WeeklyArxivTalk
 WeeklyArxivTalk copied to clipboard
WeeklyArxivTalk copied to clipboard
[20230212] Weekly AI ArXiv 만담 시즌2 - 5회차
News
- Microsoft의 Bing, Edge에 ChatGPT 탑재, Your copilot for the web
- Google의 Paris 초거대 AI 발표 그리고 Bard 해프닝
- AI미래포럼-공학한림원 공동 웨비나: 초거대 AI시대 AI반도체 다시보기
ArXiv
-
Offsite-Tuning: Transfer Learning without Full Model
- Foundation model 본체 없이 Fine-tuning 하는 방법 (from MIT Song Han )
- Privacy나 보안등의 이슈로 데이터 공유가 힘들 때. (Foundation model 본체는 당연히 공유 안됨)
- Adapter 와 Foundation model emulator 를 Off Site로 보내서 튜닝하고 Adapter는 다시 받아옴. 그리고 Inference 하면됨
- Adapter 와 Emulator는 각각 더 잘 만들 방법이 있으나 여기서는
- Adapter: shallow and deep Transformer layer 몇개
- Emulator: Layer drop후 KD한 것: 본체만큼 정확할필요는 없고 gradient 방향만 유사하게 동작하면 됨 (너무 똑같으면 본체 가진 회사가 싫어함)
- 전반적으로 경쟁력이 꽤 있는 편. 물론 작은 모델 중심으로 평가되고 adapter, emulator 모두 Naive 한데 개선의 가능성이 높음


-
재미있는 연구

Arxiv
-
Speak, Read and Prompt: High-Fidelity Text-to-Speech with Minimal Supervision
- Keyword : TTS
- Sample URL : https://google-research.github.io/seanet/speartts/examples/
- 적은 데이터 만으로 고품질의 음성을 생성할 수 있는 다화자 TTS 모델을 제안함
- Figure 1처럼 TTS를 text로부터 semantic token으로 변환하는 단계(Reading), semantic token에서 acoustic token으로 변환하는 단계(Speaking) 두 단계로 나누어 학습함

- 첫 번째 단계는 parallel dataset을 이용하여 discrete semantic token (text content) 정보만이 나오도록 함
- w2v-BERT 를 이용하여 speech representation을 얻고 k-means clustering을 이용하여 k개의 센터값을 token으로 사용
- audio-only dataset을 이용하여 synthetic dataset을 만들어 적은양의 데이터를 보완

- 두 번째 단계는 audio dataset만을 이용하여 학습하고 speaker ID 대신 audio sample을 prompt로 넣음
- SoundStream을 통하여 acoustic token을 추출하여 사용
- 학습 시 1) prompt로 얻은 semantic tokens, 2) target으로부터 얻은 semantic tokens, 3) prompt로 얻은 acoustic tokens를 순서대로 입력으로 넣어주고 target으로부터 얻은 acoustic token을 output으로 내보냄

- 데이터 셋은 LibriTTS - audio-only (551 시간, 247 명), LJSpeech (15분만 사용, 1명)
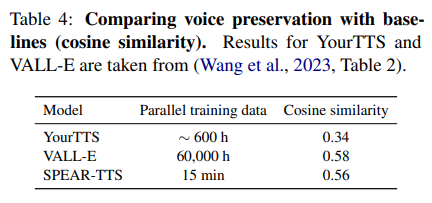
- zero-shot learning 모델인 YourTTS와 VALL-E와 성능을 비교
- WavLM기반의 verification system 이용하여 prompt와 합성음의 embedding vector를 만들고 두 벡터의 유사도를 구함
- YourTTS보다 좋고, VALL-E와 유사한 성능을 보인다.
- MOS를 보면 SPEAR-TTS는 gt보다 높다

- VALL-E 보다 좋은 성능을 보여줌

흥미로운 연구
-
Noise2Music: Text-conditioned Music Generation with Diffusion Models
- Keyword : Music Generation, Diffusion
- Sample URL : https://google-research.github.io/noise2music/
- Diffusion 모델을 이용하여 text prompt (장르, 템포, 악기, 분위기(Mood) 등 포함)로부터 24k 음악을 생성
- music-text joint embedding을 이용하여 오디오 클립에 pseudo label을 달아 150k의 데이터셋 사용
- MuLan-LaMDA 데이터셋 : 400k (music-text pairs

HuggingFace PEFT:
Blog: https://huggingface.co/blog/peft GitHub: https://github.com/huggingface/blog
HuggingFace에서 Parameter-Efficient Fine-Tuning을 위한 새로운 라이브러리를 공개했습니다. 기존 LLM을 특정 task를 위해 fine tuning을 진행하기 위해서는 메모리로 인해 학습이 어려웠는데 HuggingFace ecosystem과 호환되는 라이브러리를 통해 대부분의 parameter를 freeze한 채로 fine-tuning하는 작업을 진행할 때 메모리 사용량을 크게 낮추어 학교에서도 사용할 수 있는 11GB GPU에서도 LoRA와 같은 3Billion 모델을 간편하게 학습할 수 있도록 합니다. 리소스가 충분하지 않은 많은 연구원에게 LLM을 접근하기 쉽게 한다는데 의의가 있다고 생각됩니다.
예시 코드:
from transformers import AutoModelForSeq2SeqLM
+ from peft import PeftModel, PeftConfig
peft_model_id = "smangrul/twitter_complaints_bigscience_T0_3B_LORA_SEQ_2_SEQ_LM"
config = PeftConfig.from_pretrained(peft_model_id)
model = AutoModelForSeq2SeqLM.from_pretrained(config.base_model_name_or_path)
+ model = PeftModel.from_pretrained(model, peft_model_id)
tokenizer = AutoTokenizer.from_pretrained(config.base_model_name_or_path)
model = model.to(device)
model.eval()
inputs = tokenizer("Tweet text : @HondaCustSvc Your customer service has been horrible during the recall process. I will never purchase a Honda again. Label :", return_tensors="pt")
with torch.no_grad():
outputs = model.generate(input_ids=inputs["input_ids"].to("cuda"), max_new_tokens=10)
print(tokenizer.batch_decode(outputs.detach().cpu().numpy(), skip_special_tokens=True)[0])
# 'complaint'
Attending to Graph Transformers:
ArXiv: https://arxiv.org/abs/2302.04181v1 GitHub: https://github.com/luis-mueller/probing-graph-transformers

Graph Transformer에 대한 리뷰 및 기존 GNN과의 차이점에 대한 주장에 대한 실험이 섞인 독특한 논문입니다.
Graph Transformer는 positional embedding을 통해서 graph connectivity를 주입하는데 다른 encoding 방법에 대한 비교, 그리고 기존 GNN과 비교했을 때 Graph의 구조를 이해할 수 있는 능력, 그리고 oversmoothing을 극복할 수 있는지 등에 대해 비교합니다.

A Categorical Archive of ChatGPT Failures: ArXiv: https://arxiv.org/abs/2302.03494
ChatGPT/LLM error tracker: https://garymarcus.substack.com/p/large-language-models-like-chatgpt
ChatGPT의 오류가 대두되면서 여러 종류를 분석한 논문입니다. 공유드린 블로그에서 영감을 얻었다는데 비전문가에게 설명할 때 좋은 자료라고 생각됩니다.

Mnemosyne: Learning to Train Transformers with Transformers: ArXiv: https://arxiv.org/abs/2302.01128 Blog: https://sites.google.com/view/mnemosyne-opt
Learning to learn 계통에서 linear transformer를 사용하는 것에 관한 논문입니다. 실용성은 상대적으로 떨어지지만 현재 학습하는 것처럼 특정 optimizer를 heuristic하게 정하는 것보다 teacher network를 학습해 optimizer의 역할을 하게 하고 target network의 gradient를 제공받았을 때 학습된 network의 결과에 따라 parameter update를 진행합니다. 해당 논문에서는 MNIST에서 MLP student에 대해 meta-training을 진행한 Performer를 Vision Transformer 모델의 CIFAR 학습에 사용했을때에도 우수한 성능을 보인다는 것을 보여줍니다.

ChatGPT Is a Blurry JPEG of the Web (9 Feb, 2023)
https://www.newyorker.com/tech/annals-of-technology/chatgpt-is-a-blurry-jpeg-of-the-web
- Kyunghyun Cho Twit 에서 추천 (https://twitter.com/kchonyc/status/1624633568734355456) 예전 Cho 발표 내용과 비슷한 관점 (https://drive.google.com/file/d/1dk3o-fcdH1Y7-rGGqlVR35AZ1CVwz0qi/view)
- LLM은 Web에 대한 일종의 lossy compression으로 본다면 어쩔수 없는 artifact가 생김.
- Hallucination (Factual Error) 문제가 발생하는 이유에 대한 매우 직관적인 설명 (비 ML분야 분들에게 강추)
- LLM은 무손실 압축이 아니므로, ChatGPT로 생성되는 텍스트가 Web에 계속 올라온다면, Web의 신뢰성은 점점 더 안좋아질 것임. 미래의 LLM이 이런 텍스트로 학습된 후, 이로 생성된 텍스트가 Web에 계속 올라간다면.. (개인의견 : 인터넷 디스토피아가 펼쳐질수도?)
- 독창적이지 않은 글을 쓰는데 ChatGPT를 활용하는 것이 학생들의 교육에 안좋은 영향을 끼칠 듯.
Data Selection for Language Models via Importance Resampling (6 Feb, 2023, https://arxiv.org/abs/2302.03169)
-
noisy한 web data에서 우리가 원하는 sample만을 뽑는 방법 (일종의 filtering)
- Large raw data에서 target data와 분포가 비슷한 subset을 골라내서 학습에 활용
- 보통은 heuristic classifier를 사용하는데 (GPT-3/The Pile/PaLM), 이는 target data와 distribution이 일치하리라는 보장이 없음.

-
DSIR (Data Selection with Importance Resampling)
- raw / target data에서 hashed n-gram feature (1, 2 grams) 를 뽑음.
- 이를 이용해서 feature-space에서 확률분포를 구함 (p, q)
- 이 확률분포로 raw data 각 sample에 대한 importance weights를 구함.
- 이를 normalization 해서 이 확률로 raw data에서 다시 sampling

-
KL reduction : data selection의 quality measure
- Downstream Accuracy와 매우 큰 상관관계


- Downstream Accuracy와 매우 큰 상관관계
-
Selecting Data for Domain-Specific Continued Pretraining 에서 성능 향상

-
Selecting Data for Training General-Domain LMs 에서 성능 향상
- GLUE Benchmark에서 Random Selection 대비 2% 성능 향상

- GLUE Benchmark에서 Random Selection 대비 2% 성능 향상
-
Selected Data 예제

A Categorical Archive of ChatGPT Failures (6 Feb, 2023, https://arxiv.org/abs/2302.03494)
- ChatGPT가 실패하는 케이스들을 잘 분류해 놓음.
- Gary Marcus 나 다른 twitter user가 모아놓은 것)
- Spatial/Physical/Temporal/Psychological/Logical Reasoning





- Math / Arithmetic

- Factual Errors


- Bias / Discrimination

- Wit / Humor
- Coding
- Syntactic Structure, Spelling, and Grammar

- Self Awareness
Theory of Mind(ToM) May Have Spontaneously Emerged in Large Language Models (4 Feb, 2023, https://arxiv.org/abs/2302.02083)
- 다른 사람의 Mental States를 이해하는 능력을 여러가지 LLM에 대해서 Test
- 2022년 이전에 발표된 LLM에서는 ToM 능력이 거의 전혀 없음.
- 2022년 이후의 LLM은 ToM 능력이 있는데, 특히 text-davinci-002이 70% (7살 어린이 수준), 003이 93%(9살 어린이 수준)로 탁월함.
- 결론 : 따로 ToM 관련 모듈이나 아키텍쳐를 만들지 않아도 LLM 일반 능력을 올리면 자연스럽게 ToM 능력이 Emergent 한다.

- 결과

State of the AI Report 2022
Industry
- Do upstart AI chip companies still have a chance vs. NVIDIA’s GPU?
NVIDIA 2021년 매출은 106억 달러, 4분기에만 32억 6천만 달러이며 이것은 연간 기준으로 상위 3개 AI 반도체 스타트업의 기업가치를 합친 것보다 많습니다

GPU는 ASIC보다 131배 더 많이 사용되며, Graphcore, Habana, Cerebras, SambaNova, Cambricon의 칩을 합친 것보다 90배 더 많이 사용되고, Google의 TPU보다 78배 더 많이 사용되며, FPGA보다 23배 더 많이 사용됩니다.

2017년에 출시된 V100은 NVIDIA의 주력 칩이며, 2020년에 출시된 A100이 그 뒤를 잇고 있습니다. 2022년에는 H100이 출시될 예정입니다. 주요 AI 칩 도전자 중 그래프코어가 가장 자주 언급됩니다.

400억 달러로 발표되었던 NVIDIA의 Arm 인수 시도는 지정학적 문제와 경쟁사의 반발로 인해 실패로 돌아갔습니다. 그럼에도 불구하고 NVIDIA의 기업 가치는 이 기간 동안 2950억 달러가 증가했습니다.

-
하이퍼스케일러와 챌린저 AI 컴퓨팅 제공업체들은 주요 AI 컴퓨팅 파트너십을 체결하고 있으며, 특히 Microsoft가 OpenAI에 10억 달러를 투자한 것을 주목할 만합니다. 앞으로 더 많은 투자가 있을 것으로 예상됩니다.

-
기업들은 국가 슈퍼컴퓨터보다 더 큰 슈퍼컴퓨터를 구축합니다. "가장 큰 컴퓨터를 가진 사람에게 가장 많은 혜택이 돌아갈 것으로 생각합니다." - Greg Brockman, OpenAI CTO

-
AI 분야에서 정부 계약의 복합적 효과 1962년 미국 정부는 전 세계의 모든 집적 회로를 구입하여 이 기술과 최종 시장의 개발을 강화했습니다. 일부 정부는 AI 기업을 위한 "최초의 구매자"로서 그 기회를 다시 제공하고 있습니다. 고유한 고품질 데이터에 액세스할 수 있는 기업은 소비자 또는 엔터프라이즈 AI 소프트웨어를 구축하는 데 있어 우위를 점할 수 있습니다.

-
메타가 2022년 8월에 무료로 공개적으로 사용할 수 있는 블렌더봇3 챗봇을 출시했을 때, 이 챗봇이 잘못된 정보를 뱉어내 언론의 뭇매를 맞았습니다. 한편, 2021년 5월에 챗봇 LaMDA에 대한 논문을 발표했던 구글은 이 시스템을 사내에 유지하기로 결정했습니다. 하지만 블렌더봇이 출시된 지 몇 주 후, 구글은 일반 사용자들이 LaMDA를 포함한 구글의 최신 AI 에이전트와 상호작용할 수 있는 'AI 테스트 키친'이라는 대규모 이니셔티브를 발표했습니다.
- 구글과 페이스북의 10억 명 이상의 사용자에게 AI 시스템을 대규모로 공개하는 것은 우연이건 적대적인 질의에 의해서건 이러한 시스템의 모든 윤리 또는 안전 문제가 드러날 수밖에 없습니다. 하지만 이러한 시스템을 널리 공개해야만 이러한 문제를 해결하고 사용자 행동을 이해하며 유용하고 수익성 있는 시스템을 만들 수 있습니다.
- 이러한 딜레마에서 벗어나고자 LaMDA를 소개하는 논문의 저자 중 4명은 "혁신적인 개방형 대화형 애플리케이션을 만드는 AI 회사"라고 스스로를 소개하는 Character.AI를 설립/합병했습니다.
- 티어 1 AI 연구소의 인재들이 독립하여 기업가로 거듭나고 있습니다. 졸업생들은 AGI, AI 안전, 생명공학, 핀테크, 에너지, 개발 도구 및 로봇 공학 분야에서 일하고 있습니다. 트랜스포머 기반 신경망을 소개한 획기적인 논문의 저자 중 한 명을 제외하고는 모두 구글을 떠나 AGI, 대화형 에이전트, AI 우선 생명공학 및 블록체인 분야에서 스타트업을 설립했습니다.


-
AI 코딩 어시스턴트가 빠르게 배포되고 개발자 생산성 향상에 대한 초기 징후가 나타나고 있습니다. OpenAI의 Codex는 연구(2021년 7월)에서 상용화(2022년 6월)로 빠르게 발전하여 현재 월 10달러 또는 연간 100달러에 공개적으로 사용할 수 있는 (마이크로소프트의) GitHub Copilot을 출시했습니다. 아마존은 2022년 6월에 CodeWhisperer를 프리뷰 버전으로 발표하며 그 뒤를 따랐습니다. 구글은 내부적으로 머신러닝 기반 코드 완성 도구를 사용하고 있다고 밝혔습니다.
-
2020년 0개에서 18개로 늘어난 AI 우선 신약 개발 기업의 임상시험 수 초기 발견 단계에 있는 자산은 더 많습니다. 2023년부터는 초기 임상시험 결과가 나올 것으로 예상됩니다.

하지만 2011년부터 2020년까지 6,151건의 성공적인 임상시험 단계 전환에 대한 연구에 따르면 의약품이 규제 당국의 승인을 받는 데 평균 10.5년이 걸리는 것으로 나타났습니다. 여기에는 임상 1상 2.3년, 임상 2상 3.6년, 임상 3상 3.3년, 규제 단계 1.3년이 포함됩니다. 또한 임상시험에 환자 한 명을 모집하는 데 평균 6.5만 달러가 소요됩니다. 결국 30%의 환자가 규정 미준수로 인해 중도 탈락하므로, 전체 모집 비용은 환자당 19.5만 달러에 육박합니다. AI는 더 나은 약을 더 빨리 개발할 수 있다고 약속하지만, 현재 임상시험의 물리적 병목현상을 해결해야 합니다.
mRNA 백신의 선두주자인 BioNTech와 엔터프라이즈 AI 기업인 InstaDeep은 고위험 변종을 예측하기 위해 조기 경보 시스템(EWS)을 공동으로 구축하고 검증했습니다. EWS는 공식적으로 지정되기 평균 1개월 반 전에 WHO가 지정한 16가지 변종을 모두 식별할 수 있었습니다.
빨간색 점선은 EWS가 해당 변종이 고위험이라고 예측한 날짜를, 녹색 점선은 WHO가 해당 변종을 지정한 날짜를 나타냅니다. 거의 모든 경우에서 EWS는 WHO 지정 몇 달 전에 경고를 보냈습니다.

-
대학은 Databricks, Snorkel, SambaNova, Exscientia 등 AI 기업의 중요한 원천입니다. 영국에서는 영국 전체 기업의 0.03%에 비해 4.3%의 AI 기업이 대학에서 스핀아웃된 기업입니다. AI는 실제로 스핀아웃이 가장 많이 형성되는 분야 중 하나입니다.

-
2022년, AI를 사용하는 스타트업에 대한 투자는 시장 확대와 함께 둔화되었습니다. AI를 사용하는 민간 기업의 2022년 투자액은 작년 대비 36% 감소*할 것으로 예상되지만, 여전히 2020년 수준을 상회할 것으로 예상됩니다. 이는 전 세계 모든 스타트업 및 스케일업에 대한 투자와 비슷한 수준입니다.

VC 투자 감소는 1억 달러 이상의 라운드에서 가장 두드러지는 반면, 소규모 라운드는 2022년 말까지 전 세계적으로 309억 달러에 달할 것으로 예상되며, 이는 2021년 수준과 거의 비슷한 수준입니다.

미국이 AI 유니콘 수 1위, 중국과 영국이 그 뒤를 잇고 있습니다. 미국은 292개의 AI 유니콘을 탄생시켰으며, 총 기업 가치는 4조 6천억 달러에 달합니다.

AI를 사용하는 미국 기반 스타트업 및 스케일업에 대한 투자가 크게 감소했지만, 여전히 전 세계 AI 투자의 절반 이상을 차지하고 있습니다.

엔터프라이즈 소프트웨어는 전 세계적으로 가장 많은 투자를 받은 분야이며, 로보틱스는 AI에 대한 VC 투자에서 가장 큰 비중을 차지하고 있습니다.

기업공개(IPO)와 스팩(SPAC) 기업공개 건수는 급격히 감소했지만, 인수 건수는 2021년 수준을 초과할 것으로 예상됩니다.

Predictions
9 predictions for the next 12 months
- A 10B parameter multimodal RL model is trained by DeepMind, an order of magnitude larger than Gato.
- NVIDIA announces a strategic relationship with an AGI focused organisation.
- A SOTA LM is trained on 10x more data points than Chinchilla, proving data-set scaling vs. parameter scaling
- Generative audio tools emerge that attract over 100,000 developers by September 2023.
- GAFAM invests >$1B into an AGI or open source AI company (e.g. OpenAI).
- Reality bites for semiconductor startups in the face of NVIDIA’s dominance and a high profile start-up is shut down or acquired for <50% of its most recent valuation.
- A proposal to regulate AGI Labs like Biosafety Labs gets backing from an elected UK, US or EU politician.
- >$100M is invested in dedicated AI Alignment organisations in the next year as more people become aware of the risk we are facing by letting AI capabilities run ahead of safety.
- A major user generated content side (e.g. Reddit) negotiates a commercial settlement with a start-up producing AI models (e.g. OpenAI) for training on their corpus of user generated content.