icefall
 icefall copied to clipboard
icefall copied to clipboard
I'm planning to implement some SOTA speech synthesis models on LJSpeech and LibriTTS, any suggestions?
I'm new in k2, but very familiar with Kaldi(I wrote the kaldi-ctc).
Text Analyzer
- In the first stage, it will be simple.
- In the future, it will include
- Text Normalization
- Disambiguation of polyphonic words
- etc
Acoustic Models
- Parallel Tacotron2 https://arxiv.org/abs/2103.14574
- Transformer Encoder
- Differentiable Durator
- Fine-grained Token Level VAE
- SoftDTW(banded) Loss
- CPU version(maybe include CUDA version)
- etc
Vocoder Models
- HiFiGAN https://arxiv.org/abs/2010.05646
- etc
Fully End-To-End Model
- combine Acoustic model and Vocoder model into one model and train jointly
Production
- A high quality pronunciation dictionary
- Text Analyzer
- Text Normalizer( and Segmenter for Chinese)
- Disambiguation of polyphonic words
- Model: Text-To-Speech
- Serving
In the first stage, I will focus on implementing Parallel Tacotron2 and HiFiGAN(maybe a new variant) on LJSpeech.
Would be nice if you can first show us some code/initial implementation about this.
Would be nice if you can first show us some code/initial implementation about this.
I will make it happen in the next few weeks.
Very cool! You can find data preparation recipes for both LibriTTS and LJSpeech (and many more) in Lhotse.
https://github.com/lhotse-speech/lhotse/tree/master/lhotse/recipes
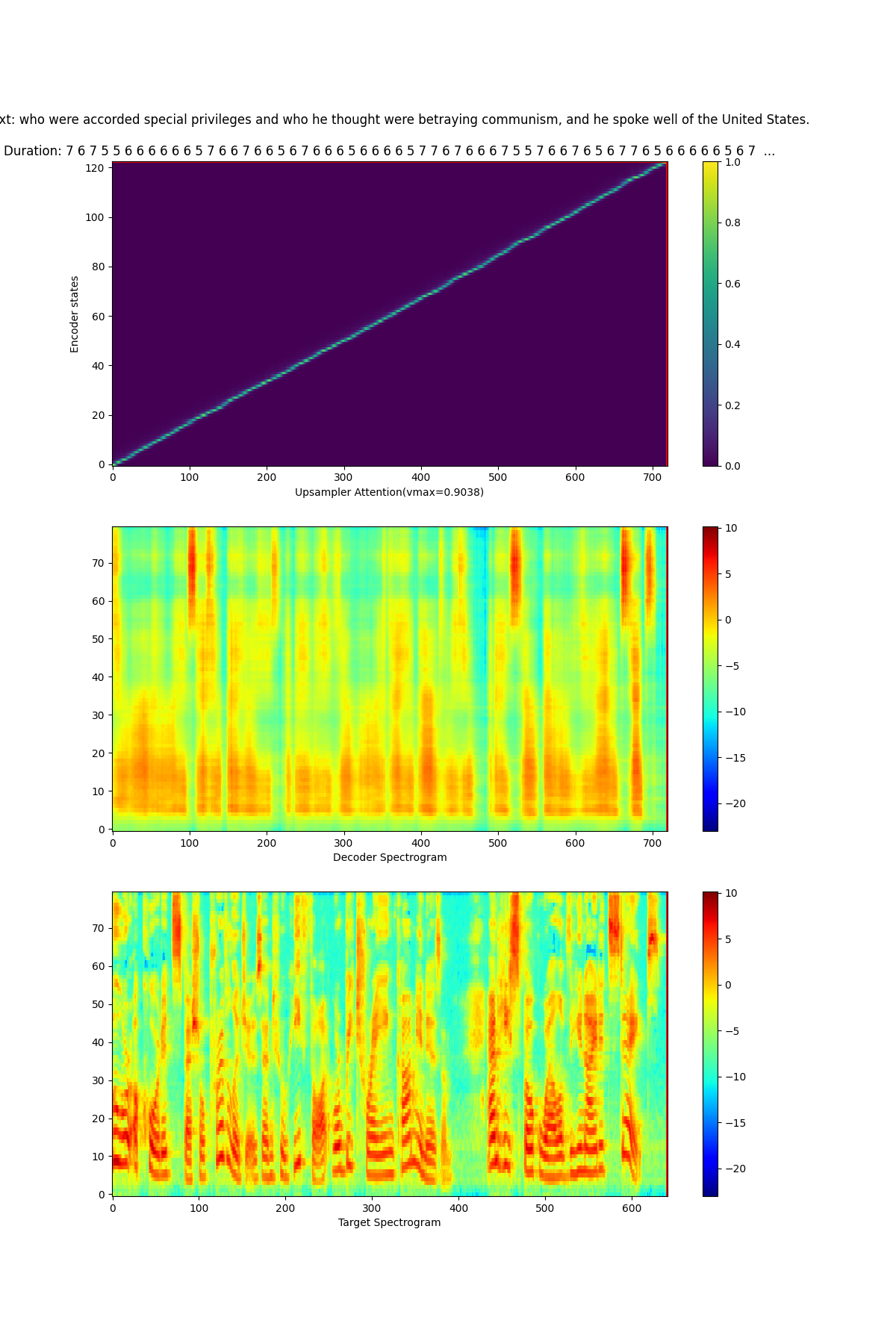
The Text-To-Spectrogram model starts to converge, good upsampling attention has been learned at step 400.
Hi, we have added supports for TTS datasets like LJSpeech and VCTK to icefall!
You can look into them at https://github.com/k2-fsa/icefall/tree/master/egs/ljspeech/TTS and https://github.com/k2-fsa/icefall/pull/1380 , thanks!
Best