icefall
 icefall copied to clipboard
icefall copied to clipboard
Performance degradation when training with jsonl manifests (i.e. DynamicBucketingSampler)
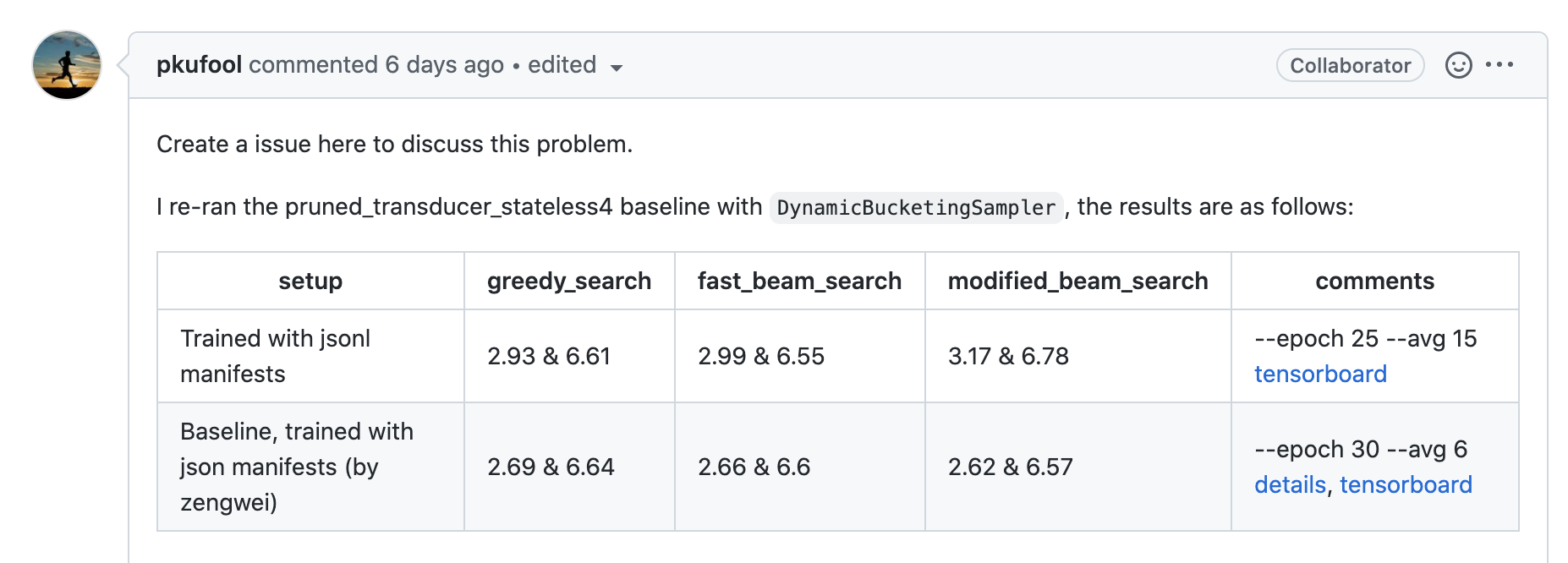
Create a issue here to discuss this problem.
I re-ran the pruned_transducer_stateless4 baseline with DynamicBucketingSampler, the results are as follows:
| setup | greedy_search | fast_beam_search | modified_beam_search | comments |
|---|---|---|---|---|
| Trained with jsonl manifests | 2.93 & 6.61 | 2.99 & 6.55 | 3.17 & 6.78 | --epoch 25 --avg 15 tensorboard |
| Baseline, trained with json manifests (by zengwei) | 2.69 & 6.64 | 2.66 & 6.6 | 2.62 & 6.57 | --epoch 30 --avg 6 details, tensorboard |
I conducted another two experiments: (1) Use json manifests and BucketingSampler (i.e. to reproduce the original baseline) (2) shuffle the jsonl manifests and use DynamicBucketingSampler. shuffle command
gunzip -c jsonl.gz | shuf | gzip -c > new_jsonl.gz
The results are :
| setup | greedy_search | fast_beam_search | modified_beam_search | comments |
|---|---|---|---|---|
| json + BucketingSampler | 2.64 & 6.35 | 2.66 & 6.26 | 2.59 & 6.17 | --epoch 25 --avg 11 |
| shuf jsonl + DynamicBucketingSampler | 2.66 & 6.34 | 2.74 & 6.33 | 2.65 & 6.27 | --epoch 25 --avg 7 |
I ran another experiment using global shuffled jsonl, the shuffle command is:
cat clean-100.jsonl clean-360.jsonl other-500.jsonl | shuf | gzip -c > libri-960.jsonl.gz
Summarize all my experiments below:
| setup | greedy_search | fast_beam_search | modified_beam_search | comments |
|---|---|---|---|---|
| Earlier baseline, json + BucketingSampler (by zengwei) | 2.69 & 6.64 | 2.66 & 6.6 | 2.62 & 6.57 | --epoch 30 --avg 6 |
| json + BucketingSampler | 2.64 & 6.35 | 2.66 & 6.26 | 2.59 & 6.17 | --epoch 25 --avg 11 |
| jsonl + DynamicBucketingSampler | 2.93 & 6.61 | 2.99 & 6.55 | 3.17 & 6.78 | --epoch 25 --avg 15 |
| shuffled jsonl + DynamicBucketingSampler | 2.66 & 6.34 | 2.74 & 6.33 | 2.65 & 6.27 | --epoch 25 --avg 7 |
| global shuffled jsonl + DynamicBucketingSampler | 2.68 & 6.39 | 2.69 & 6.33 | 2.69 & 6.43 | --epoch 25 --avg 9 |
Thanks, this is very interesting. I'm surprised that you are seeing a degradation with global shuffled vs locally shuffled` version (test-other WER on modified_beam_search 6.43 vs 6.27), it's small but large enough to think it could be non-random. But I would have expected the globally shuffled version to work better.
I was considering developing the streaming shuffling further in Lhotse to improve the sampler randomness, but maybe it's not needed.
Here are the results I have using the master code.
It is trained WITHOUT pre-shuffling.
| decoding method | test-clean | test-other | comment |
|---|---|---|---|
| greedy search | 2.69 | 6.45 | --epoch 30, --avg 8, --use-averaged-model true |
It does not indicate that results using jsonl with dynamic bucketing sampler are worse than that of using json with bucketing sampler.
Post the results from the first comment below for easy reference
Training command:
export CUDA_VISIBLE_DEVICES="2,3,4,5,6,7"
./pruned_transducer_stateless4/train.py \
--world-size 6 \
--num-epochs 30 \
--start-epoch 1 \
--exp-dir pruned_transducer_stateless4/exp \
--full-libri 1 \
--max-duration 300 \
--save-every-n 8000 \
--keep-last-k 20 \
--average-period 100
Decoding command
for epoch in 30; do
for avg in 6 7 8 9 10 11; do
./pruned_transducer_stateless4/decode.py \
--epoch $epoch \
--avg $avg \
--use-averaged-model 1 \
--exp-dir ./pruned_transducer_stateless4/exp \
--max-duration 600 \
--decoding-method greedy_search
done
done
Note: The training command is identical with the one listed in https://github.com/k2-fsa/icefall/blob/master/egs/librispeech/ASR/RESULTS.md#librispeech-bpe-training-results-pruned-stateless-transducer-4