aiwiki
 aiwiki copied to clipboard
aiwiki copied to clipboard
Published
20 hours ago •
 junxnone
junxnone
paper AnomalyCLIP
AnomalyCLIP
摘要
- ZSAD (Zero-shot anomaly detection) 因为领域隐私保密等问题无数据,需要辅助数据训练
- 辅助数据训练存在的问题: 泛化到不同领域存在前景对象,异常区域和背景特征不同的差异
- VLM(CLIP) 的在视觉方面表现强劲,但是在 ZSAD 方面比较弱,原因是 VLM 更关注前景对象的的类语义
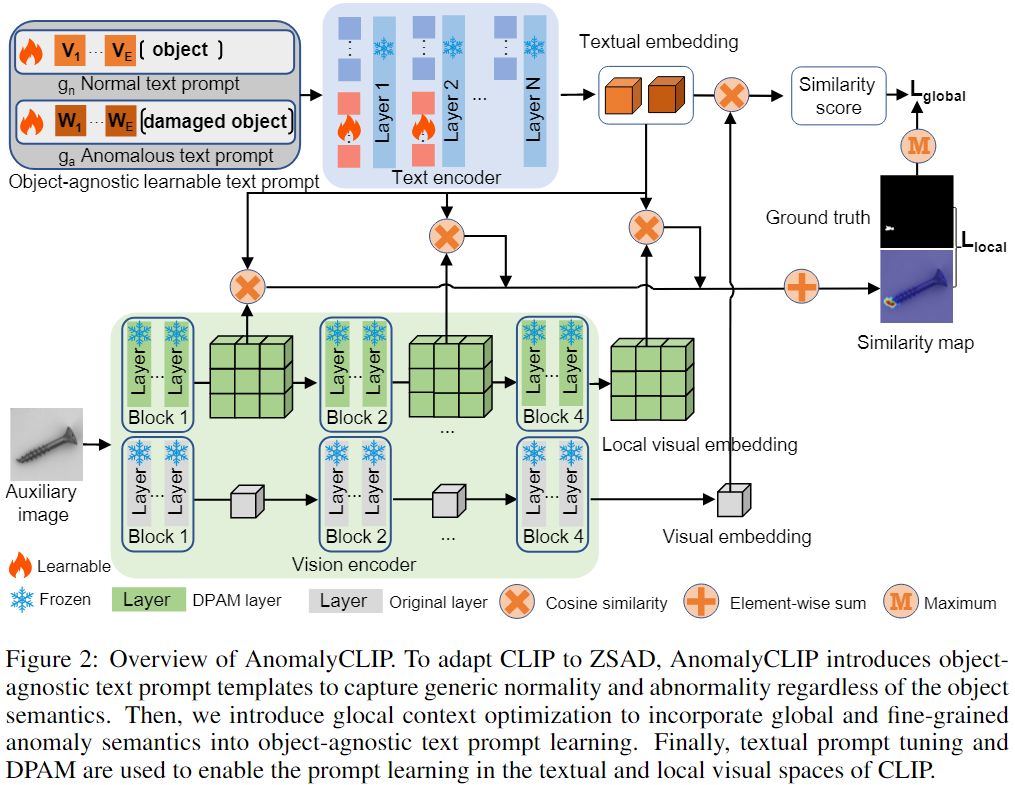
- 提出 AnomalyCLIP 用于提升 CLIP 在 ZSAD 方面的性能
- AnomalyCLIP 的关键在于学习与对象无关的提示词,以忽略其前景对象,捕获通用异常
- AnomalyCLIP 在17个缺陷检测数据集和医学数据集获得了较好的性能
简介
问题
- 现实情况中的数据集可用性(隐私/保密) 产生了 ZSAD 的需求
- 面临的挑战
- 视觉外观
- 前景物体
- 背景特征
现状
- VLM(CLIP) 在各个领域表现抢眼
- WinCLIP
- 为 ZSAD 手动设计了大量的提示词用于增强CLIP 的泛化能力
- 但是局限于CLIP 被用来理解类语义的目的,在 AD 领域表现出较差的泛化能力
- CoOP 使用了可学习的提示词
- 手动设计的提示和可学习的提示会导致提示词嵌入和目标语义的全局特征对齐,不能捕捉到更局部细粒度的异常
目的
- 基于 CLIP, 使其专注于异常区域,而非目标语义,提升其 ZSAD 在不同领域的泛化能力
方案
- 为 正常和异常类别设计了两个对象不可知的可学习 prompt template
- 利用图像级和像素级的损失函数来学习全局和局部的异常语义
- 文本提示调优和 DPAM 用于 CLIP 中 提示词和局部视觉空间的学习
- 使用 Vision Encoder 的多个中间层,学习更多的局部细节
- Glocal Context optimization:
- Refinement of textual space: 添加额外的可学习 token embedding 到 文本编码器
- Refinement of the local visual space: DPAM (Diagonally Prominent Attention Map) 用于在细粒度上优化分割图
- Inference 时使用相似度得分作为图像级异常分数,像素级使用合并的中间层分割(插值/平滑)
- Grounding-DINO-T --> Swin-T
- Grounding-DINO-L --> Swin-L
Text Prompts
-
object-aware text prompt templates -
object-agnostic text prompt templates
prompt_normal = ['{}', 'flawless {}', 'perfect {}', 'unblemished {}', '{} without flaw', '{} without defect', '{} without damage']
prompt_abnormal = ['damaged {}', 'broken {}', '{} with flaw', '{} with defect', '{} with damage']
训练细节
- Backbone: CLIP(VIT-L/14@336px), 冻结所有参数
- 可学习 Prompt 的长度为 12
- 可学习 token embedding 为前 9 层,每层长度为 4
- 使用 mvtec 数据集训练,以评估其他数据集,使用 VisA 数据集训练,以评估 mvtec
结果对比
- 对比了 CLIP/CLIP-AC/WinCLIP/VAND/CoOp/AnomalyCLIP 模型
- 在工业和医学数据集上都有较好的表现
- 工业数据集 MVTec/VisA/MPDD/BTAD/SDD/DAGM/DTD-Synthetic
- 医学成像数据集(模型训练使用 MVTec) HeadCT/BrainMRT/Br35H/COVID-19/ISIC/CVC-ColonDB/CVC-ClinicDB/Kvasir/Endo/TN3K
Test
- 提供了两个预训练模型(Grounding-DINO-T)
- 在
MVTec AD数据集上训练模型,测试其他数据集 - 在
VisA数据集上训练模型,测试MVTec AD
- 在
Reference
- [AnomalyCLIP: Object-agnostic Prompt Learning for Zero-shot Anomaly Detection] [code]
- OpenReview for AnomalyCLIP