django-storages
 django-storages copied to clipboard
django-storages copied to clipboard
Performance of the url() method
Hi there,
I'm wondering if there's a performance opportunity around the url() method used in templates, views, etc., to get the full URL of an Image stored in, say, Amazon S3. It seems to me that the storage engine will do much more than simply put together the file name and MEDIA_URL.
When I'm dealing with publicly-accessible items on S3, would I be better off simply putting those two values together instead of calling the url() method?
I'm using Django REST Framework and need to list 100+ images' URLs in one single request, which is currently heavy via the url() method — that was my motivator to try accessing these values directly.
What am I missing?
Many thanks!
@avorio I typically use Google storage and it has been optimized for public files. Unless you tell the storage that all the files are going to be Public, it has to make a round trip to AWS to check permissions, so it is going to be slow.
I've experienced this same issue recently (mostly due to generating different image sizes + thumbnails), endpoints were significantly (~10x) slower regardless of any prefetch related shenanigans attempted.
As a quick fix I've simply implemented custom serializers to build the URLs with the bucket url + file names, e.g., f'{settings.DEFAULT_BUCKET_URL}/{instance.file.name}'.
The next step was extending the S3Boto3Storage class and overriding its url(...) method.
Building the URL straight on the serializer ended up in better performance than overriding the S3Boto3Storage class though.
I was having trouble figuring this one out. I came up with a solution using something similar.
To make this easier for anyone else I created a package for pip with these mods: https://pypi.org/project/sorl-thumbnail-jdmueller/
And just add these to settings.py: MEDIA_URL = "https://" + os.environ.get("AWS_STORAGE_BUCKET_NAME", "bucket-name") + ".s3.amazonaws.com/" THUMBNAIL_FAST_URL = True
In it's current implementation it seems that specifying AWS_S3_CUSTOM_DOMAIN (to bucket domain name) skips any unnecessary communication and basically returns the formatted url immediately, while respecting custom location and file name normalization.
This is a naive implementation of how we can bypass any checks to gcloud for example We can also avoid even initializing gcloud storage like this.
from django.core.exceptions import SuspiciousOperation
from django.core.files.storage import Storage
from django.utils.encoding import smart_str
from storages.utils import (
clean_name, setting,
safe_join)
class CloudStorage(Storage):
bucket_path = setting('GS_BUCKET_PATH')
file_name_charset = setting('GS_FILE_NAME_CHARSET', 'utf-8')
location = setting('GS_LOCATION', '')
settings = None
@property
def manager(self):
if self._manager is None:
from storages.backends.gcloud import GoogleCloudStorage
self._manager = GoogleCloudStorage(**self.settings)
return self._manager
def __init__(self, **settings):
self.settings = settings
self._manager = None
def _normalize_name(self, name):
try:
return safe_join(self.location, name)
except ValueError:
raise SuspiciousOperation("Attempted access to '%s' denied." %
name)
def _encode_name(self, name):
return smart_str(name, encoding=self.file_name_charset)
def url(self, name):
if self.bucket_path is not None:
name = self._encode_name(self._normalize_name(clean_name(name)))
full_name = self.bucket_path + name
return full_name
return self.manager.url(name)
def _open(self, name, mode='rb'):
return self.manager._open(name, mode)
def _save(self, name, content):
return self.manager._save(name, content)
def delete(self, name):
return self.manager.delete(name)
def exists(self, name):
return self.manager.exists(name)
def listdir(self, name):
return self.manager.listdir(name)
def size(self, name):
return self.manager.size(name)
def get_modified_time(self, name):
return self.manager.get_modified_time(name)
def get_created_time(self, name):
return self.manager.get_created_time(name)
def get_available_name(self, name, max_length=None):
return self.manager.get_available_name(name, max_length)
@jdmueller I do not understand how your solution works, could you explain please?
Looks like you use FileSystemStorage to form urls, but I am not sure why this should work - is not it some different Storage at all?
https://github.com/jdmueller/sorl-thumbnail-jdmueller/commit/0f4d1f787d7f29647965a8d3ff3cad92dccb45f9#diff-e3d22d454c3df40ff35f95407205e56def3713e2dd9351768179f406cd2b2cf1L83
Since my app have not only public, but also private files, I just add some caching for urls.
Solution is not properly tested, but it works and makes endpoints fast.
from django.core.cache import cache
from storages.backends.s3boto3 import S3Boto3Storage
class S3Storage(S3Boto3Storage):
"""Storage where signed URLs are cached."""
def url(self, name, *args):
normalized_name = self._normalize_name(self._clean_name(name))
cached_url = cache.get(normalized_name)
if cached_url is not None:
return cached_url
else:
url = super().url(name, args)
cache.add(normalized_name, url, self.querystring_expire)
return url
@uhbif19 the caching is good solution. However, you want to cache the urls less time that they are valid. Your example code as written can return a url that will expire before it is used.
I typically cache for half the life of the url. If the URLs are valid for 24 hours then cache the link for 12. The actual values depend on your use case.
@uhbif19
Thanks for comment. Yes, I planned this as well as of cache warming.
Why that 12 hours difference would be useful? I thought that it would be enough to add a couple of seconds to compensate the difference between the time link was generated and time it was added to cache.
It depends on your use case on the client side. If you are simply rendering images in the browser it may not matter. However, it you are displaying a table of links for the user to click on. You are creating are hard to debug case, where sometimes the user will be given links that are expired. Or are expired by the time the user clicks on them.
In the extreme case, the server generates the links at midnight (00:00:00). The link expiration and cache are both set to 24 hours. The user goes to page at 23:59:59. By the time, the link is used it will almost certainly be expired.
If you set your cache time-to-live to a number much smaller than the link time to live you will always send valid links.
Hey, we face a similar issue of bad performance when trying to get URLs for a lot of objects at once. After checking what happens, the sentry shows us that we are trying to retrieve an URL for every object. And for every such object, it is going to CloudFront and is making the HEAD requests. That's the case even if we have turned off the querystring_auth parameter. This is strange because according to the version we are using, it shouldn't be making any requests at all and should be just forming the URL. Maybe there are some other under the hood things going on, which I am missing. It would be great if you can point me out where the HTTP HEAD requests might be happening.
But, overall, are there any ideas on how performance for a lot(50+) objects in a single request can be improved? I am looking into the direction of these things:
- https://docs.aws.amazon.com/AmazonCloudFront/latest/DeveloperGuide/private-content-signed-cookies.html
- https://docs.aws.amazon.com/AmazonCloudFront/latest/DeveloperGuide/private-content-creating-signed-url-custom-policy.html
But I am not 100% sure if such solutions are compatible with this library. If someone already encountered such an issue and has tackled it, it would be great if you can share!
Update: Just a quick update from my side – the problem with performance was not because of signing multiple objects. As wodCZ mentioned the signing is happening locally. The problem was because we were doing the whole roundtrip to get the dimensions of an image for each object.
The code causing the requests is here.
Defining AWS_S3_CUSTOM_DOMAIN makes it run through the fast branch. I haven't tried it in combination with AWS_CLOUDFRONT_KEY_ID, but it looks like then the url is signed locally using RSA, which should be faster than making HTTP request for each file.
Edit: More specifically, I suspect this line:
params['Bucket'] = self.bucket.name
which runs this:
@property
def bucket(self):
"""
Get the current bucket. If there is no current bucket object
create it.
"""
if self._bucket is None:
self._bucket = self.connection.Bucket(self.bucket_name)
return self._bucket
and that ends with the request here:
@property
def connection(self):
connection = getattr(self._connections, 'connection', None)
if connection is None:
session = boto3.session.Session()
self._connections.connection = session.resource(
's3',
aws_access_key_id=self.access_key,
aws_secret_access_key=self.secret_key,
aws_session_token=self.security_token,
region_name=self.region_name,
use_ssl=self.use_ssl,
endpoint_url=self.endpoint_url,
config=self.config,
verify=self.verify,
)
return self._connections.connection
Although I'm not 100% sure - the bucket property should be only initialized once 🤔
Edit 2: nevermind, I got lost in the rabbit hole 🤦
@Raduan77 Сan you please explain how you made Sentry capture this?
After checking what happens, the sentry shows us that we are trying to retrieve an URL for every object.
@wodCZ, thanks for pointing it out.
It seems like we are already using AWS_CLOUDFRONT_KEY_ID and AWS_CLOUDFRONT_KEY, and it still performs the requests.
Regarding your comment about bucket – we have AWS_S3_CUSTOM_DOMAIN defined, so that shouldn't be the case, I believe, since as you've mentioned, it is going through the fast route and doesn't need to perform these lines
@uhbif19, we haven't done any specific things. Sentry is tracking every transaction by default in our service, we just followed through the initial setting tutorial provided by a sentry. After that, you can check every transaction on the Performance page. I am adding a screenshot of how it looks.

I noticed today I am getting the same effect. In my case at first I noticed in https://scoutapm.com/ that there are HEAD requests going out for each one of my images in a template:

Interestingly, I also have Sentry installed (but I was only using it for Errors), so I also decided to check its Performance tab and I can also see the HEAD requests. It does show a bit more than @Raduan77 's screenshot, perhaps a newer version has more details. I can see it's calling aws.s3.HeadObject.
I edited the url method of s3boto3.py to add a few prints and I can confirm I have a custom_domain and it's returning the url earlier. So, something else is making the call. I think this rules out the .url method. I am still not sure what's generating the HEAD requests. There's some documentation at boto3 saying HeadObject will be called if filtering buckets but I don't see django-storages doing any of that.
Will try debug this more later.
Okay, maybe storages is doing indirectly through the django's BaseStorage - boto3 docs in Filtering say:
Behind the scenes, the above example will call
ListBuckets,ListObjects, andHeadObjectmany times.
Looking for where Prefix is used in storages, it's in listdir: https://github.com/jschneier/django-storages/blob/cf50a22d76f1ab3294e85c0a753a7c369663b293/storages/backends/s3boto3.py#L483
But storages never call listdir itself, and I can't find exactly where Django itself would call the storages one.
So that's my best guess for now, somehow storages' listdir is being called, and filtering Buckets, which makes boto3 call HeadObject - but I am really having a hard time reproducing any of this as of now. Hopefully I will have more later.
Alright! I have more data. It's not url (as suspected before), it's height (or width) on an image. Check the stacktrace, Django's ._get_image_dimensions ends up calling storages .open, which invokes boto3 and _make_api_call from botocore/client.py is getting called with HEAD:
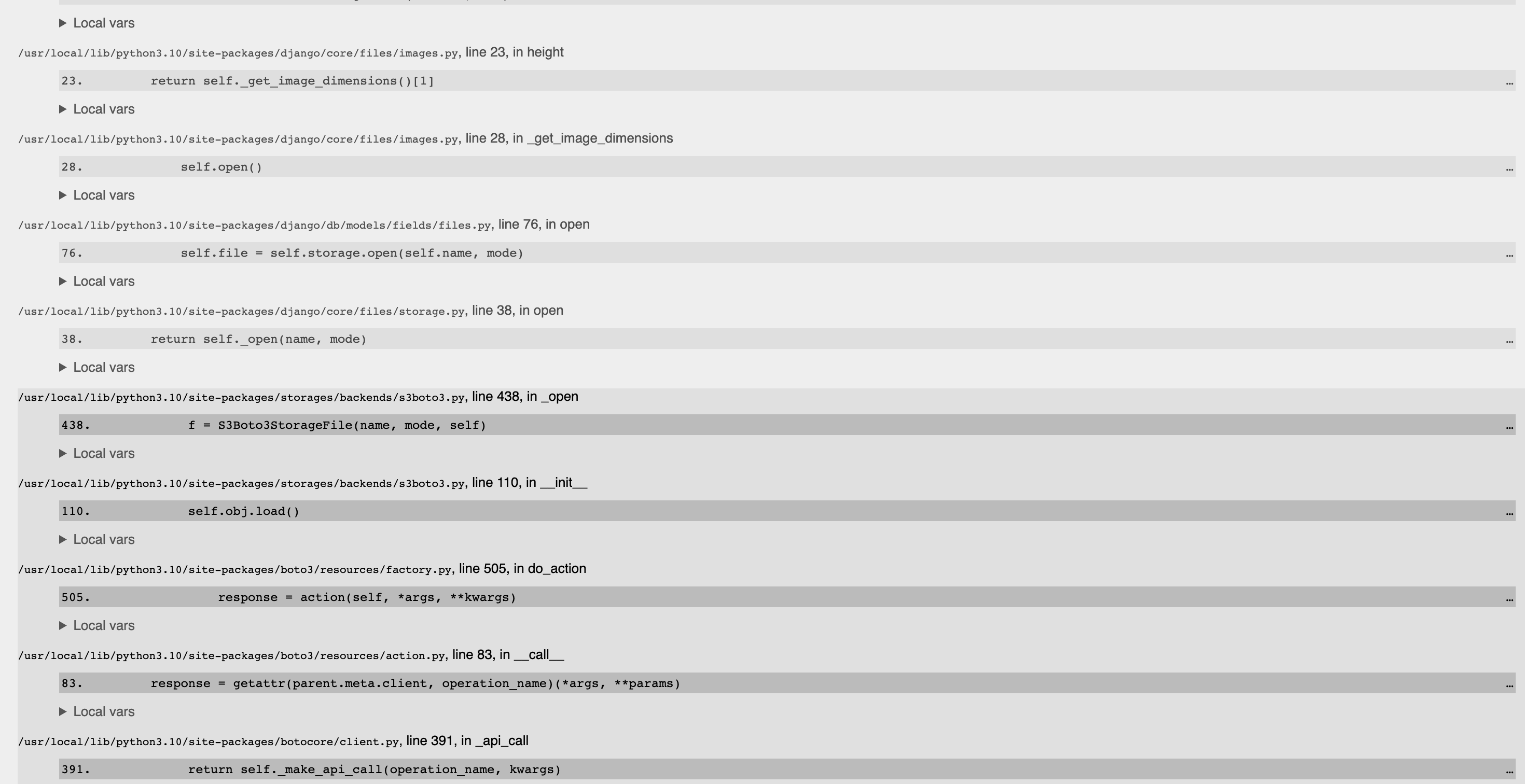
The solution is simple, don't call .height nor .image directly from an ImageField, but use its height_field and width_field and always use that instead - interestingly, I did have those 2 fields, but was mistakenly calling the ImageField methods.
Sorry for so many messages, as I really wanted to fix this. I could feel some of my pages being slow and I couldn't figure out why, once I saw the HEAD requests going out, it led me to this thread and the rabbit hole. My site feels snappy now, a page with 5 images was taking ~2.5 seconds to load, and now ~600ms. Yay!
I'm not sure if this is the same issue, but I'm running into an issue where the ImageField's update_dimension_fields is being called hundreds of times on a single request:

I've tried to avoid calling instance.image.url and instead have opted to call instance.image.name and build the url manually as suggested, but it doesn't seem to be working.
Any ideas if this is related to the same thing?