arXivNotes
 arXivNotes copied to clipboard
arXivNotes copied to clipboard
2019: FreeLB: Enhanced Adversarial Training for Language Understanding
FreeLB: Enhanced Adversarial Training for Language Understanding Chen Zhu, Yu Cheng, Zhe Gan, Siqi Sun, Tom Goldstein, Jingjing Liu, ICLR 2020
- https://arxiv.org/abs/1909.11764
- openreview (8-8-8)
概要
FreeLB (Free Large-Batch)という埋め込み空間に摂動(perturbation)を加えて行う敵対学習手法の提案.この手法の評価のため,Transformerベースのモデル(BERTとRoBERTa)の単語空間に対して摂動を与え,言語理解及びcommonsense reasoningタスクを解いた.fine-tuning時にこの摂動を与えることで,GLUEベンチマークにおいて,BERT-based及びRoBERTa-largeモデルを改善.またARC-Easy及びARC-Challenge(科学系のクイズデータセット)でSoTA.
イントロ
敵対学習(Adversarial Training)はロバストなニューラルネットを作るための手法である.学習中に,敵対的な摂動がサンプルに混入させることで,モデルにこのようなノイズに強くするための手法である. 本論では敵対学習の汎化性能に着目する.CVのエリアではCIFAR-10などのタスクで敵対学習で性能をブーストできている. 本論では我々はSoTAなモデル(Transformerベース)を敵対学習で改善できることを示す.FreeLBという手法を提案し,単語埋め込みに対して敵対摂動を加え,入力サンプル周辺の敵対損失を最小化する.この手法ではfree学習戦略(Shafahi, 2019; Zhang 2019)によって,PGD敵対学習(Madry 2018, #349 )と比べても追加コストなしに,異なるノルム制約下において,多様な敵対サンプルによってバッチサイズを拡張する.これにより多様な敵対学習大きなモデルに対しても適用できる. 実験では他の敵対学習と比べても,FreeLBがベストだということを示す.またablation studyなどでも評価
関連研究
敵対学習
敵対サンプルに対してニューラルネットの頑健性を向上させるため,多くのdefense戦略とモデルが提案されている.中でもMadry 2018のPGD-basedの敵対学習がもっとも敵対事例に対して効率的なものとして捉えられている.なぜならこれはobfuscated gradient問題を回避できるためだ // obfuscated gradientは勾配マスクなど敵対摂動に対するDefense策だが,ICLA 2018のベストペーパーにより,これらの手法は多くが攻撃が成功してしまったらしい.ただPGD手法はこの問題を回避できる,といっていると解釈した
Qin 2019は,PGDにおける摂動計算時の試行回数Kが小さいときに問題があることを見つけている.また,PGDの計算は通常の学習よりもコストが高い.このコスト問題を軽減させるべく,Shafahi (2019)はfree敵対学習アルゴリズムを提案し,モデルパラメタ及び敵対摂動の両方を同時に更新させることに成功した.またZhang 2019でも似たような方法を取り,最初のレイヤーにおける敵対更新のほとんどを制御することで,forward及びbackward propagationの数を効率的に減らした
Text Adversaries
敵対学習は,もともとはVisionのエリアで提案されたが,テキストドメインにおいても多く提案されている.
- 文書に対してdistractingな文を挿入することで誤分類を誘発する (Jia & Liang 2017)
- 入力データを潜在空間に飛ばし,GANを使ってオリジナルのインスタンスに近い敵対データを探すのに利用(Zhao 2018)
- 機械翻訳を使って文中の単語を人工的にあるいは自然ににノイズをいれる(Belinkov & Bisk, 2018)
- 逆翻訳を使ってパラフレーズを使ったもの(Iyyer 2018)
我々の手法は,彼らと違い,実際の敵対事例を作成することではないが,敵対学習のメリットを言語理解タスクにおいて享受する.
また我々は言語モデルにおいて敵対データでロバスト性を獲得するための最初の研究ではない.下記のような研究が既に存在している.
- Virtual Adversarial Training.データxの周辺で予測分布p(y∣x)が摂動を加えた分布p(y|x+摂動)の距離が小さくなるように(なめらかになるようにする)(Miyato, 2017, 2019)
- 文字・単語の入れ替え(Ebrahimi 2018)
- NLPモデルのデバッグツールとしての有用性を示す(Ribeiro 2018)
- 敵対事例が機械翻訳を改善できることを発見(Cheng 2019)
これらの研究はシンプルなモデルあるいはテキスト生成タスクで行われている.我々は,より深く大きなTransformerベースのモデルを利用し,どのように効率的に敵対攻撃を行うか,パフォーマンスを改善するか,を明らかにする
言語理解のための敵対学習
本論では,BERTとRoBERTAの埋め込み空間のロバスト性を上げることで,性能を改善する.これはfine-tuning時に行う.これはvirtual adversarial exmplesで実現する.言語において敵対事例を作るのは容易ではないが,我々の目的は敵対事例を作ることでなく敵対学習によるロバスト性の確保である.我々はnorm-boundedな勾配ベースの敵対摂動を利用して埋め込み空間をロバストにする.
ここでいう埋め込み空間はBPE埋め込みをconcatしたものを対象にし,他(position encodingとか)はそのまま.入力サブワードをZ=[z1,z2,...,zn]とし,埋め込みマトリックスをVとする.そのため入力は,X=VZとなり,言語モデル(エンコーダー)の出力はy=fθ(X)となる.このXに対して摂動δを足すことでy'=fθ(x+δ)となる.我々は,δは小さくし,モデルの摂動を入れた後の予測は変わらないことを想定する.これはMiyato (2017)のVirtual Adversarial Trainingと同じであるが,ここではXの正規化は必要としない.
敵対学習のためのPGD
標準的な敵対学習はnorm ballの範囲にあるいかなる摂動δにおける最大のリスクを最小化するためのパラメタセットθ*を学習する.Dはデータ分布,yはラベル,Lは損失関数,ノルムはフロベニウスのノルムを利用.
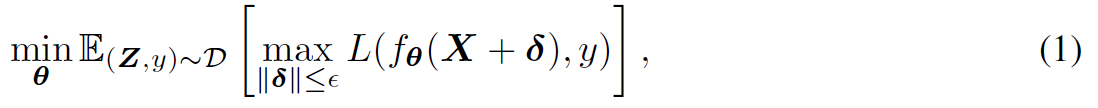
Madry (2018)は,鞍点問題を,外部の最小化にはSGDを,内部の最大化にはPGDを利用して解けることを示した.PGDでは摂動δは下記のように更新される.損失Lに対して摂動δで偏微分し,それをαステップ分動かす(ここまでは普通のSGD).PGDでは更にそこから摂動δをε-ballの範囲内で近いところにprojectionしたものを採用する.
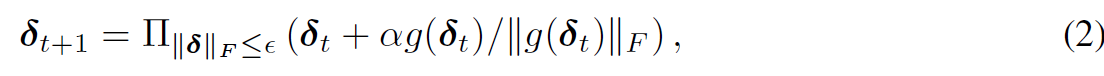
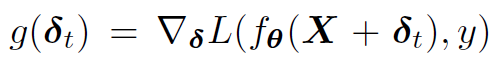
- PGDのわかりやすい図
 高いロバスト性の獲得には,学習中に計算コストの高いマルチステップの敵対事例が必要となる.K-step PGD (K-PGD)は,一般のSGD更新が1回のforward-backward計算なのに対して,K回の計算が必要となる.そのためが実行時間が増加する上,SOTAな大きなモデルでは非常に時間がかかりすぎる
高いロバスト性の獲得には,学習中に計算コストの高いマルチステップの敵対事例が必要となる.K-step PGD (K-PGD)は,一般のSGD更新が1回のforward-backward計算なのに対して,K回の計算が必要となる.そのためが実行時間が増加する上,SOTAな大きなモデルでは非常に時間がかかりすぎる
Large-Batch Adversarial Training for Free
内側のPGDの上昇ステップにおいて,そのパラメタの勾配は,入力の勾配を計算するときにほぼコスト無しで得られる.この観点から,FreeATとYOPOは,敵対学習を加速するために提案された.それらは,通常のクリーンデータに対するSGDの学習時と同じあるいはわずかに多いforward-backwardの計算を行うことで,通常のPGD学習と同等のロバスト性と汎化性能を獲得した.
-
FreeAT (baseline)
- 各摂動のK回の上昇ステップと一緒に,1回のパラメタ降下ステップを取る
- 結果として,最適な摂動δがモデルパラメタθに強く相関している時,δtは,L(fθt (X+δ), y)を最大化するときの準最適となる.なぜなら,δt-1 -> δtの上昇ステップは,下記勾配をベースにするため
-
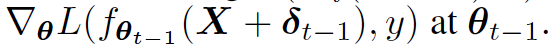
-
YOPO (baseline)
- 各上昇ステップのパラメタの勾配を蓄積させ,内側のK回の上昇ステップの後,1回だけパラメタを更新する.
- 各バックプロップの後,ネットワークの最初の隠れ層の勾配を定数として取り,この勾配の定数と最初のネットワークのヤコビアンの積を使って,複数回の追加更新を行う
-
FreeLB (提案手法),see Algorithm 1

- 複数のPGDイテレーションにより,敵対事例を作る (Line 6-12)
- 同時に,各イテレーションでは,freeの∇θLを蓄積する (Line 7)
- 蓄積勾配を使って,1回でモデルのパラメタθを更新(Line 13)
- 目的関数は下記のようになる.
-
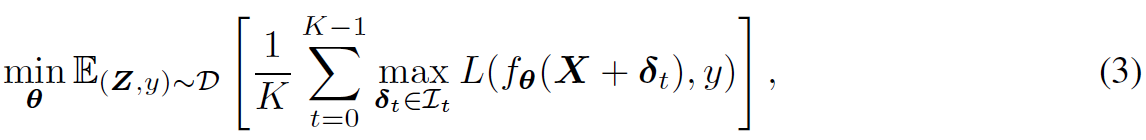
- オリジナルのXに対して,K回の計算をするので,仮想的にK倍のバッチサイズになる(FreeLBのLB: Large-Batchの所以)
-
- オリジナルのPGDベースの手法(式1)と比べると,各学習事例の周辺ポイントに対して,mini-max問題を解いていることになる
- 更にFreeLBでは,各上昇ステップはほぼ追加コストなし
- 複数のPGDイテレーションにより,敵対事例を作る (Line 6-12)
敵対学習にドロップアウト
一般に敵対学習はドロップアウトとは一緒に使われてはいないが,RoBERTaではfinetuning時にドロップアウトを行っている.ドロップアウトを利用すると,Algorithm 1の各上昇ステップは,異なるネットワークでδを最適化することになる.具体的にはベルヌーイ分布からdrawする各エントリmiとなる,ドロップアウトマスクmとなる.FreeATの分析と似たように,δt-1 -> δtへの上昇ステップは,下記がベースとなる.つまり,θとδが高い相関関係にあれば,δtは,L(f_θ(m_t) (X + δ), y)の準最適となる.それ故,θ(m)はドロップアウトマスクmにおける効率的なパラメタとなる
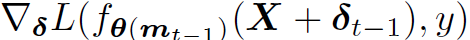
よりわかりやすい方法は,各ステップで同じmを使うことである.我々はあらゆるネットワークにもドロップアウトを適用し,θの目的関数は,ドロップアウトマスクによって決定される異なるネットワーク化でのロス最小化となる.これは期待ロスのモンテカルロ推定によって成り立ち,目的関数は下記のようになる.1-sampleモンテカルロであれば,f_θ(m0)となる
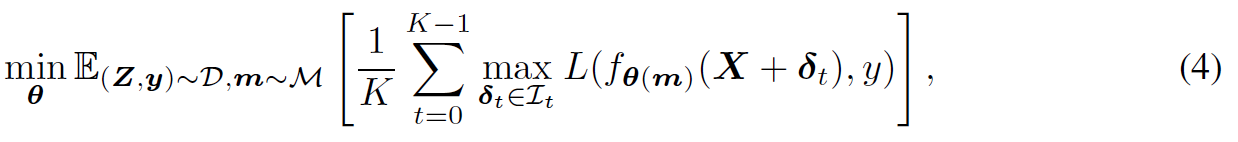
実験
GLUE (9この言語理解タスクセット), ARC(科学系の質問の選択問題), CommonsenseQA(人のcommonsenseを使う問題)で実験.
実験結果
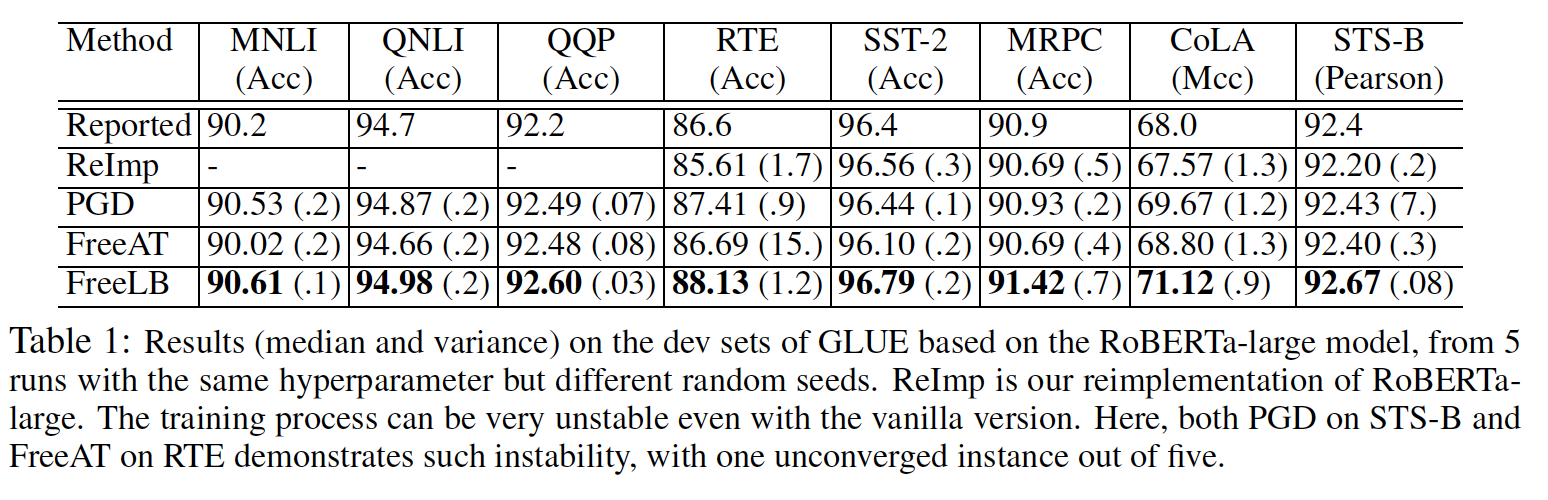
- GLUEの結果はTable 1.ステップサイズα及びステップ数mは,PGD, FreeAT, FreeLBで同じ
- FreeLBはこの2ベースラインよりも一貫して高い
- YOPOとの比較は4.3章
-
またGLUEの評価サーバーに送った結果をTable 2.BERTベースで1.1,RoBERTaで0.3の改善

-
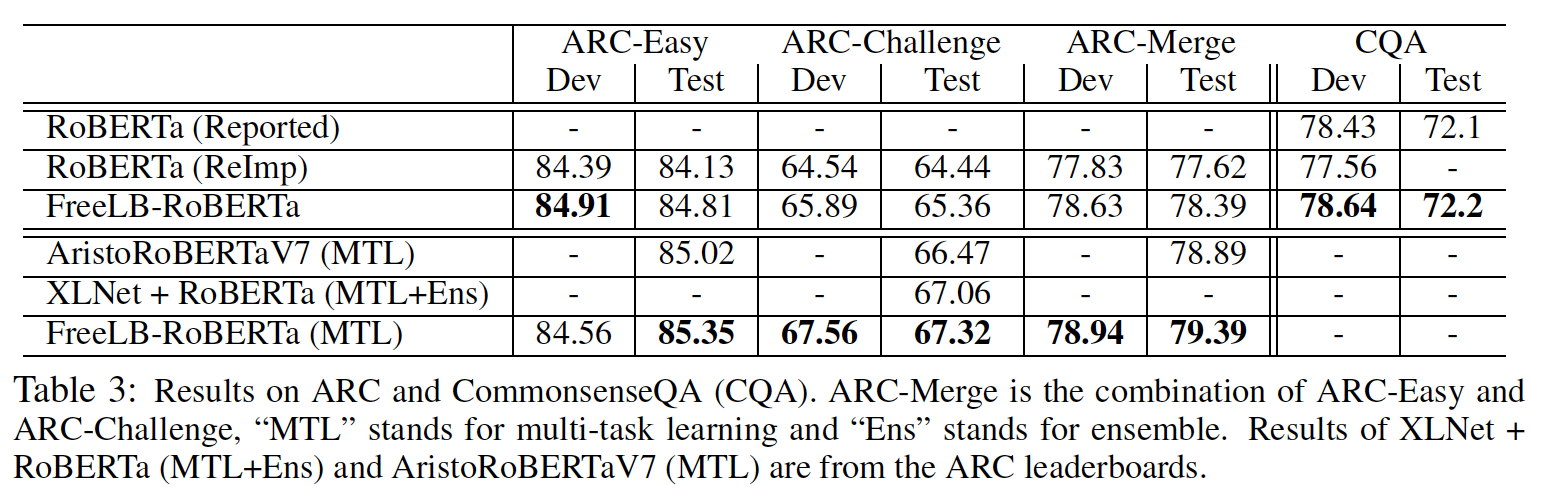
Table 3にARC及びCommonsenseQAの結果.
-
ここでも性能をブースト出来ている.他QAデータセットを使ってマルチタスク学習もすると更に上る.
Ablation studyと分析
-
ドロップアウトマスクの再利用の重要性に関して
- Table 4の2,3列目がマスクなし,あり
- マスクの再利用で3タスクで性能を1,2%ほど向上できている.

-
ロバスト性の比較
-
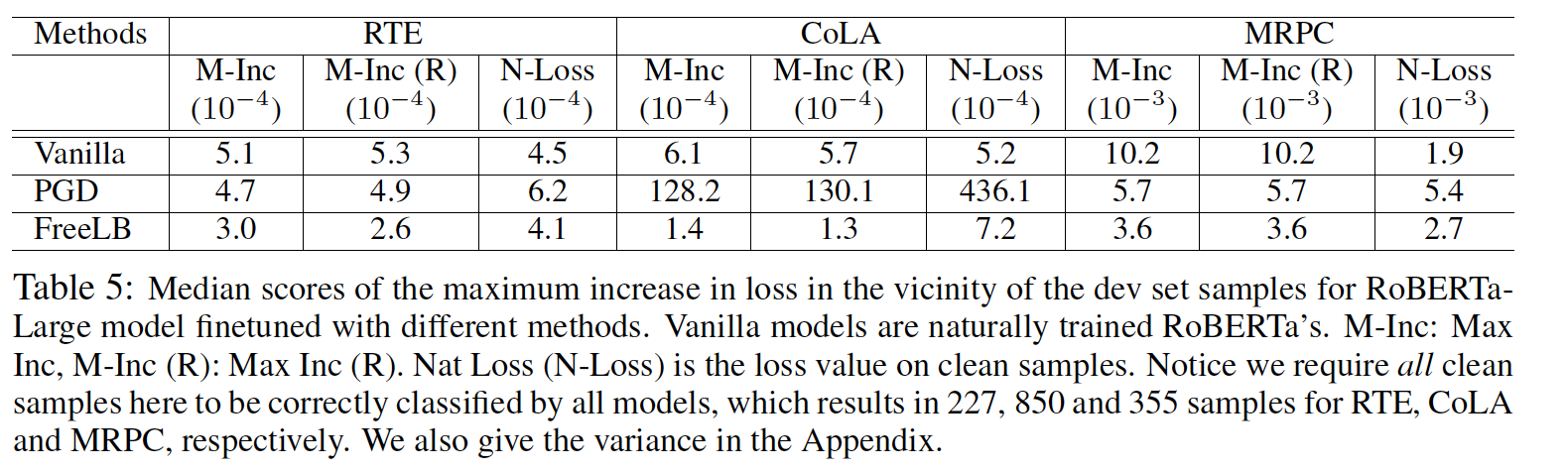
Table 5は,下記で定義される各サンプル周辺のロスの最大増加の比較を示す.これは,モデルの埋め込み空間における頑健性及びinvarianceを表す
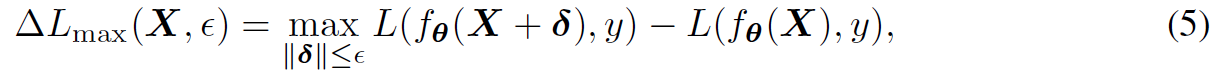
-
// Max Inc (R)などの意味がよくわからないため,解釈できませんでした
-
-
YOPOとの比較
- Table 4
- FreeLBがYOPOよりも良い結果に
- // YOPO自体をあまり良くわかっておらず,考察がよくわかりませんでした
結論
言語理解を改善するためのFreeLBという敵対学習のアプローチを提案.勾配を使って単語埋め込み空間に摂動をいれることでvirtualな敵対事例を作成.Transformerベースの大きなモデルに対して様々な言語理解データセットでモデルを改善することに成功.
参考
Podcastでも解説しました https://anchor.fm/lnlp-ninja/episodes/ep46-FreeLB-Enhanced-Adversarial-Training-for-Language-Understanding-e9uauc