team-compass
 team-compass copied to clipboard
team-compass copied to clipboard
Matomo not working for large queries on mybinder.org
I was trying to take a look at the data from 2022 so that I could update our impact report from 2021, but I was not able to load any of the graphs that our Matomo instance produces.
Does anybody know what's going on? I have no knowledge of how Matomo works so am not really able to debug...
For example, when trying to view visits over 2022, I ran into this error (I got the same error when reducing the time to 1 week, so don't think it's a data overload thing):
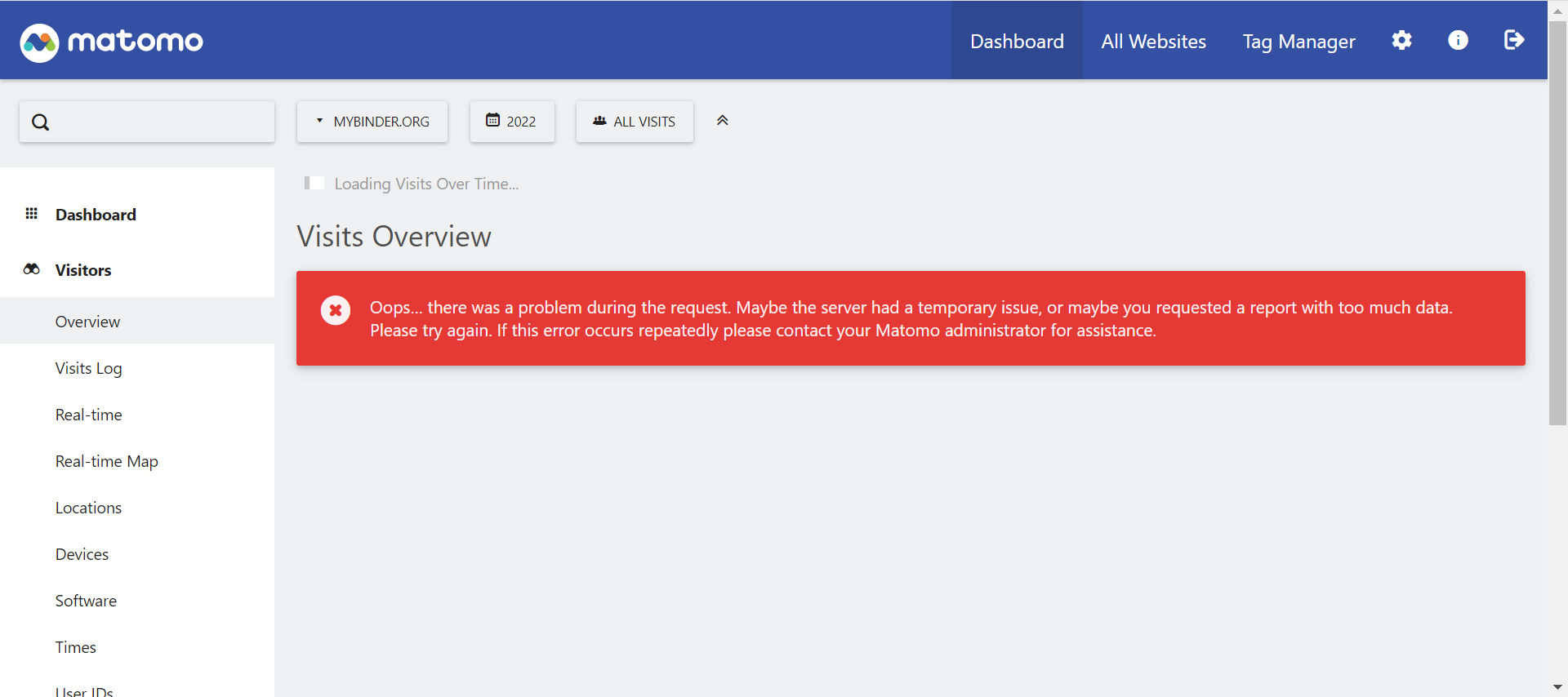
I also so that error on first visit, but as soon as I started opening logs and refreshed the page to start debugging, everything started to work. Not sure what's up, but does it work for you now?
Maybe the initial request timed out or similar because it was loading up a lot of data?
Hmmm I've tried again today and got faster responses in general, but it still hangs and throws those errors when asking for 2022 data. Maybe there is some kind of bottleneck in the data querying that becomes more/less of a bottleneck depending on load? Maybe we're running into resource constraints on the machine this service is running on?
Asking for a location breakdown for year 2022 just resulted in:
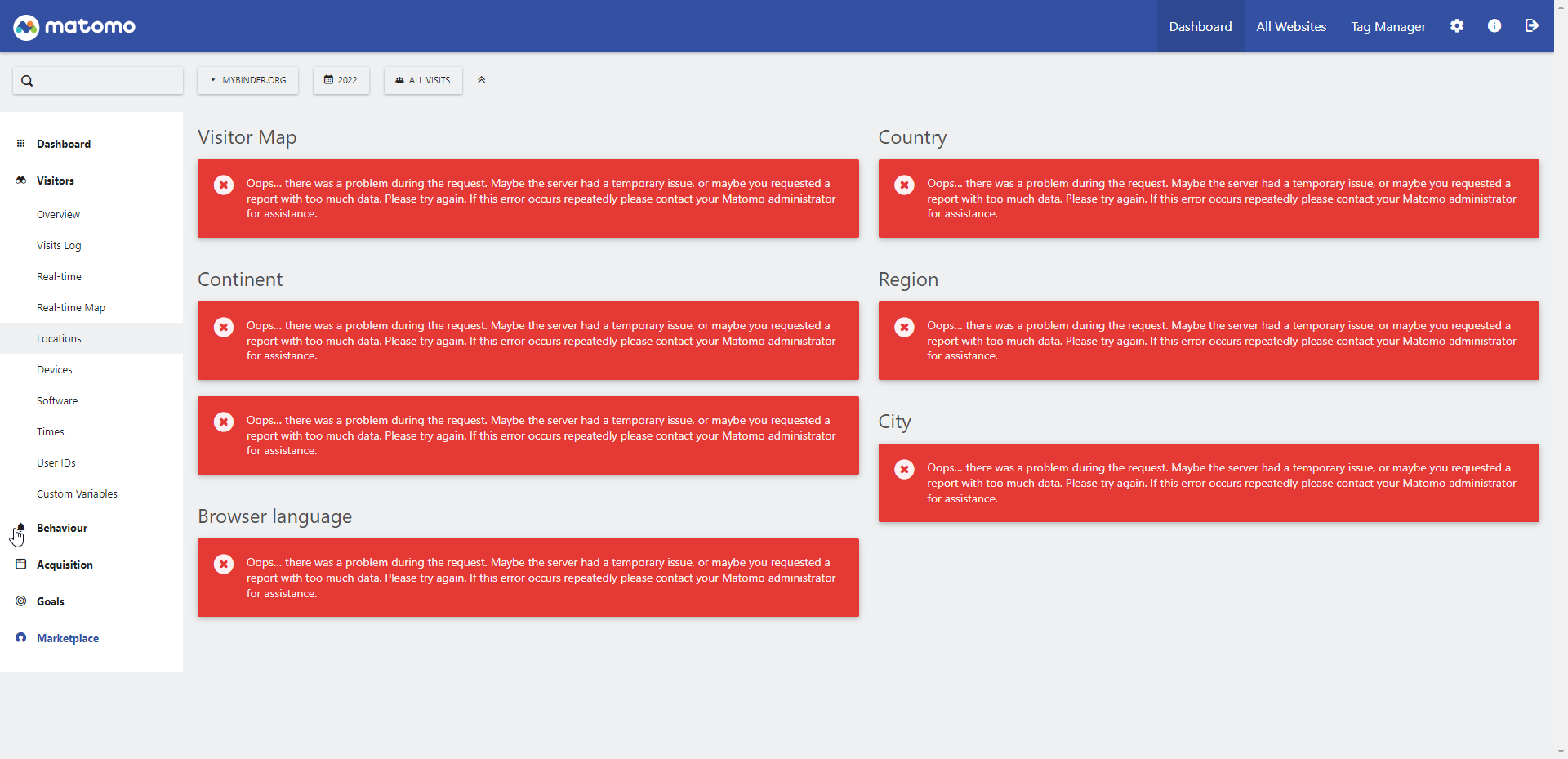
I have ~0 experience with matomo and this setup, but my debugging strategy would be to inspect logs of matomo which I think is running inside the k8s cluster on the GKE federation member. I'm not doing this right now, if you think I should @choldgraf let me know and I'll drop something else.
I also have no idea how the Matomo service works (and I couldn't find it documented in our team compass but I did find this documentation in our binder SRE guide). I think it'd be helpful to add a "how to debug matomo" guide to those docs. Maybe @minrk knows how to do that?
I've never debugged matomo because I've never encountered a bug with it before. We just turned it on and it's worked so far! I only got as far as looking at logs (stern matomo) to start trying to find errors when the errors stopped happening (I never did find an error, even scrolling back through what should have included the error, I think), but I stopped looking when the errors stopped happening. So my knowledge of debugging matomo can be summarised as: it's called matomo and deployed on prod, so that's where I can look for logs. The rest is learning as we go.
So there aren't any errors in the logs even though those error UI elements are popping up? I am not really sure what to do then...it seems like "give me the visitors behavior over the last year" is a pretty standard query no?
Note that their FAQ page about this error message has a suggestion for how to resolve it:
The most common solution to the message Oops... there was a problem during the request. is to setup Auto-Archiving in your Matomo by following these two steps:
a) Enabling the crontab to run the core:archive command and b) Disabling “Archive reports when viewed from the browser” in the General Settings.
I don't know how to do either of these things but perhaps this wouldn't be difficult to do?
Another datapoint: Matomo is hanging for me on a much smaller query: "Entry page statistics in the last 1.5 months".
There are some performance warnings on our mysql instance, so I'll try to look into those, they could be relevant.
A related question to this: would plausible.io be more cost-effective and labor-effective?
Their pricing is based on page visits, and since mybinder.org basically bounces people as soon as they hit the page, that number should still be relatively low. In March, we had something like 190k visits. According to plausible.io's pricing page, traffic of that volume would be covered by ~$30 a month.
So for $30 month we would get the same quality of user tracking, in a privacy friendly way, without paying any cloud costs or incurring any maintenance costs. Does that make it a better-sounding proposition than hand-rolling our own Matomo instance?
edit: Apparently Matomo has their own paid plan as well. Could we just pay them the 20 euros a month and not have to worry about the Matomo aspect of our deployment at all? That feels pretty cheap to me.
If we have some basic funds available to spend on this kind of thing, absolutely. In the past, it's been the difference between "we have hosting costs covered, but no funds we can just spend." that made self-hosted the available choice.
If we do have anything in that pot from NumFocus, I suggest we use it on a hosted matomo subscription rather than running it ourselves. If we can use some of the GESIS funds to cover this cost, we could do that too. Does that make sense?
EDIT: I removed a bunch of the above because I had obviously not read your comment closely enough 😆
The scientific python project already has an instance of plausible.io, maybe this can be a part of that?
I'd be happy with that, but I don't know how to utilize that instance. Do you know how? Maybe @stefanv has guidance?
I do use it for NetworkX, but need to go through @stefanv for the initial setup.
Add the following to your HTML:
<script defer data-domain="mybinder.org" src="https://views.scientific-python.org/js/script.js"></script>
While we keep the service maintained to the best of our abilities, we do not have any backup in place; i.e., feel free to use it, but consider the data ephemeral.