38\lib\site-packages\multiprocess\pool.py", line 326, in _repopulate_pool_static
File "C:\Users\jeanc\AppData\Local\Programs\Python\Python38\lib\site-packages\multiprocess\pool.py", line 326, in _repopulate_pool_static
w.start()
w.start()
w.start()
File "C:\Users\jeanc\AppData\Local\Programs\Python\Python38\lib\site-packages\multiprocess\process.py", line 121, in start
File "C:\Users\jeanc\AppData\Local\Programs\Python\Python38\lib\site-packages\multiprocess\process.py", line 121, in start
File "C:\Users\jeanc\AppData\Local\Programs\Python\Python38\lib\site-packages\multiprocess\process.py", line 121, in start
self._popen = self._Popen(self)
self._popen = self._Popen(self)
self._popen = self._Popen(self)
File "C:\Users\jeanc\AppData\Local\Programs\Python\Python38\lib\site-packages\multiprocess\context.py", line 327, in _Popen
File "C:\Users\jeanc\AppData\Local\Programs\Python\Python38\lib\site-packages\multiprocess\context.py", line 327, in _Popen
File "C:\Users\jeanc\AppData\Local\Programs\Python\Python38\lib\site-packages\multiprocess\context.py", line 327, in _Popen
return Popen(process_obj)
return Popen(process_obj)
return Popen(process_obj)
File "C:\Users\jeanc\AppData\Local\Programs\Python\Python38\lib\site-packages\multiprocess\popen_spawn_win32.py", line 45, in __init__
File "C:\Users\jeanc\AppData\Local\Programs\Python\Python38\lib\site-packages\multiprocess\popen_spawn_win32.py", line 45, in __init__
File "C:\Users\jeanc\AppData\Local\Programs\Python\Python38\lib\site-packages\multiprocess\popen_spawn_win32.py", line 45, in __init__
prep_data = spawn.get_preparation_data(process_obj._name)
prep_data = spawn.get_preparation_data(process_obj._name)
prep_data = spawn.get_preparation_data(process_obj._name)
File "C:\Users\jeanc\AppData\Local\Programs\Python\Python38\lib\site-packages\multiprocess\spawn.py", line 154, in get_preparation_data
File "C:\Users\jeanc\AppData\Local\Programs\Python\Python38\lib\site-packages\multiprocess\spawn.py", line 154, in get_preparation_data
File "C:\Users\jeanc\AppData\Local\Programs\Python\Python38\lib\site-packages\multiprocess\spawn.py", line 154, in get_preparation_data
_check_not_importing_main()
_check_not_importing_main()
_check_not_importing_main()
File "C:\Users\jeanc\AppData\Local\Programs\Python\Python38\lib\site-packages\multiprocess\spawn.py", line 134, in _check_not_importing_main
File "C:\Users\jeanc\AppData\Local\Programs\Python\Python38\lib\site-packages\multiprocess\spawn.py", line 134, in _check_not_importing_main
File "C:\Users\jeanc\AppData\Local\Programs\Python\Python38\lib\site-packages\multiprocess\spawn.py", line 134, in _check_not_importing_main
raise RuntimeError('''
raise RuntimeError('''
RuntimeError:
An attempt has been made to start a new process before the
current process has finished its bootstrapping phase.
This probably means that you are not using fork to start your
child processes and you have forgotten to use the proper idiom
in the main module:
if __name__ == '__main__':
freeze_support()
...
The "freeze_support()" line can be omitted if the program
is not going to be frozen to produce an executable. `
I made sure to set num_proc = 3
After this I tried some code edits, none of the were succesful (following some suggestions from similar errors in different scripts online).
At last, I attempted to ChatGPT, my first input was inserting the prepare.py code and asking what is the DataSet used in the code.
I had the following answer:
The dataset being used is the "openwebtext" dataset, which is loaded using the load_dataset function from the datasets module (presumably from the Hugging Face transformers library). This dataset is then split into a train and validation set using the train_test_split method, with the validation set being a very small fraction (0.0005) of the total dataset. The resulting train and validation sets are stored in the split_dataset dictionary, with the train set having approximately 8,009,762 examples and the validation set having approximately 4,007 examples.
My following prompt was (sorry for the low level comprehension of pytorch and A.I.):
how to use this dataset in this code
# Download training data from open datasets.
training_data = datasets.FashionMNIST(
root="data",
train=True,
download=True,
transform=ToTensor(),
)
# Download test data from open datasets.
test_data = datasets.FashionMNIST(
root="data",
train=False,
download=True,
transform=ToTensor(),
)
Then i had this answer:
To use the openwebtext dataset in the provided code, you would need to modify the code to first load the openwebtext dataset using the load_dataset function and then apply the required processing steps (tokenization and concatenation) to the dataset. You can then use the resulting tokenized dataset for training or evaluation.
Here is an example of how you could modify the code to use the openwebtext dataset:
import numpy as np
import tiktoken
from datasets import load_dataset
# Load the openwebtext dataset.
dataset = load_dataset("openwebtext")
# Tokenize the dataset using the encoding function and process function defined in the original code.
enc = tiktoken.get_encoding("gpt2")
def process(example):
ids = enc.encode_ordinary(example['text'])
ids.append(enc.eot_token)
out = {'ids': ids, 'len': len(ids)}
return out
tokenized = dataset.map(process, remove_columns=['text'])
# Concatenate all the ids in the dataset into one large file.
arr_len = np.sum(tokenized['len'])
filename = 'openwebtext.bin'
dtype = np.uint16
arr = np.memmap(filename, dtype=dtype, mode='w+', shape=(arr_len,))
idx = 0
for example in tqdm(tokenized):
arr[idx : idx + example['len']] = example['ids']
idx += example['len']
arr.flush()
You can then use the openwebtext.bin file for training or evaluation. To read the file, you can use np.memmap as shown in the original code.
So now the code is running and looking like:
# saves the openwebtext dataset to a binary file for training. following was helpful:
# https://github.com/HazyResearch/flash-attention/blob/main/training/src/datamodules/language_modeling_hf.py
from tqdm import tqdm
import numpy as np
import tiktoken
from datasets import load_dataset # huggingface datasets
# number of workers in .map() call
# good number to use is ~order number of cpu cores // 2
num_proc = 3
# takes 54GB in huggingface .cache dir, about 8M documents (8,013,769)
dataset = load_dataset("openwebtext")
# owt by default only contains the 'train' split, so create a test split
split_dataset = dataset["train"].train_test_split(test_size=0.0005, seed=2357, shuffle=True)
split_dataset['val'] = split_dataset.pop('test') # rename the test split to val
# this results in:
# >>> split_dataset
# DatasetDict({
# train: Dataset({
# features: ['text'],
# num_rows: 8009762
# })
# val: Dataset({
# features: ['text'],
# num_rows: 4007
# })
# })
# Tokenize the dataset using the encoding function and process function defined in the original code.
enc = tiktoken.get_encoding("gpt2")
def process(example):
ids = enc.encode_ordinary(example['text'])
ids.append(enc.eot_token)
out = {'ids': ids, 'len': len(ids)}
return out
tokenized = dataset.map(process, remove_columns=['text'])
# Concatenate all the ids in the dataset into one large file.
arr_len = np.sum(tokenized['len'])
filename = 'openwebtext.bin'
dtype = np.uint16
arr = np.memmap(filename, dtype=dtype, mode='w+', shape=(arr_len,))
idx = 0
for example in tqdm(tokenized):
arr[idx: idx + example['len']] = example['ids']
idx += example['len']
arr.flush()
# train.bin is ~17GB, val.bin ~8.5MB
# train has ~9B tokens (9,035,582,198)
# val has ~4M tokens (4,434,897)
# to read the bin files later, e.g. with numpy:
# m = np.memmap('train.bin', dtype=np.uint16, mode='r')
# m[:10]
# array([ 50256, 52429, 52429, 52429, 52429, 52429, 52429, 52429,
# 52429, 52429], dtype=uint16)
# to look up the token values, use the enc.decode_single() method. e.g.:
# >>> enc.decode_single(50256)
# '
Now, I will continue to learn and understand about this new world, thank you @karpathy for the code and when everything is set up, I will learn how to learn, adapt and use this tool to the world around me, thank you.
I could not even start to comprehend after the first prepare.py run, so I am still sorting out some things, hope that this will help someone, someday.
The main difference is that num_proc is absent in the defined functions, other than the loop being written in a different way, probably that is the reason that it seems to work now, i will test later with the original code without the num_proc in the way you originally wrote @karpathy
*Edit 2
Yes, without num_proc being defined, it was only using 1 core. I ran the previous prepare.py version, now I edited and included num_proc
# saves the openwebtext dataset to a binary file for training. following was helpful:
# https://github.com/HazyResearch/flash-attention/blob/main/training/src/datamodules/language_modeling_hf.py
from torch import multiprocessing
from tqdm import tqdm
import numpy as np
import tiktoken
from datasets import load_dataset # huggingface datasets
# number of workers in .map() call
# good number to use is ~order number of cpu cores // 2
num_proc = 3
# takes 54GB in huggingface .cache dir, about 8M documents (8,013,769)
dataset = load_dataset("openwebtext")
# owt by default only contains the 'train' split, so create a test split
split_dataset = dataset["train"].train_test_split(test_size=0.0005, seed=2357, shuffle=True)
split_dataset['val'] = split_dataset.pop('test') # rename the test split to val
# this results in:
# >>> split_dataset
# DatasetDict({
# train: Dataset({
# features: ['text'],
# num_rows: 8009762
# })
# val: Dataset({
# features: ['text'],
# num_rows: 4007
# })
# })
# Tokenize the dataset using the encoding function and process function defined in the original code.
enc = tiktoken.get_encoding("gpt2")
if __name__ == '__main__':
# Enable the creation of child processes.
multiprocessing.freeze_support()
# Load the openwebtext dataset.
dataset = load_dataset("openwebtext")
# Tokenize the dataset using the encoding function and process function defined in the original code.
enc = tiktoken.get_encoding("gpt2")
def process(example):
ids = enc.encode_ordinary(example['text'])
ids.append(enc.eot_token)
out = {'ids': ids, 'len': len(ids)}
return out
# Set the number of worker processes to use.
num_proc = num_proc
tokenized = split_dataset.map(process, remove_columns=['text'], num_proc=num_proc)
# Concatenate all the ids in the dataset into one large file.
arr_len = np.sum(tokenized['len'])
filename = 'openwebtext.bin'
dtype = np.uint16
arr = np.memmap(filename, dtype=dtype, mode='w+', shape=(arr_len,))
idx = 0
for example in tqdm(tokenized):
arr[idx: idx + example['len']] = example['ids']
idx += example['len']
arr.flush()
# train.bin is ~17GB, val.bin ~8.5MB
# train has ~9B tokens (9,035,582,198)
# val has ~4M tokens (4,434,897)
# to read the bin files later, e.g. with numpy:
# m = np.memmap('train.bin', dtype=np.uint16, mode='r')
# m[:10]
# array([ 50256, 52429, 52429, 52429, 52429, 52429, 52429, 52429,
# 52429, 52429], dtype=uint16)
# to look up the token values, use the enc.decode_single() method. e.g.:
# >>> enc.decode_single(50256)
# '
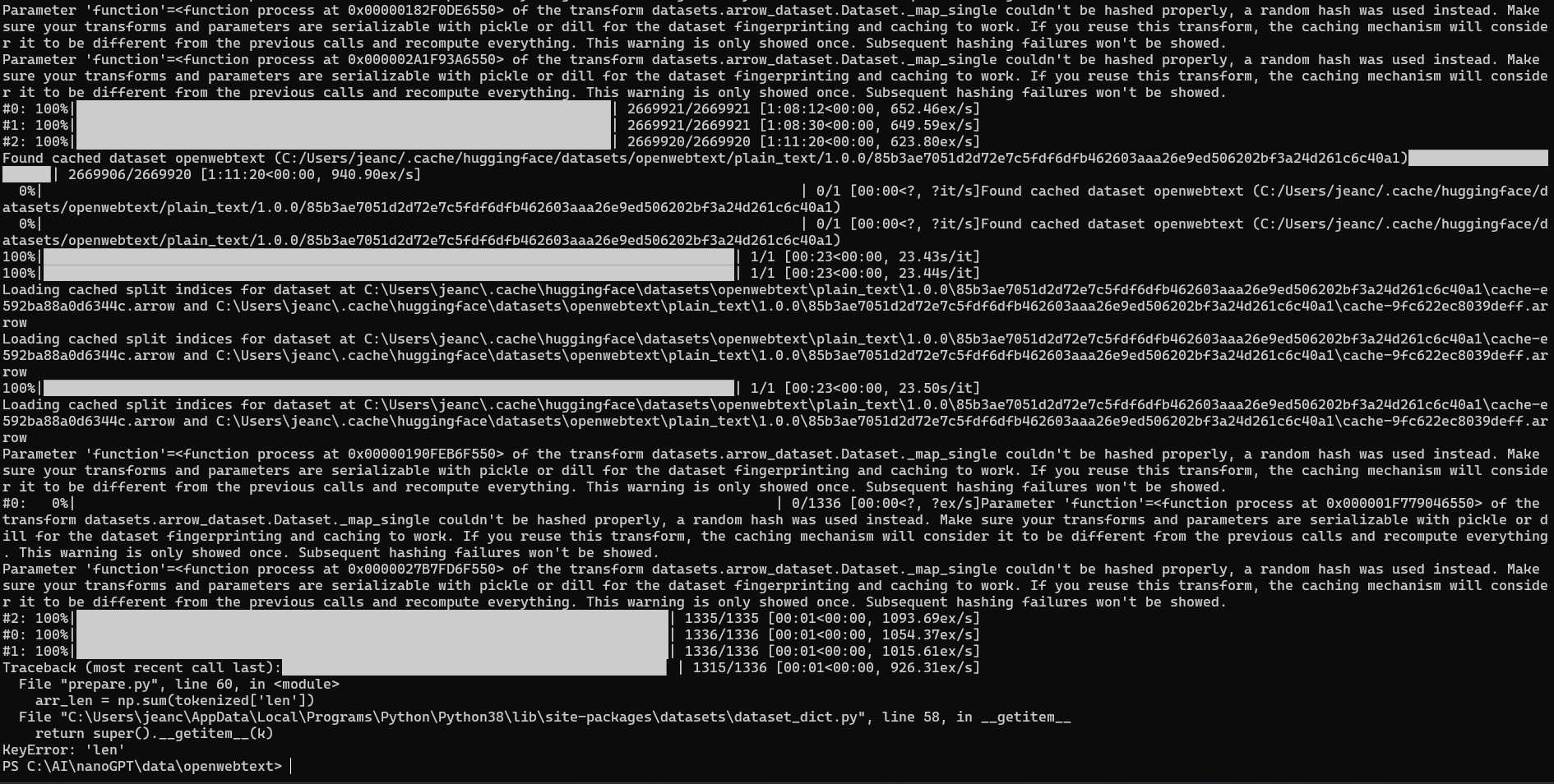
I really do not know what to do now, I managed to fix one problem, now I have this issue, and doesn't make much sense because len is defined in the output function
Help is optional here, I am no data scientist, I am just very very curious.
finally. i think i know why it's not working, i am on windows, as Izeladan mentioned in his post https://lzeladam.com/posts/08-Desglosando-prepare.py-del-proyecto-nanoGPT-Parte1/