arXivNotes
 arXivNotes copied to clipboard
arXivNotes copied to clipboard
2019: Do Neural Dialog Systems Use the Conversation History Effectively? An Empirical Study
Do Neural Dialog Systems Use the Conversation History Effectively? An Empirical Study Chinnadhurai Sankar, Sandeep Subramanian, Christopher Pal, Sarath Chandar, Yoshua Bengio To appear at ACL 2019 https://arxiv.org/abs/1906.01603 code: https://github.com/chinnadhurai/ParlAI/
概要
ニューラルベースのNLGは広く人気だが,対話履歴をちゃんと理解しているのか,利用しているのか,という点で疑問視の声が上がっている.本論では,対話履歴を人工的に改変することでモデルの対話履歴に対するセンシティビティを研究した.10の異なる改変を4つの対話コーパスに対して行った.結果,rnn,transformerベースのseq2se2モデルは,多くの改変に対してあまり敏感でないことがわかった.

イントロ
ニューラルNLGでは対話履歴の理解能力の不足さから,”Thank you"のようなdullレスポンスを生成しがちという問題がある.またこのような問題に対する研究もほぼされていない. 本論では,この研究のため対話履歴を人工的に改変し,rnn,transformerベースの2つの人気のニューラルNLGモデルへの影響を調査.今回実験では,1.rnn, transformerベースのモデルは多くの今回の改変に対して鈍感であること,2.履歴のランダムシャッフルや,語彙順序入れ替えなどの激しい改変に対しても両モデルは鈍感であった,ということが判明.またrnnモデルはtransformerよりも敏感であり,対話履歴のダイナミクスをよりよくモデルできているかもしれない,ということもわかった.
関連研究
LSTMベースの言語モデルがどのようにコンテキストを利用しているか,という調査がある(Khandelwal 2018).この研究では,モデルが直近150ワードの改変にしか敏感でないということを見せた.一方で,翻訳モデルのような条件付き言語モデルにおいては,人工的な改変,自然なノイズ,双方に対して悪い影響を受けることがわかっている(Belinkov, 2017).またニューラルモデルの表現がどのような情報を学習,含んでいるか,といった研究もある. またNLIにおいて2文の関係性を求めるタスクで,片方の文だけで問題が解けたり(Gururangan 2018),機会読解では質問の全体やコンテキスト文書の最終文しか見なかったり(Kaushik 2018),エージェントがNavigationやWorldを観察しなくても質問に回答できたり(Anand 2018)する問題がある.
また系列モデルにおいて,Tran(2018)はRNNが階層構造のモデルを得意とすることを見つけ,一方でTang(2018)らはtransformerやcnnのようなフィードフォワード型のモデルは,長期コンテキストのモデル化がRNNと比べてよくないと指摘.しかしTransformerは語義の明確化に優れている.我々はアーキテクチャとアテンション機構の利用の選択により,対話システムの対話履歴の利用度に関する分析を行った
実験セットアップ
ニューラル言語生成モデルを考えるため,入力x1, x2, .. xnを与えて,y1, y2, ... ymを生成するタスクになる.これをrnnとtransformerベースのseq2seqでモデルかした.我々の着眼点は,人工的に対話履歴x1, x2..を改変することで,学習した確率分布(モデルの出力)がどのようにあ振る舞うのかを調査することにある.そのためのメトリクスとして,今回の改変設定を行うことによるトークンあたりのperplexityの変化をみる.もしpplの増加が少なければ,x1..xnの改変はモデルにとって有益でないと言える(改変手法のリストは3.2で).また全てのモデルは対話履歴の改変なしで学習し,テスト時のみ履歴を改変する
データセット
bAbI dialog,Persona Chat, DailyDialog, MutualFriendsを利用
改変方法
-
発話レベルの改変. Shuf: 対話履歴の発話シーケンスの順序をシャッフル Rev: 対話履歴の発話順序を逆にする(単語レベルでなく,文レベルで)
-
単語レベルの改変 word-shuffle: 発話内の単語をシャッフル reverse: 発話内の単語順序を逆にする word-drop: 発話内の単語の30%を一様にドロップ noun-drop: 全ての名詞をドロップ verb-drop: 全ての動詞をドロップ
モデル
rnnとtransformerベースの2モデルを利用.実験はFacebookのParlAIフレームワークを利用.今回のモデルは各データセットに対してSOTAではないが,competitiveであり,ベースラインとしては十分である.
結果と議論
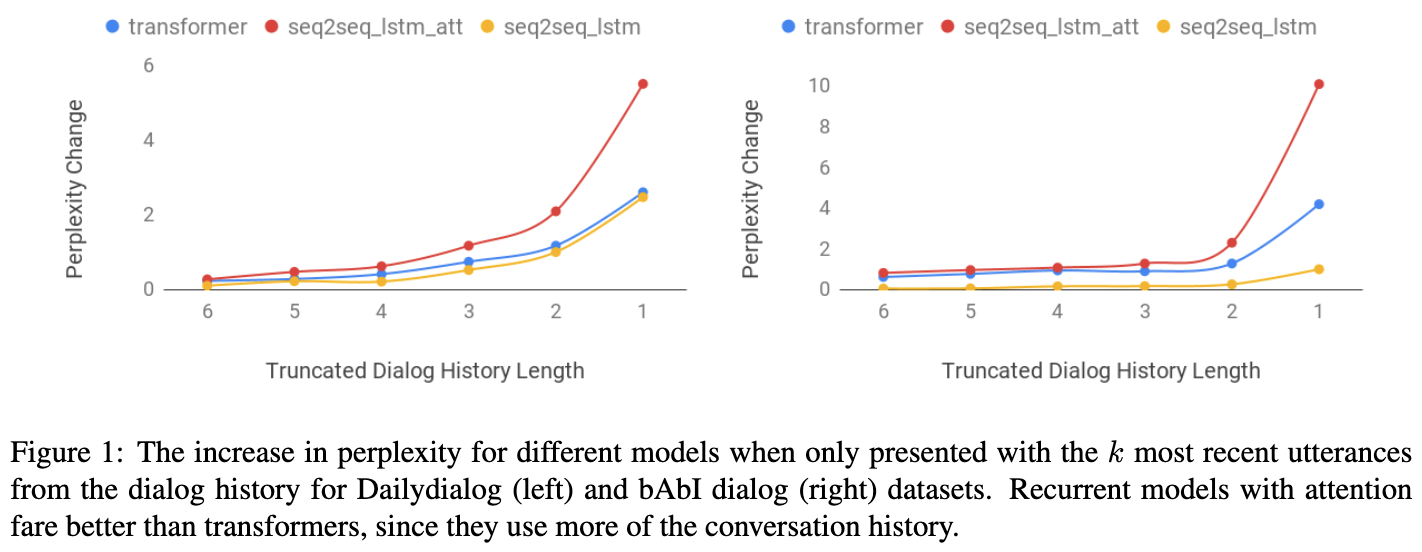
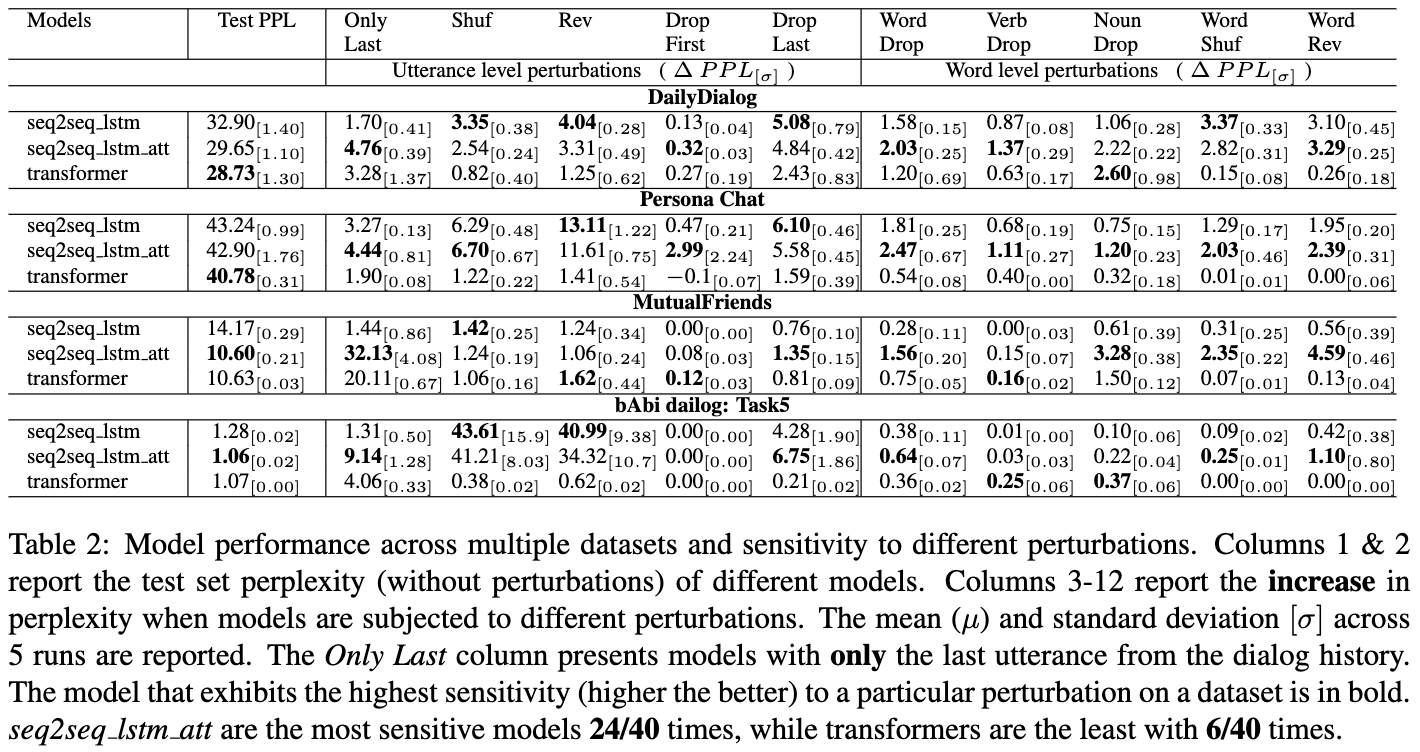
結果はFig 1とTable 2.Fig 1は,対話履歴から直近k発話を利用した時のpplの変化.
観察した点は下記の通り
- 多くのケースでモデルはわずかなpplの変化しかしない.これは対話履歴を全て利用していることができていないことを意味しそう
- Transformerは語順に鈍感である,これはbowライクな表現学習をしていることを意味しそう
- 最終発話だけが利用できる状況において,アテンション機構のモデル(seq2seq_lstm_attとtransformer)は,ppl上昇からわかる通り,対話の冒頭の情報をvanilla seq2seqよりも利用していることがわかる
- transformerはより早く収束し,テスト時に低いpplを出せているが,対話履歴における対話のダイナミクスを捉えていないようで,rnnモデルよりも対話構造を破壊するような改変に対して鈍感であるように見える
結論
本研究では,人工的に対話履歴を改変することでニューラル生成モデルがどのような影響を受けるのか調査.実験では,rnn, transformer双方のモデルにおいて,対話履歴の改変で大きく影響を受けないことを発見(対話履歴をちゃんと使っていない).またrnnは若干ではあるがtransformerよりもコンテキストをより利用していることをpplの変化から発見.
コメント
- 🤔応答生成時に対話履歴が全て必要とは限らないので,応答生成にクリティカルな履歴部分に対する改変効果を見ないとダメではないだろうか
- 🤔対話履歴の利用具合のチェックのために,ppl以外のメトリクスも見たかった
- 特定の問題設定が破綻しているようなことを指摘する,関連研究がよくまとまっていて良い
- 効率的な対話履歴利用の研究に一役買いそうではある
Poscastでも解説しました. https://anchor.fm/lnlp-ninja/episodes/ep34-Do-Neural-Dialog-Systems-Use-the-Conversation-History-Effectively-e4958g