icefall
 icefall copied to clipboard
icefall copied to clipboard
pre-trained gigaspeech model decoding error
Unable to decode AMI SDM full-corpur-asr dev set.
- Prepared AMI test and dev set using this command:
lhotse prepare ami \
--mic sdm \
--partition full-corpus-asr \
<path-to-downloaded-ami-corpus> \
"data/manifests/${data_name}"
- Preprocessed data with almost identical script to this
- Computed features with almost identical script to this
After these steps, I was able to successfully decode the test set (WER: 36.62) using the pretrained model here, but I got the following error when decoding the dev set:
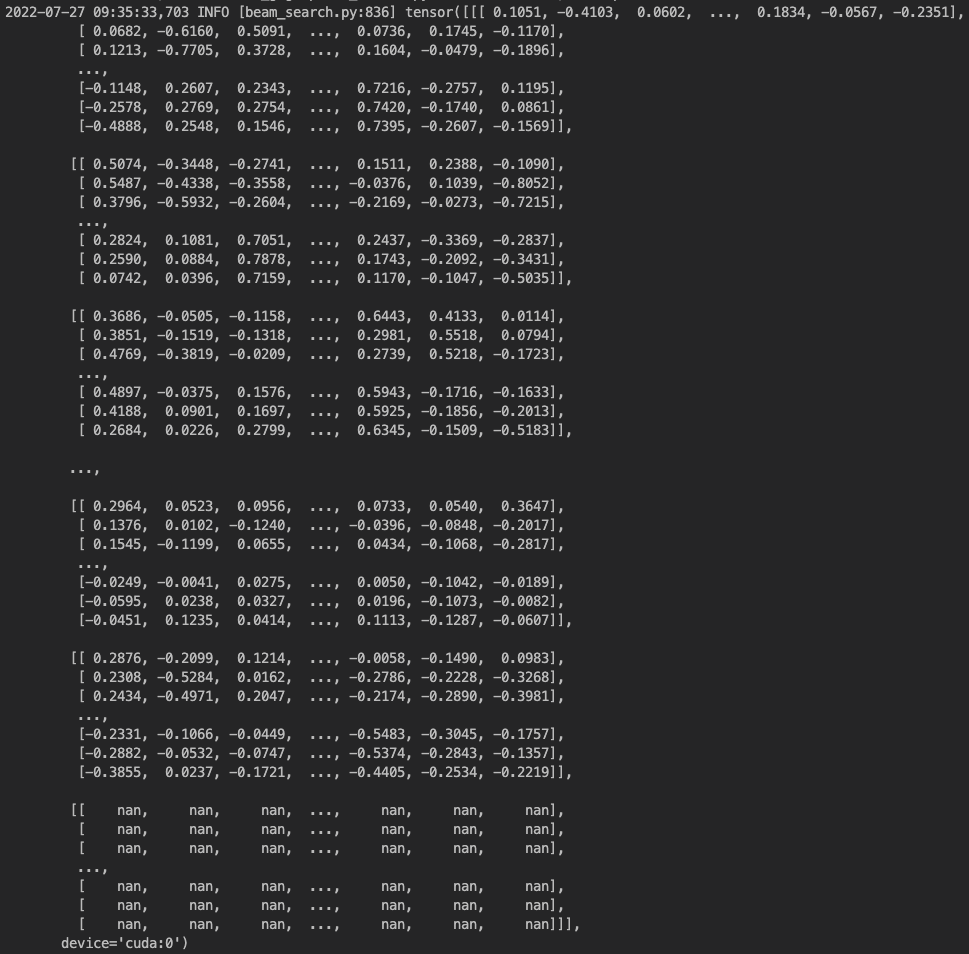
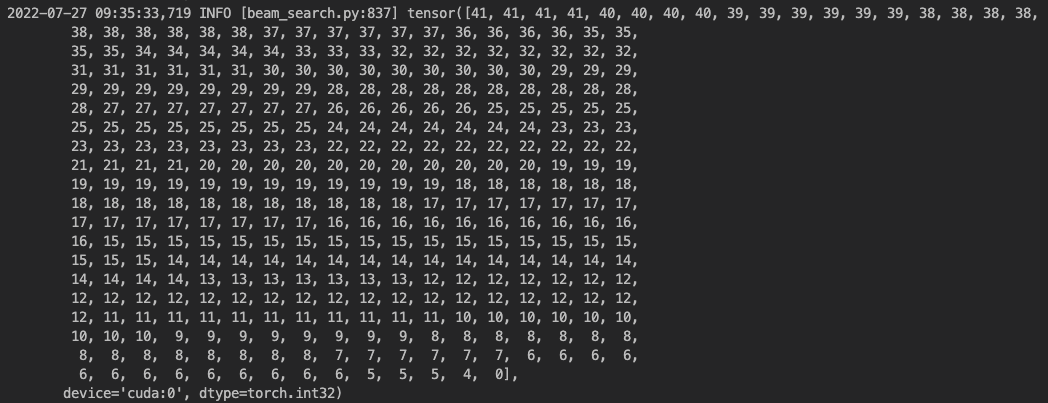
The encoder_out and encoder_out_lens parameter passed into modified_beam_search()that are used as input and lengths and triggered the above error in torch.nn.utils.rnn.pack_padded_sequence() looks like this:
OS: Ubuntu 20.04.3 k2: 1.17.dev20220725+cuda10.2.torch1.7.1 lhotse: 1.5.0.dev0+git.dc5aa88.clean python: 3.8.10
Note: For the second picture, you can see that the last element is 0.
Please check your data and ensure that after subsampling, there are still frames left. That is, you have to filter out your dev utterances that are too short
I see, but how do I determine how short is too short? Or do you mean filtering out the utterances with no frames after the compute feature step (I assume this is where the subsampling is happening?)
The subsampling formula for computing the number of output frames is
num_out_frames = ((num_in_frames - 1)//2 - 1) // 2
In order to make num_out_frames > 0, you have to ensure that num_in_frames >= 7.
I did not find any audio segments that have less than 7 samples, but I was able to complete the decoding without errors after removing segments with less than 1000 samples. I assume I'm not understanding your previous comment correctly. Can you elaborate on the definition of num_in_frames here?
Some additional info: after playing around with the threshold and looking at the filtered out segments, it looks like the longest segments that are causing this error have 960 samples (sample rate 16k).
by
framesare you referring tosamplesin terms of a mono-channel audio?
Frames mean number of feature frames here.
A feature frame is computed from 400 audio samples when window size is 25ms and sample rate is 16kHz.
I see, thanks. Is window size defined somewhere in the feature computation stage?
~~for others' reference, decoding window size is inferred from chunk_size and other hard-coded parameters here: https://github.com/k2-fsa/icefall/blob/d792bdc9bc5e9451ee9119954ddaa4df11167b4e/egs/librispeech/ASR/streaming_conformer_ctc/conformer.py#L274~~
please correct me if i'm wrong.
I see, thanks. Is window size defined somewhere in the feature computation stage?
Please see https://github.com/k2-fsa/icefall/blob/67e3607863807b19037c9b371624f111e76f9c63/egs/fisher_swbd/ASR/local/compute_fbank_fisher_swbd_eval2000.py#L61
You can find the definition of FbankConfig in
https://github.com/k2-fsa/icefall/blob/67e3607863807b19037c9b371624f111e76f9c63/egs/fisher_swbd/ASR/local/compute_fbank_fisher_swbd_eval2000.py#L31
https://github.com/lhotse-speech/lhotse/blob/dc5aa88b53adb73c20e3bf7210742ec3a25c809c/lhotse/features/init.py#L30
from .kaldi.extractors import Fbank, FbankConfig, Mfcc, MfccConfig
https://github.com/lhotse-speech/lhotse/blob/master/lhotse/features/kaldi/extractors.py#L13
@dataclass
class FbankConfig:
sampling_rate: int = 16000
frame_length: Seconds = 0.025
frame_shift: Seconds = 0.01
for others' reference, decoding window size is inferred from chunk_size and other hard-coded parameters here:
What is decoding window size? Not sure what you want to express.
I understand now, thanks for the clarification. I was referring to that line of code I posted.
@csukuangfj In general, if a user is decoding their data with some pretrained model, perhaps the model should have a validation stage which checks if the feature lengths are okay, instead of expecting the user to verify this (since they may not be familiar with the exact subsampling in each model type)?