Apply SVD on a trained model and then retrain for 1 epoch
This PR deals with doing a plain SVD on an already trained model and restricting the SVD on the basis of maximum energy singular values and number of parameters criterion. A new model is retrained for 1 epoch. Obtained WER similar to old models after retraining, and approximately 70% reduction in model size.
Do you have numbers for training a model of reduced size from scratch (and then training it again for 1 epoch)?
Dan is working on training with reduced model size from scratch. It will be a separate pull request later.
Thanks. Can you give some indication what the effect on the different layers was and how model size was affected?
I am working separately on different ways to train more compact versions of these types of models from scratch, and I may end up preferring to check that in as it leaves the overall script structure the same. But I'd like to make sure I can get as much model compression as you.
Performing SVD on output layers is giving higher compression (row 4 in the below table). This PR is with the same settings. WER after retraining is the same for all set of experiments.
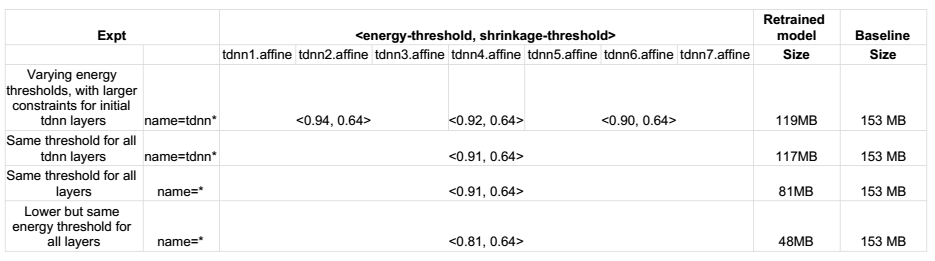
Dan, eventually it will be a valid pathway to start with a larger network and then compress it using SVD to determine the layer size of each layer. Therefore what you are doing is in parallel to this, but not a replacement of this. So i think it makes sense to merge.
@navneeth1990, can you tell us the original dimensions and the SVD hidden-dimensions of the layers for your smallest model?
| I * O | I * B, B * O | |
|---|---|---|
| tdnn1.affine | 300 * 1024 | (300 * 86), (86 *1024) |
| tdnn2.affine | 3072 * 1024 | (3072 * 174), (174 * 1024) |
| tdnn3.affine | 3072 * 1024 | (3072 * 188), (188 * 1024) |
| tdnn4.affine | 1536 * 1024 | (1536 * 126), (126 * 1024) |
| tdnn5.affine | 3072 * 1024 | (3072 * 235), (235 * 1024) |
| tdnn6.affine | 1536 * 1024 | (1536 * 133), (133 * 1024) |
| tdnn7.affine | 3072 * 1024 | (3072 * 251), (251 * 1024) |
| output.affine | 512 * 6230 | (512 * 234), (234 * 6230) |
| output-xent.affine | 512 * 6230 | (512 * 154), (154 * 6230) |
| output-xent.log-softmax | 6230 * 6230 | 6230 * 6230 |
Input dimension : I Output dimension : O Bottleneck dimension : B
@navneeth1990, was this one of your models that performed the same in WER as the baseline? Those dims are very small! It looks like the num-params would be less than half the baseline.
Yes. The WER results were same as baseline after retraining the SVD model. Approximately 70% reduction in model size(153Mb->48Mb). The results without retraining were approx. 3-4% worse than baseline. But WER reduced to that of baseline after 1 epoch retraining.
Did you test also on the train_dev, and did you see any difference vs. the rt03/eval2000 results? Sometimes it seems to diverge for me. I trained a TDNN with a bottleneck and it gave improvements, but not on train_dev. Below (for swbd/s5c, not checked in), tdnn7m8_sp is a TDNN, with a bottleneck of 384 at the output layers; and other TDNN dims 512; and tdnn7m9_sp is also a TDNN but changing it to have dim=768 and bottleneck=320 (or 384 for a couple of layers near the output). It's better, but not for train_dev... (note for n00bs: I'm not showing the swbd-only subset of these test sets, only the full test set, which is why you don't see numbers below 10%).
local/chain/compare_wer_general.sh --rt03 tdnn7m{8,9}_sp
# local/chain/compare_wer_general.sh --rt03 tdnn7m8_sp tdnn7m9_sp
# System tdnn7m8_sp tdnn7m9_sp
# WER on train_dev(tg) 13.60 13.88
# WER on train_dev(fg) 12.62 12.64
# WER on eval2000(tg) 16.8 16.1
# WER on eval2000(fg) 15.4 14.4
# WER on rt03(tg) 16.2 15.5
# WER on rt03(fg) 13.7 13.1
# Final train prob -0.105 -0.111
# Final valid prob -0.115 -0.119
# Final train prob (xent) -1.282 -1.309
# Final valid prob (xent) -1.3194 -1.3246
# Num-parameters 11580452 13818148
I haven't tested on train_dev and rt03. Only eval2000 results. Will run the other tests and update
@navneeth1990 , Hi, I download you kalid branch, and do svd for input.raw. But when retraining, there is a net error(When doing SVD, net convert error):
@danpovey the big final.mdl come from kaldi-5.2 and I do SVD in kaldi-5.3. When I use the small_final.mdl, I find it can not retrain
nnet3-am-copy --edits='apply-svd name= energy-threshold=0.81 shrinkage-threshold=0.64' final.mdl final_smaller_svd_0.84_0.64.mdl*
and then retrain:
steps/nnet3/chain/train.py --stage $lstm_stage \ --cmd "$cmd" \ --trainer.input-model ${exp_dir}/input.raw \ ......
`copy-transition-model final.mdl 0.trans_mdl LOG (copy-transition-model[5.2.179~13-41301]:main():copy-transition-model.cc:62) Copied transition model. nnet3-info input.raw ERROR (nnet3-info[5.2.179~13-41301]:Read():nnet-simple-component.cc:2463) Expected token <IsGradient>, got </NaturalGradientAffineComponent>
[ Stack-Trace: ] nnet3-info() [0x8e002c] kaldi::MessageLogger::HandleMessage(kaldi::LogMessageEnvelope const&, char const*) kaldi::MessageLogger::~MessageLogger() kaldi::nnet3::NaturalGradientAffineComponent::Read(std::istream&, bool) kaldi::nnet3::Component::ReadNew(std::istream&, bool) kaldi::nnet3::Nnet::Read(std::istream&, bool) void kaldi::ReadKaldiObjectkaldi::nnet3::Nnet(std::string const&, kaldi::nnet3::Nnet*) main __libc_start_main nnet3-info() [0x664c79]
Traceback (most recent call last): File "steps/nnet3/ctc/train.py", line 607, in main train(args, run_opts) File "steps/nnet3/ctc/train.py", line 314, in train "{1}".format(str(e), '{0}/configs'.format(args.dir)))`
@navneeth1990 , Can you explain the meaning of these two parameters ("energy-threshold shrinkage-threshold=0.64")?
` bool DecomposeComponent(const std::string &component_name,
const AffineComponent &affine,
Component **component_a_out,
Component **component_b_out) {
int32 input_dim = affine.InputDim(), output_dim = affine.OutputDim();
Matrix<BaseFloat> linear_params(affine.LinearParams());
Vector<BaseFloat> bias_params(affine.BiasParams());
int32 middle_dim = std::min
// note: 'linear_params' is of dimension output_dim by input_dim.
Vector<BaseFloat> s(middle_dim);
Matrix<BaseFloat> A(middle_dim, input_dim),
B(output_dim, middle_dim);
linear_params.Svd(&s, &B, &A);
// make sure the singular values are sorted from greatest to least value.
SortSvd(&s, &B, &A);
BaseFloat s_sum_orig = s.Sum();
Vector<BaseFloat> s2(s.Dim());
s2.AddVec2(1.0, s);
s_sum_orig = s2.Sum();
if (energy_threshold_ > 0) {
BaseFloat min_singular_sum = energy_threshold_ * s2.Sum();
bottleneck_dim_ = BinarySearch(s2, 0, s2.Dim()-1, min_singular_sum);
}
SubVector<BaseFloat> this_part(s2, 0, bottleneck_dim_);
BaseFloat s_sum_reduced = this_part.Sum();
BaseFloat shrinkage_ratio =
static_cast<BaseFloat>(bottleneck_dim_ * (input_dim+output_dim))
/ static_cast<BaseFloat>(input_dim * output_dim);
if (shrinkage_ratio > shrinkage_threshold_) {
KALDI_LOG << "Shrinkage ratio " << shrinkage_ratio
<< " greater than threshold : " << shrinkage_threshold_
<< " Skipping SVD for this layer.";
return false;
}
s.Resize(bottleneck_dim_, kCopyData);
A.Resize(bottleneck_dim_, input_dim, kCopyData);
B.Resize(output_dim, bottleneck_dim_, kCopyData);
KALDI_LOG << "For component " << component_name
<< " singular value sum changed by "
<< (s_sum_orig - s_sum_reduced)
<< " (from " << s_sum_orig << " to " << s_sum_reduced << ")";
KALDI_LOG << "For component " << component_name
<< " dimension reduced from "
<< " (" << input_dim << "," << output_dim << ")"
<< " to [(" << input_dim << "," << bottleneck_dim_
<< "), (" << bottleneck_dim_ << "," << output_dim <<")]";
KALDI_LOG << "shrinkage ratio : " << shrinkage_ratio;
// we'll divide the singular values equally between the two
// parameter matrices.
s.ApplyPow(0.5);
A.MulRowsVec(s);
B.MulColsVec(s);
CuMatrix<BaseFloat> A_cuda(A), B_cuda(B);
CuVector<BaseFloat> bias_params_cuda(bias_params);
LinearComponent *component_a = new LinearComponent(A_cuda);
NaturalGradientAffineComponent *component_b =
new NaturalGradientAffineComponent(B_cuda, bias_params_cuda);
// set the learning rates, max-change, and so on.
component_a->SetUpdatableConfigs(affine);
component_b->SetUpdatableConfigs(affine);
*component_a_out = component_a;
*component_b_out = component_b;
return true;
}`
@navneeth1990 , Can you explain the meaning of these two parameters ("energy-threshold shrinkage-threshold=0.64")? ` bool DecomposeComponent(const std::string &component_name, const AffineComponent &affine, Component **component_a_out, Component **component_b_out) { int32 input_dim = affine.InputDim(), output_dim = affine.OutputDim(); Matrix linear_params(affine.LinearParams()); Vector bias_params(affine.BiasParams()); int32 middle_dim = std::min(input_dim, output_dim);
// note: 'linear_params' is of dimension output_dim by input_dim. Vector<BaseFloat> s(middle_dim); Matrix<BaseFloat> A(middle_dim, input_dim), B(output_dim, middle_dim); linear_params.Svd(&s, &B, &A); // make sure the singular values are sorted from greatest to least value. SortSvd(&s, &B, &A); BaseFloat s_sum_orig = s.Sum(); Vector<BaseFloat> s2(s.Dim()); s2.AddVec2(1.0, s); s_sum_orig = s2.Sum(); if (energy_threshold_ > 0) { BaseFloat min_singular_sum = energy_threshold_ * s2.Sum(); bottleneck_dim_ = BinarySearch(s2, 0, s2.Dim()-1, min_singular_sum); } SubVector<BaseFloat> this_part(s2, 0, bottleneck_dim_); BaseFloat s_sum_reduced = this_part.Sum(); BaseFloat shrinkage_ratio = static_cast<BaseFloat>(bottleneck_dim_ * (input_dim+output_dim)) / static_cast<BaseFloat>(input_dim * output_dim); if (shrinkage_ratio > shrinkage_threshold_) { KALDI_LOG << "Shrinkage ratio " << shrinkage_ratio << " greater than threshold : " << shrinkage_threshold_ << " Skipping SVD for this layer."; return false; } s.Resize(bottleneck_dim_, kCopyData); A.Resize(bottleneck_dim_, input_dim, kCopyData); B.Resize(output_dim, bottleneck_dim_, kCopyData); KALDI_LOG << "For component " << component_name << " singular value sum changed by " << (s_sum_orig - s_sum_reduced) << " (from " << s_sum_orig << " to " << s_sum_reduced << ")"; KALDI_LOG << "For component " << component_name << " dimension reduced from " << " (" << input_dim << "," << output_dim << ")" << " to [(" << input_dim << "," << bottleneck_dim_ << "), (" << bottleneck_dim_ << "," << output_dim <<")]"; KALDI_LOG << "shrinkage ratio : " << shrinkage_ratio; // we'll divide the singular values equally between the two // parameter matrices. s.ApplyPow(0.5); A.MulRowsVec(s); B.MulColsVec(s); CuMatrix<BaseFloat> A_cuda(A), B_cuda(B); CuVector<BaseFloat> bias_params_cuda(bias_params); LinearComponent *component_a = new LinearComponent(A_cuda); NaturalGradientAffineComponent *component_b = new NaturalGradientAffineComponent(B_cuda, bias_params_cuda); // set the learning rates, max-change, and so on. component_a->SetUpdatableConfigs(affine); component_b->SetUpdatableConfigs(affine); *component_a_out = component_a; *component_b_out = component_b; return true;}`
Hello, Firstly sincere apologies from our team, for delay in reply, since Navneeth had left our team few months back.
Coming to the question about the meanings of threshold values: Energy threshold : For each tdnn affine layer in the original baseline nnet3 model, we perform SVD based factoring of the weights matrix of the layer, into a singular values (left diagonal) matrix, and two Eigen matrices.
SVD : Wx = UEV, U,V are Eigen matrices, and E is the singularity matrix)
We take the center matrix E, and consider only the Singular values which contribute to (Energy-threshold) times the total Energy of Singularity parameters. These Singularity parameters are actually sorted in descending order and lower values are pruned out until the Total energy (Sum of squares) of the pruned set of parameters is just above (Energy-threshold * Total init energy). The values which are pruned away are replaced with 0 in the Singularity matrix and the Weights matrix after SVD is derived with shrinked dimensions.
Shrinkage-threshold : If the Shrinkage ratio of the Weights matrix is higher than Shrinkage-threshold for any of the Tdnn layers, the SVD process is aborted with a LOG message that shrinkage exceeds the shrinkage threshold for that particular TDNN affine weights layer.
@danpovey , please consider merging this PR into the mainstream Kaldi. We have a project dependency on this code.
Can I ask a question, why the SVD method can only decompose *AffineComponent , and won't work on others Component such as LinearComponent? Because of the constraint
if (NameMatchesPattern(component_name.c_str(), component_name_pattern_.c_str())) { AffineComponent *affine = dynamic_cast<AffineComponent*>(component); if (affine == NULL) { KALDI_WARN << "Not decomposing component " << component_name << " as it is not an AffineComponent."; continue; }
It could work on linear components in principle; just, the code would have to be extended. In practice I prefer using TDNN-F to train from scratch like that.
On Wed, Sep 18, 2019 at 3:17 PM chenfuouc [email protected] wrote:
Can I ask a question, why the SVD method can only decompose *AffineComponent , and won't work on others Component such as LinearComponent? Because of the constraint
if (NameMatchesPattern(component_name.c_str(), component_name_pattern_.c_str())) { AffineComponent affine = dynamic_cast<AffineComponent>(component); if (affine == NULL) { KALDI_WARN << "Not decomposing component " << component_name << " as it is not an AffineComponent."; continue; }
— You are receiving this because you were mentioned. Reply to this email directly, view it on GitHub, or mute the thread.
It could work on linear components in principle; just, the code would have to be extended. In practice I prefer using TDNN-F to train from scratch like that. … On Wed, Sep 18, 2019 at 3:17 PM chenfuouc @.***> wrote: Can I ask a question, why the SVD method can only decompose *AffineComponent , and won't work on others Component such as LinearComponent? Because of the constraint if (NameMatchesPattern(component_name.c_str(), component_name_pattern_.c_str())) { AffineComponent affine = dynamic_cast<AffineComponent>(component); if (affine == NULL) { KALDI_WARN << "Not decomposing component " << component_name << " as it is not an AffineComponent."; continue; } — You are receiving this because you were mentioned. Reply to this email directly, view it on GitHub, or mute the thread.
Yes, TDNN-F also can decompose the component. But I don't know how to set the bottleneck-dim to balance the WER and RTF before training, since I want to reduce the RTF to 0.2 without serious WER increasing. So I think SVD may be an effective way to reduce parameters.
By the way, can I ask that there are other methods in Kaldi to reduce parameters and RTF, such as Teacher-Student transfer learning, or some experience about decoding faster?
Nothing that works great. You could try reducing, for example, tdnnf bottleneck find in the middle of the network, like an hourglass profile for the bottleneck dims.
On Thu, Sep 19, 2019, 5:18 PM chenfuouc [email protected] wrote:
It could work on linear components in principle; just, the code would have to be extended. In practice I prefer using TDNN-F to train from scratch like that. … <#m_-2326592694757203769_> On Wed, Sep 18, 2019 at 3:17 PM chenfuouc @.***> wrote: Can I ask a question, why the SVD method can only decompose *AffineComponent , and won't work on others Component such as LinearComponent? Because of the constraint if (NameMatchesPattern(component_name.c_str(), component_name_pattern_.c_str())) { AffineComponent affine = dynamic_cast<AffineComponent>(component); if (affine == NULL) { KALDI_WARN << "Not decomposing component " << component_name << " as it is not an AffineComponent."; continue; } — You are receiving this because you were mentioned. Reply to this email directly, view it on GitHub, or mute the thread.
Yes, TDNN-F also can decompose the component. But I don't know how to set the bottleneck-dim to balance the WER and RTF before training, since I want to reduce the RTF to 0.2 without serious WER increasing. So I think SVD may be an effective way to reduce parameters.
By the way, can I ask that there are other methods in Kaldi to reduce parameters and RTF, such as Teacher-Student transfer learning, or some experience about decoding faster?
— You are receiving this because you were mentioned. Reply to this email directly, view it on GitHub https://github.com/kaldi-asr/kaldi/pull/2121?email_source=notifications&email_token=AAZFLO3Z3EXKXSHWB27JEYLQKOJ5JA5CNFSM4EKG5M4KYY3PNVWWK3TUL52HS4DFVREXG43VMVBW63LNMVXHJKTDN5WW2ZLOORPWSZGOD7D27GA#issuecomment-533180312, or mute the thread https://github.com/notifications/unsubscribe-auth/AAZFLO5XT2TGBRPIQA5GCMLQKOJ5JANCNFSM4EKG5M4A .
This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.
This issue has been automatically closed by a bot strictly because of inactivity. This does not mean that we think that this issue is not important! If you believe it has been closed hastily, add a comment to the issue and mention @kkm000, and I'll gladly reopen it.
This issue has been automatically marked as stale by a bot solely because it has not had recent activity. Please add any comment (simply 'ping' is enough) to prevent the issue from being closed for 60 more days if you believe it should be kept open.