Implementing HA Active/Active with distributed file system
Hi kevin,
We are trying to implement the HA active/active.as you mentioned here https://github.com/jupyter/enterprise_gateway/issues/562#issuecomment-458203989 we are able to handle the scenario3" logic to the kernel web handlers such that if a request comes in for an unknown kernel ID, we attempt to re-establish connections to that kernel using persisted state (if any)".we had tested one scenario by running 2 instances of enterprise gateway and launched 4 spark-python yarn cluster kernels.in that i killed killed one instance by using kill-9 process id .after that i checked my kernels out of them two are responding other two are not responding.if i do reconnect or close & open my notebook it is working.
I need your help in understanding how only two of them are working with out reconnect.
@saipradeepkumar - this is really great news actually! Thank you for taking a deeper look into this.
Regarding the timing of things... It sounds like you ...
- Started 2 EGs before any kernels were started.
- Then you started 4 kernels.
- Then killed one EG.
- Then you issued subsequent requests for each of the 4 kernels and found 2 required reconnects while the other 2 did not.
Is that a correct reflection of the scenario?
Off the top of my head, I'm not sure. Have a couple questions...
Could the 2 kernels that didn't require reconnects been serviced by the "other" EG from the outset? I.e., are these behind an LB or reverse proxy of some sort?
Are each of the "subsequent requests" the same kind of thing?
Do the logs for the "other" EG indicate any kind of "auto-reconnect" entries happening at the time the "subsequent requests" are happening (or prior)?
Did you move the handlers from JKG to do this?
@saipradeepkumar - this is really great news actually! Thank you for taking a deeper look into this.
Regarding the timing of things... It sounds like you ...
- Started 2 EGs before any kernels were started.
- Then you started 4 kernels.
- Then killed one EG.
- Then you issued subsequent requests for each of the 4 kernels and found 2 required reconnects while the other 2 did not.
Is that a correct reflection of the scenario?
Off the top of my head, I'm not sure. Have a couple questions...
Could the 2 kernels that didn't require reconnects been serviced by the "other" EG from the outset? I.e., are these behind an LB or reverse proxy of some sort?
Are each of the "subsequent requests" the same kind of thing?
Do the logs for the "other" EG indicate any kind of "auto-reconnect" entries happening at the time the "subsequent requests" are happening (or prior)?
Did you move the handlers from JKG to do this?
@kevin-bates thank you for your quick reply. your understanding is correct.
below i am attaching screenshot of how i am creating [HA]
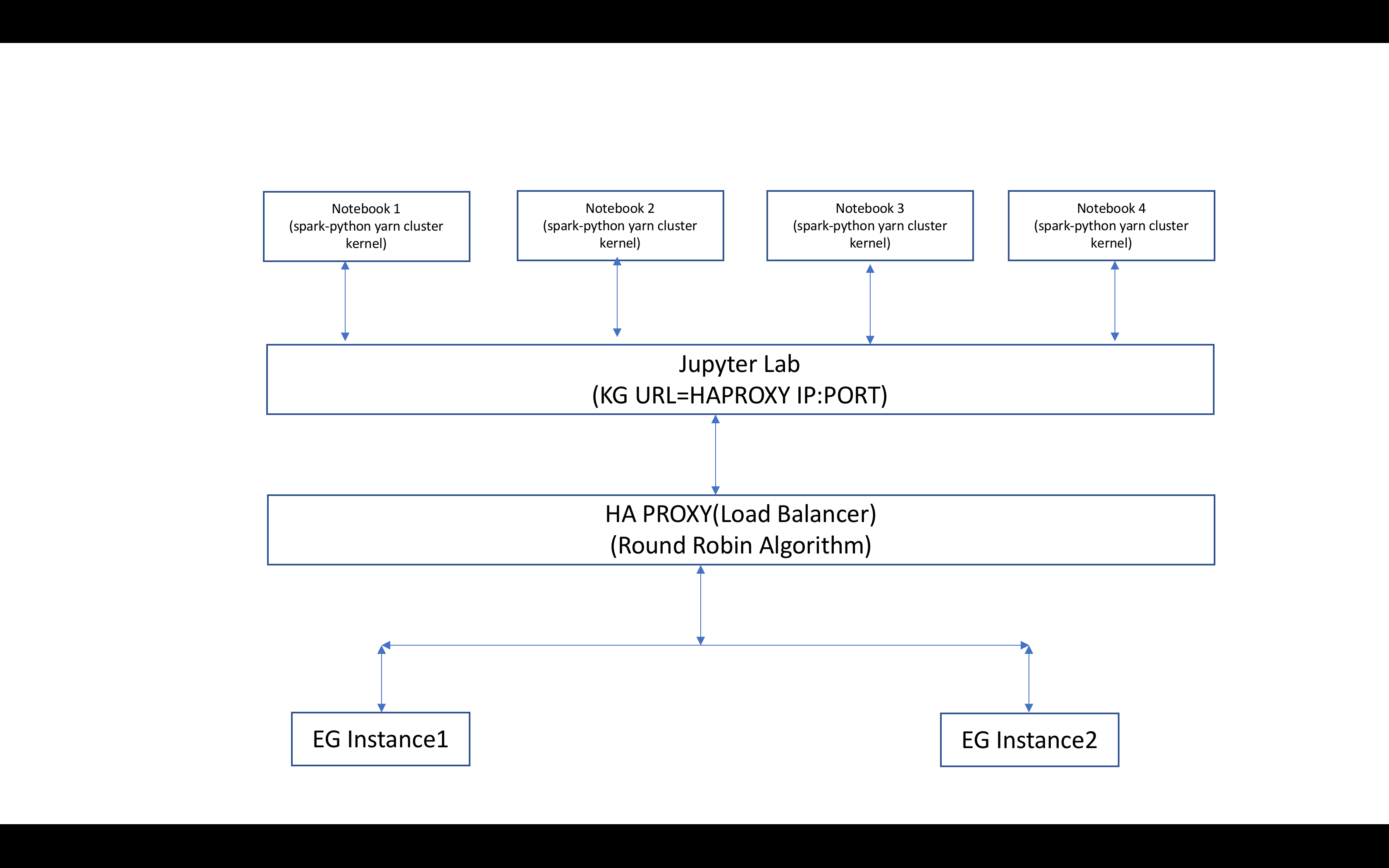
I had moved the handlers from JKG and created enterprise_websocket module and changed the api module to the package enterprise_websocket As explained in the image i am using ha proxy to route the traffic to the enterprise gateway instance using round robin algorithm.so kernel start can be on one instance and api request may be served by other instance of EG.whenever an instance of EG gets the request if the kernel is not present in that instance, it will try to refresh the session from the distributed store and start the kernel from session. so subsequent request can be served by this instance.
so in testing scenario, as i explained i had created 4 kernels ,out of them one kernel got created on instance 1,Other three on instance 2 .i killed the instance 2 .now when i sent the request from the kernels only two of them are responding . here what i am wondering is out of four kernels two kernels expecting reconnect command to make them active .But other two kernels one from instance 1 and one from instance 2 are working with reconnect command .
Thank you for the picture - truly worth a thousand words! 😄
ok - so 3 of the four kernels originated on instance 1 (which was killed) and, following their subsequent requests - which were then directed to the "long-lived" instance 2, one of the three didn't require reconnection. Correct? Yeah, that seems odd to me.
Are you sure that 3 of the 4 were actually on instance 1 and not, 2 on each? That would explain everything if the latter and that should have been the case in a RR configuration.
When the instance encounters a kernel id that it hadn't seen before, do you simply call into the kernel-session manager to reload the session?
It would be great to somehow get the reconnect to happen automatically, but I think that needs to come from the client. So, the next best thing would be know if the client can determine a reconnect is necessary, so it could auto-enable that action.
However, having this working even with manual intervention is pretty cool!
@kevin-bates
Thank you for the picture - truly worth a thousand words! 😄
ok - so 3 of the four kernels originated on instance 1 (which was killed) and, following their subsequent requests - which were then directed to the "long-lived" instance 2, one of the three didn't require reconnection. Correct? Yeah, that seems odd to me.
Are you sure that 3 of the 4 were actually on instance 1 and not, 2 on each? That would explain everything if the latter and that should have been the case in a RR configuration.
When the instance encounters a kernel id that it hadn't seen before, do you simply call into the kernel-session manager to reload the session?
It would be great to somehow get the reconnect to happen automatically, but I think that needs to come from the client. So, the next best thing would be know if the client can determine a reconnect is necessary, so it could auto-enable that action.
However, having this working even with manual intervention is pretty cool!
@kevin-bates as you said When the instance encounters a kernel id that it hadn't seen before, i am refreshing the kernel session by calling _load_sessions after that i am calling start_kernel_from_session. so that subsequent request are served
Great. And you're sure that the original spread of kernels wasn't 2 and 2, but actually 3 and 1?
If so, I'm not sure why 1 of the 3 failed-over kernels didn't require a reconnect.
Yeah i am sure because once the kernel has been started note book will start sending request for the status of kernel .by the time i create another kernel multiple request has been served by the two instances .in that case this scenario will happen.
if i have to determine the reconnect required on the client side ,I have to implement the reconnect automatically in NB2KG.am i right?
That's probably the right place to start.
Please note that NB2KG is now embedded in the notebook master branch - 6.0 release. So we'll need to "backport" any pure NB2KG changes. In addition, some of the handlers aren't present in the embedded version because the NB handlers simply call into the "substituted" kernel manager classes - that then forward the requests to the gateway.
@kevin-bates Thanks a lot for the response ,i will look in to NB2KG module . if any changes were made to automatically detect the reconnect we will definitely backport .
I don't think HDFS is an immediate goal. Ideally we'd prefer a NoSQL DB to make the persisted kernel sessions accessible from other EG nodes. However, if HDFS is the sharing "vehicle" and we use a file-based persistence model, that should work as well. I'm not confident this answers your question though. If not, could you please be more specific how you see HDFS coming into play here?
@saipradeepkumar - It has just dawned on me that the current kernel session persistence implementation (including the changes in #645) is geared toward an Active/Passive scenario. This is because the entire set of sessions are saved and loaded on each persistence. As a result, if deploying Active/Active, you'd wind up with a last-writer-wins behavior and sessions would be lost. I'm beginning to wonder if that loss is what you encountered with one of the sessions above.
If we want to move toward an Active/Active behavior, I think the persistence model needs to be more granular, occurring per session. In addition, I believe problems get much more complicated if we move away from sticky sessions. That is, the ONLY reason an existing session should "move" to a different EG instance is because its current instance has terminated. Otherwise, we have to figure out how to clear out the in-memory state in the first instance so that things like culling don't get triggered pre-maturely (as it thinks the kernel is idle, etc.).
The current behavior of loading all sessions when an EG instance starts, probably needs to be removed as well. We can only do this in Active/Passive scenarios since with Active/Active, we could be loading sessions that are currently hosted by another node. Instead, we should just trust the sticky sessions and "cache miss" behavior and load only those sessions in which the kernel cannot be found - implying its original instance is down. Of course, this could lead to "kernel leaks" since orphaned kernels will not be culled. An alternative would be to also store the name of the servicing node - but then we're in the business of having to determine if a previous servicing node is still running before taking control of the kernel - leading to heartbeat functionality, etc., etc.
Any way, I just wanted to mention this and check in with you.
Thanks.
@kevin-bates I noted down your points.i think we have to check deep on this .