WeeklyArxivTalk
 WeeklyArxivTalk copied to clipboard
WeeklyArxivTalk copied to clipboard
Published
20 hours ago •
 jungwoo-ha
jungwoo-ha
[20230205] Weekly AI ArXiv 만담 시즌2 - 4회차
News
- Conferences
- AAAI 2023: Washington DC (2. 7 - 14)
-
Google Cloud가 Anthropic과 손을 잡고 MS + OpenAI 조합에 대항?
- 30억 달러 투자 단행, AI Safety 협업
- Claude 가 GCP위에서 Open beta 서비스를 Free로 한다면?
- MS Teams에 ChatGPT 반영
- Bing에 ChatGPT가 합해지면 이런 모습이라는데..
- 기회도 만들지만 위험도 만들어”…유럽연합, ‘챗GPT’에 제동
-
ITU AI for Good 웨비나: AI for improved health and well-being at all ages
-
-
- 6, 오후 5시
-
-
-
AI미래포럼 초거대 AI시대 AI반도체 웨비나
-
-
- 10, 오전 10시
-
- 네이버 클라우드 이동수님, 리벨리온 박성현 대표님, KAIST & Hyper Accel 김주영 교수님 + 과기정통부 윤두희 과장님 출동
-
ArXiv
-
Dreamix: Video Diffusion Models are General Video Editors
- Inferece time에 이미지, 비디오 와 text prompt를 입력받아 비디오를 변환하는 Video diffusion model (VDM)연구 (from Google Research)
- VDM을 video로만 finetune하면 모션 변화에 취약하다고함. 그래서 Temporal attention FT도 하지만 비디오의 Unordered frame들로 Temporal Attention/Conv 를 Frozen하고 Temporal attention masking도 함께 joint 학습
- 기본적으로 물체 변환도 잘되고 prompt semantic에 맞게 잘 변환되는 것으로 보임
- 변환된 비디오에서 디테일이 상당히 사라지는 (배경도 물체도) 부분은 개선해가야할 점으로 보임
- 데모페이지: https://dreamix-video-editing.github.io/


-
Accelerating Large Language Model Decoding with Speculative Sampling --> 소개는 이동현님이 @dhlee347
- 초거대 언어모델에서 디코딩 속도 올리기 위해 제안하는 새로운 sampling 기법 (from DeepMind)
- 순서는 아래와 같습니다.
- Generating a short draft of length 𝐾. This can be attained with either a parallel model (Stern et al., 2018) or by calling a faster, auto-regressive model 𝐾 times. We shall refer to this model as the draft model, and focus on the case where it is auto-regressive.
- Scoring the draft using the larger, more powerful model from we wish to sample from. We shall refer to this model as the target model.
- Using a modified rejection sampling scheme, accept a subset of the 𝐾 draft tokens from left to right, recovering the distribution of the target model in the process.
- 그런데 사실 Google의 Fast Inference from Transformers via Speculative Decoding 랑 거의 같음. LAMDA vs. Chinchilla


-
신기한 Unconditional Infinite Outdoor Scene Generation 연구
- SceneDreamer (Google): https://scene-dreamer.github.io/
- InfinityCity (UC Merced & Snap): https://hubert0527.github.io/infinicity/
ArXiv (Audio and Speech Processing)
-
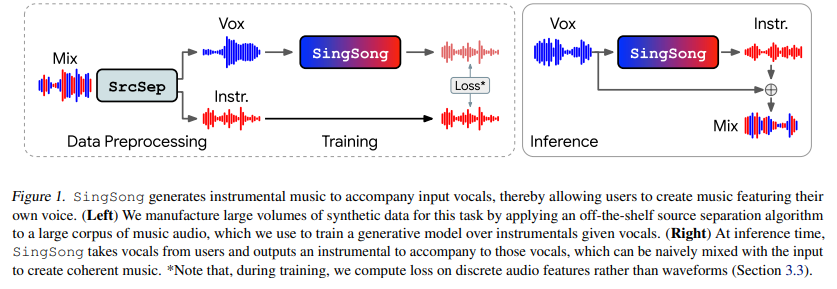
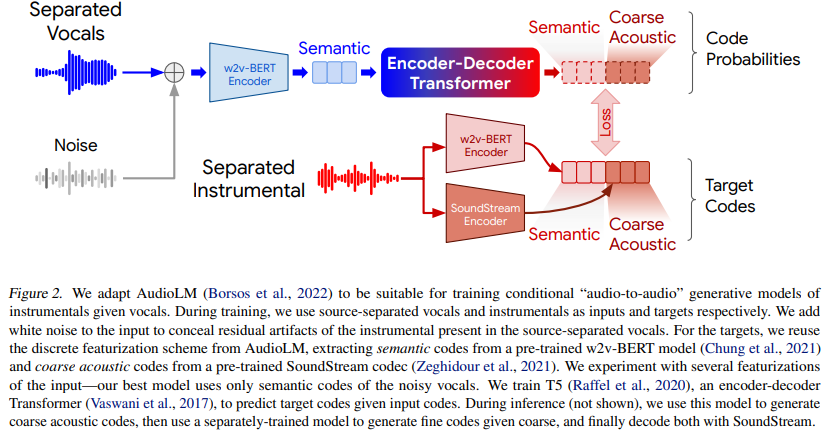
SingSong: Generating musical accompaniments from singing
- Keyword : vocal accompaniment
- Sample URL : https://storage.googleapis.com/sing-song/index.html
- vocal (노래)를 입력으로 주면 accompaniment (반주)를 만들어주는 모델
- pre-trained w2v-BERT와 SoundStream을 이용하여 semantic 정보와 acoustic feature를 추출
- 입력 vocal에서 semantic 정보를 추출하고 타겟 반주는 semantic 정보와 acoustic fature를 이용하는게 best
- source separation 모델로 뽑은 vocal에 대해 성능 저하 -> 모든 vocal에 노이즈를 추가하여 학습 -> 일반화 성능 up!
- 관련 있는 연구 : Pop2Piano : Pop Audio-based Piano Cover Generation
- 결과는 Frechet Audio Distance (FAD)를 이용하여 비교하거나 선호도 조사를 함
- 학습 데이터는 46k 시간의 음악, 평가는 MUSDB 18 dataset (10시간의 vocal, instrumental "stems")

-
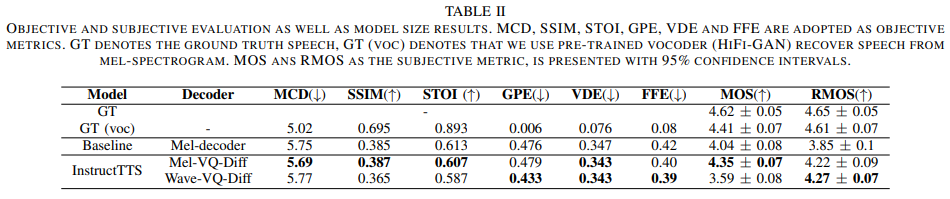
InstructTTS: Modelling Expressive TTS in Discrete Latent Space with Natural Language Style Prompt
- Keyword : TTS, prompt, diffusion
- Sample URL : http://dongchaoyang.top/InstructTTS/
- content text와 style prompt를 입력으로 expressive한 TTS를 만들어주는 모델
- 기존의 expressive TTS 방법론에서의 one-to-many 문제를 prompt 기반의 style로 해결
- PromptTTS와 다른 점은 PromptTTS는 5개의 스타일(성별, 피치, 속도, 크기, 감정)만 하지만 InstructTTS는 무형식!
- Style encoder로부터 prompt로 부터 semantic 정보를 추출하고 VQ를 이용하여 mel 대신 코드를 이용
- 관련 있는 연구 : PromptTTS: Controllable Text-to-Speech with Text Descriptions



Text-To-Audio Papers
-
Make-An-Audio: Text-To-Audio Generation with Prompt-Enhanced Diffusion Models
- Sample URL : https://text-to-audio.github.io/
- Text-To-Audio 를 위해서 필요한 text-audio pair가 부족한 것을 보완하기 위한 방법을 제안
- language-free audio를 이용하여 prompt를 강화하는 방법을 사용한 것이 특징
- image-to-audio generation, video-to-audio generation이 가능함
- 데이터 셋 : 3K 시간 (1M 개의 audio-text pairs)
- text condition으로 contrastive language-audio pretraining (CLAP)을 사용했는데 CLIP이나 BERT보다 성능이 좋음


-
AudioLDM: Text-to-Audio Generation with Latent Diffusion Models
- Sample URL : https://audioldm.github.io/
- 허깅페이스 데모 : https://huggingface.co/spaces/haoheliu/audioldm-text-to-audio-generation
- Make-An-Audio와 마찬가지로 CLAP representation을 사용, 여기선 latent diffusion model (LDM)을 학습
- zero-shot으로 텍스트를 조절하여 스타일을 변화시킬 수 있음
- 하나의 데이터셋 (AudioCaps)와 하나의 GPU 만으로 학습
- computational efficiency와 SOTA 급의 quality, audio manipulation을 모두 잡았다고 함
- 데이터 셋 : 5K 시간


-
Moûsai: Text-to-Music Generation with Long-Context Latent Diffusion
- Music samples for this paper: https://bit.ly/anonymous-mousai
- Music samples for all models: https://bit.ly/audio-diffusion
- Codes: https://github.com/archinetai/audio-diffusion-pytorch
- Music generation에 diffusion을 도입한 논문
- 하나의 consumer GPU로 real-time으로 만들겠다!?


Accelerating Large Language Model Decoding with Speculative Sampling
- LLM의 Sampling latency를 줄이려는 노력 (2~2.5x decoding speedup)
- 훨씬 가벼운 draft model이 길이 K의 짧은 draft 를 생성하게 한 후, 이것의 logit(혹은 prob)을 무거운 target model도 (병렬적으로) 계산하게 함.
- 그 비율을 이용해서 modified rejection sampling을 진행하여 최종적으로 target model의 확률분포에서 샘플링한 효과를 내게 함.
- 쉽고 간단한 토큰은 가벼운 draft model에서, 근데 그것이 너무 Target Model의 분포에서 벗어나려하면 무거운 target model에서 샘플링.


-
Result

-
Acceptance Rate

Open Assistant
- Stability 그룹에서 나온 chatGPT의 민주화(?) 버젼 https://open-assistant.io/ko https://github.com/LAION-AI/Open-Assistant https://www.youtube.com/watch?v=64Izfm24FKA (Yannic Kilcher)
Flan Collection
- Flan instruction tuning을 데이터셋 별로 상세하게 분석 https://arxiv.org/abs/2301.13688 https://ai.googleblog.com/2023/02/the-flan-collection-advancing-open.html




