2019: ELECTRA: Pre-training Text Encoders as Discriminators Rather Than Generators
ELECTRA: Pre-training Text Encoders as Discriminators Rather Than Generators Kevin Clark, Minh-Thang Luong, Quoc V. Le, Christopher D. Manning, ICLR 2020 https://openreview.net/forum?id=r1xMH1BtvB
code: https://github.com/google-research/electra

- 参考
- BERTの解説:#160
- ALBERTの解説: #348
概要
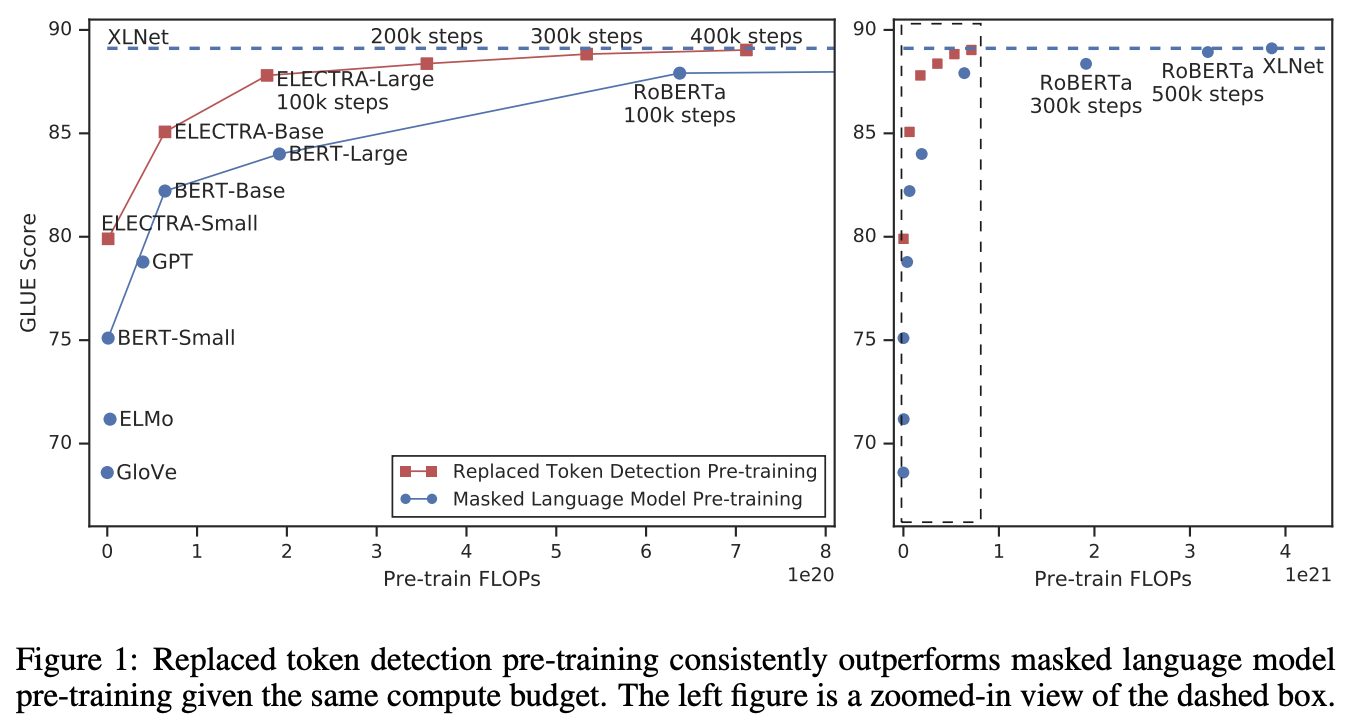
BERTなどで扱われているMasked Language Modeling (MLM)をReplaced Token Detection (RTD)に置き換えたモデル,ELECTRAを提案.RTDでは,生成モデルによって生成された各トークンが,識別モデルによってreplaceされたかどうかの二値判定で事前学習する.MLMでは,入力文に対して少量(15%程度)のマスクされたトークンしか学習できないのに対して,RTDではすべてのトークンを学習に扱うことができるためEffective.このタスクの導入により,ELECTRAと同一サイズモデルのBERTと比較,BERTを圧倒した.また小さいモデルでもELECTRAは特に有効であり,1GPU(V100)で4日鍛えただけのモデルが,30倍のコンピューティングが必要なGPTをGLUEで圧倒.更に大きなモデルでもRoBERTaやXLNetの1/4の計算量で同等の性能を出した.
イントロ
BERTに始まり昨今の事前学習型で採用されているMLMは,入力に対して15%程度しか利用できていない(マスクトークンの予測であるため).そこで本論では,Replaced Token Detection (RTD)を提案.各トークンが前段のモジュールで置き換えたかどうかを判定するため全トークンを学習に寄与させることができる.生成モデルと識別モデルは,GANに影響をうけているが,生成モデルは敵対的に動くわけではない(後述).我々のアプローチをELECTRA: "Efficiently Learning an Encoder that Classified Token Replacements Accurately"と呼ぶ.様々な実験を行い,ELECTRAの優れたモデル効率性及びスケールの際の性能の良さを示していく.
手法
アーキテクチャはFig 2.生成器Gと識別器Dのニューラルネットから構成される.それぞれ時系列データを,時系列のベクトルに変換する.(本論ではTransformerを採用) 生成器Gはトークン列を生成するのであれば何でも良いが,小さいMLMモデルを採用した.GはMASKトークンの箇所のトークンを,入力文全体から予測する(通常のMLM).Dでは,各トークンがオリジナルのトークンか,交換されたトークン化を予測する.MLMが正しいトークンを復元生成する可能性もあるので,その場合はオリジナルトークン,というラベルが振られる(つまり,間違ったトークンかどうか,という形になる).
学習は単純で,Gは最尤推定,Dはクロスエントロピー.GANと構成が似ているが,Gを敵対的に学習する要素はない.テキスト分野では敵対学習はまだあまりうまくいかない.またRLを使ったGも実験したが,下記手法よりうまくいかなかった(Appendix F)

事前学習が終わり,fine-tuningのフェーズに入ったら,生成器Gは捨て,識別器Dのみをダウンストリームタスクでfine-tuningする.
実験
セットアップ
評価セットにはGLUEを利用.ほとんどの実験には,BERTで使ったWikipediaやBooksCorpusを事前学習データとして同様にELECTRAに使った.XLNetとの比較のためにXLNetで使った更に大きな事前学習データを使ったモデルも用意.
我々のモデルアーキテクチャとほとんどのハイパラはBERTと同じ.GLUEのfine-tuning時には,ELECTRAのトップレイヤにシンプルな線形識別器を追加するだけ.SQuADに対しては,XLNetと同じモジュールを追加(BERTのそれより洗練されている,SQuAD 2.0からstart, endが保証されていない?データもあるため,回答方法に工夫). また評価セットが少量であったことから,事前学習モデルを固定し,random seedを10回変えてfine-tuningしたスコアの平均を示す.また特に指定がなければdev setでの結果を報告(test setは未公開で分散の少ない結果を見せたかったから?).より詳しくはAppendixへ.
モデル拡張
いくつかの拡張をモデルに適用する.またモデルサイズは,特に記載がなければBERT-Baseと同じ.
重み共有
GとDで埋め込み(トークン埋め込みとPosition埋め込み)を共有し,Gは小さいモデル(レイヤーサイズ小)ときに効率的であることを発見.Gの入力及び出力トークンの埋め込みはBERTに同じにし,埋め込み層をGの隠れ層へプロジェクションする線形変換レイヤーを追加.GとDの同一サイズにした際のGLUEは84.4,埋め込み共通で84.3,共通なしで83.6.よって埋め込み共通の84.3が効率的(84.4より低いが,Gが小さい分,モデルサイズを小さくできる).以降の実験では埋め込み共通の設定を採用
より小さいG
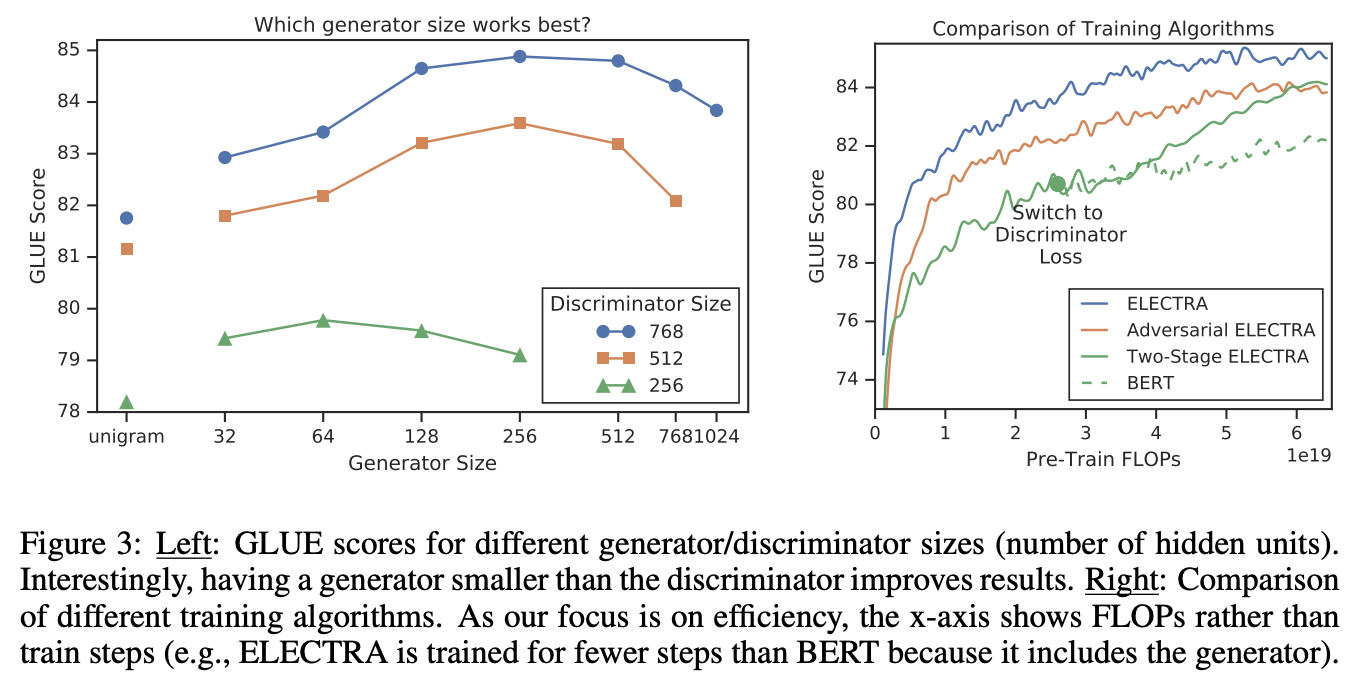
GとDが同一サイズの場合,MLMと比べて2倍の時間がかかることになる.そのためにGはできるだけ小さくしたい.そこでGのレイヤーサイズ(隠れ層?)を小さくし,他のハイパラは固定.また極端に小さいGとして,コーパスのトークン頻度からunigramを生成するモデルも実験.Fig 3の左側にGのサイズ別の性能の比較を示す.ステップ数は500kで固定(時間制約でなくステップ数制約なので,計算量が軽いモデルには不利)
- Dに比べて1/4 - 1/2のサイズのGがベスト.DとGのパワーバランスがこのへんで丁度いいと思われる(Gは強くなりがちなのでハンデありっぽくする)
- 以降の実験では,ここでベストのGのサイズを採用
学習アルゴリズム
学習アルゴリズムに関しても他の学習アルゴと比較.1つはTwo-Stage学習でMLMを鍛えたあとに,その重みでDを初期化し(つまりモデルサイズは共通にせざる負えない),Dを学習する.もう1つはRLを使って敵対的に学習する.結果はFig 3の右側.
- 学習の効率性をみるために,ステップ数でなく,FLOPs(FLOPSでなくFLOPs,つまり時間あたりの計算量でなく,これまでの計算量の合計)で性能を比較
- 比較する2つの手法はBERTよりよいが,それでも序盤に説明したシンプルな構成がもっとも優れている.
小さいモデルでの実験
シングルGPUでも学習できるモデルELECTRA-smallについて実験する.BERT-Baseのハイパラからはじめ,系列長を短くし(512->128),バッチサイズを小さくし(256->128),隠れ層のサイズを小さくし(768->256),埋め込み層のサイズを小さくした(768->128).公平な比較のために,同じパラメタ設定でBERT-smallも学習.またELMoやGPTも比較対象に追加.結果はTable 1
- ELECTRA-smallは,同一サイズのBERT-Smallよりも5ptほど高い.
- サイズがかなり大きいGPTよりも性能が良い
- たった6時間学習しただけでもBERT-smallと同じぐらい
- ELECTRA-BaseのスコアはBERT-Large(84.0)よりも高い

大きなモデルでの実験
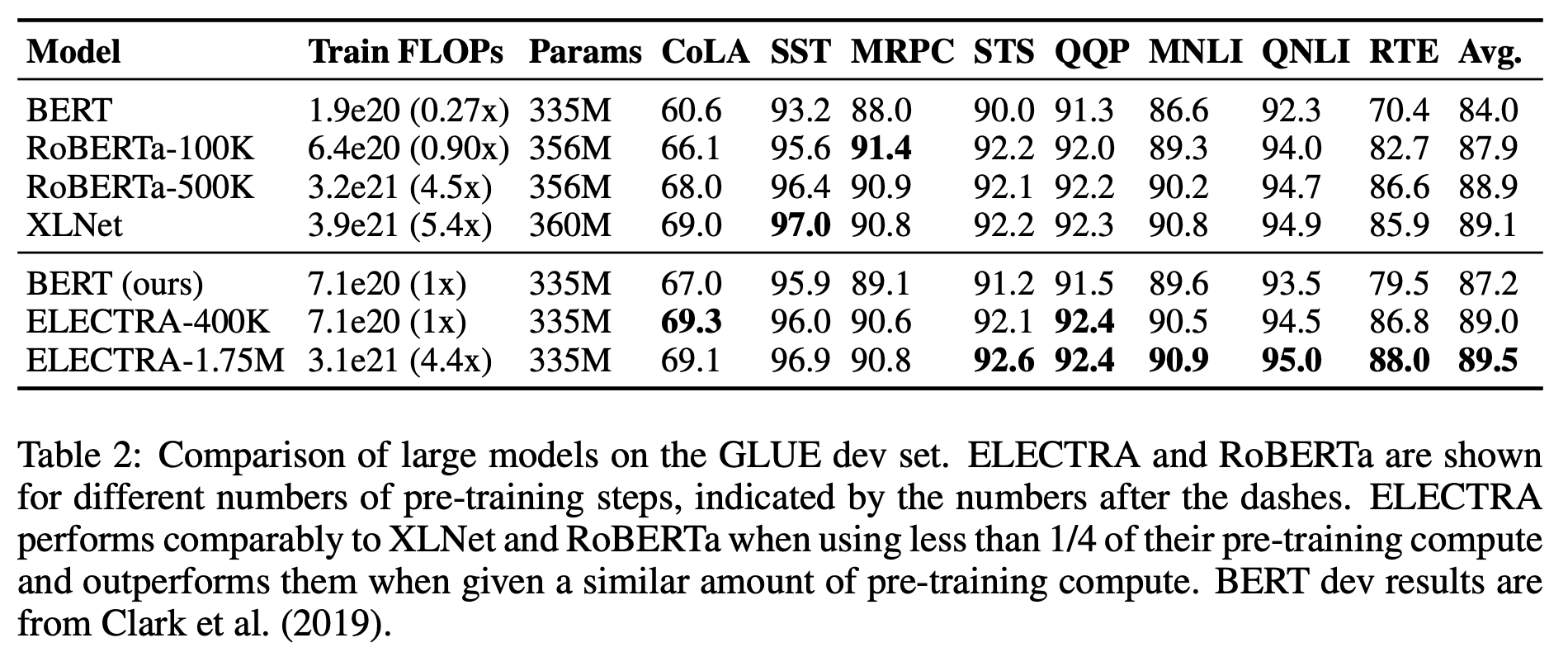
今度は大きな規模で学習してみる.モデルサイズはBERT-Largeと同じで,長い時間鍛える
- ELECTRA-400K: 400Kステップで学習.RoBERTaの事前学習の焼く1/4
- ELECTRA-1.75M: 1.75Mステップで学習.RoBERTaとだいたい同じ
- バッチサイズは2048で,XLNetの大きなデータを利用.(XLNetとRoBERTaの利用データは違うので厳格な比較ではない)
この結果をTable 2(dev-set).
- ELECTRA-400KはRoBERTaやXLNetと同等の性能(でも計算量は約1/4!)なので,大規模設定でもELECTRAは強い
- 更に1.75Mステップまで学習するとSOTA.それでも計算量はまだ少ない
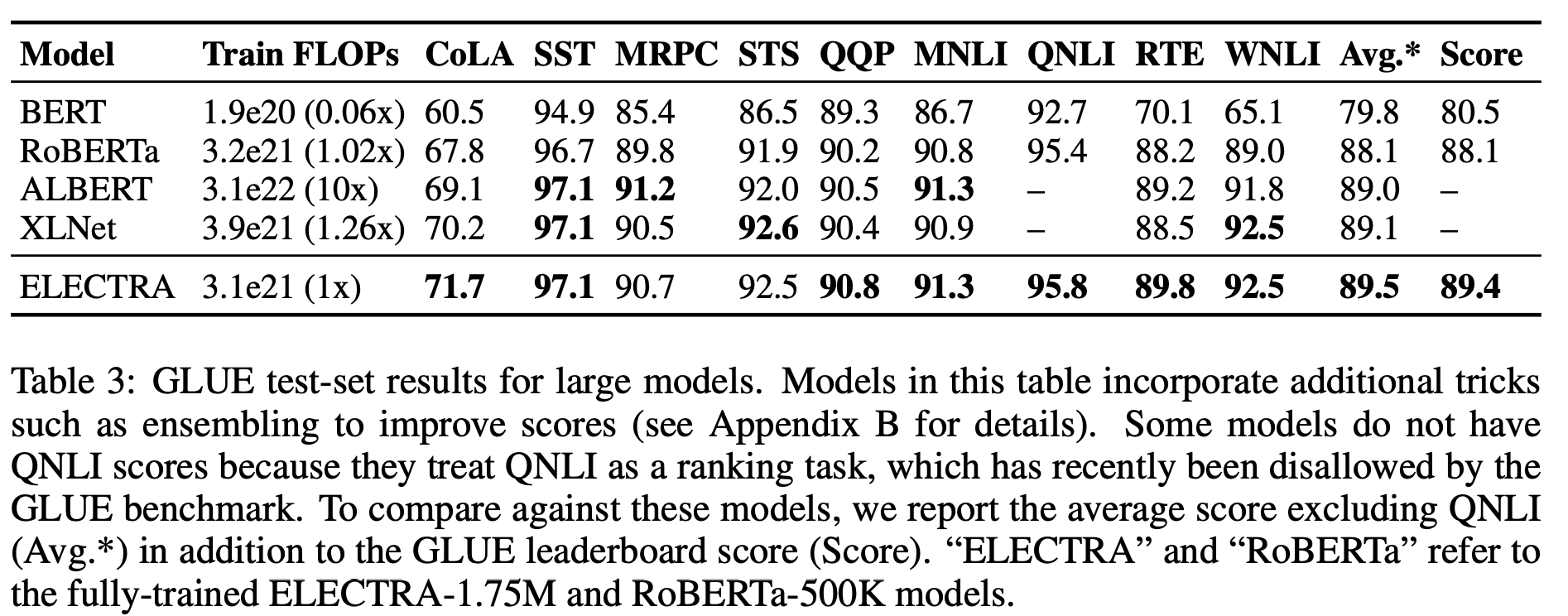
ちなみにtest setでもちゃんと実験している.(ただ利用データが異なるので厳密の比較ではないことに注意)
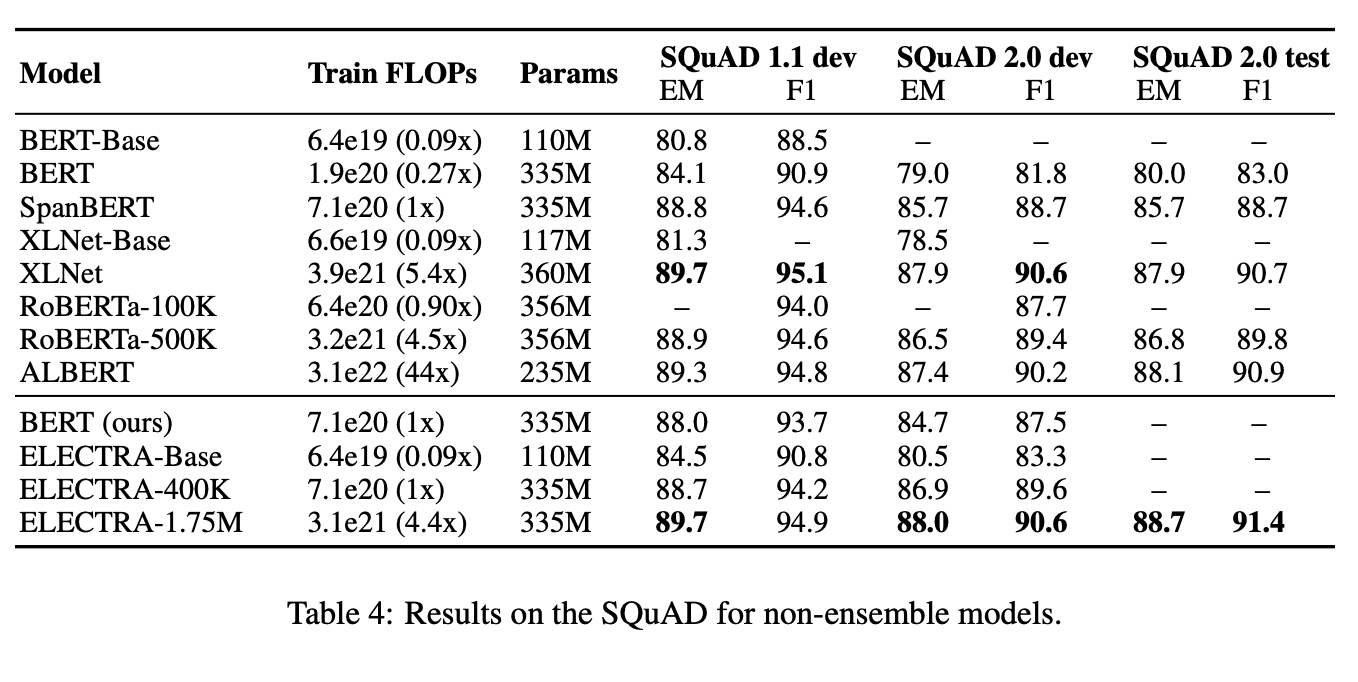
次にSQuADの結果をTable 4
- GLUE同様に同一計算量においては,ELECTRAは優れている.
- ELECTRA-400KでRoBERTa-100kやBERTを超えている.
- ELECTRA-400KとRoBERTa-500Kは同等スコアだが,ELECTRAは1/4以下の計算量で良い
- 1.75Mと長い時間で学習すれば,SOTAの性能.
効率性の分析
MLMは効率が悪いと主張しているので,これを確かめるための実験.
- ELECTRA 15%
ELECTRAと同じモデルだが,Dの損失をマスクトークン(文中15%)のみに適用 - Replace MLM
MLMと同じだが,MASKシンボルを使わずに,マスクトークンには,Gが生成したトークンを利用する.事前学習中にMASKシンボル(推論時には現れない)を使う影響の調査 - All-Tokens MLM:
Replace MLMに加えて,入力のすべてのトークンを生成.
結果はTable 5に
- ELECTRA 15%と比べて,ELECTRAは高いので,MLMの非効率性の指摘は正しそう
- Replace MLMはBERTよりわずかに良い.MASKシンボル利用はあまりよくないのかも.ちなみにBERTはすでにこのpre-train/fine-tuningの不一致の改善のトリックとして,ランダムトークンへの置き換えを行っている.(ただこれも十分でないという結果だ)
- All-Tokens MLMはELECTRAに最も近い性能.これはトークンの利用効率性及びfine-tuning時のミスマッチ軽減(MASKシンボル利用)が影響していると言えそう

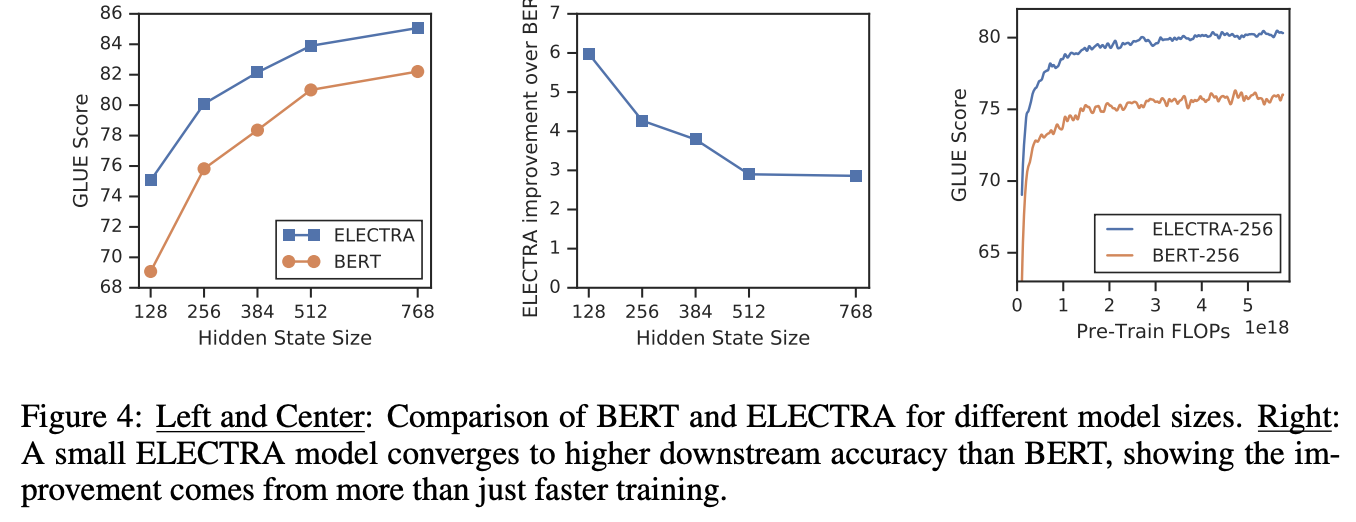
All-Tokens MLMに対するELECTRAの改善は,早い学習こと以外にも起因すると考えられる.それを調べるためにBERTとELECTRAを様々なモデルサイズで比較(Fig 4左と真ん中).モデルサイズが小さいときほどELECTRAの方が広いマージンで優れている.また小さいモデルは完全に収束しているのも確認できる(Fig 4 右).これらの結果よりBERTよりもELECTRAはパラメタ効率が高いと言えそう.ただパラメタ効率性に関する分析はもっと必要そうだ
関連研究
略
結論
Masked Language Modeling (MLM)に置き換わるReplaced Token Detection (RTD)を提案.計算効率が高く,ダウンストリームタスクでも高い性能を示した.比較的小さいモデルにおいても高い性能を示すことができた
コメント
- RTDは添削に近く,正解っぽい事例から間違いを正すのは人でも難しいので,このタスクの納得性は高い
- モデルの公平な比較などわかりやすい上に参考になる
- 理論的な分析はないので今後の期待
Podcastでも解説しました. https://anchor.fm/lnlp-ninja/episodes/ep50-ICLR-ELECTRA-Pre-training-Text-Encoders-as-Discriminators-Rather-Than-Generators-ebgu2f