mlp-mixer
 mlp-mixer copied to clipboard
mlp-mixer copied to clipboard
PyTorch implementation of MLP-Mixer: An all-MLP Architecture for Vision
MLP Mixer
PyTorch implementation of MLP-Mixer: An all-MLP Architecture for Vision.
Quickstart
Clone this repository.
git clone https://github.com/jaketae/mlp-mixer.git
Navigate to the cloned directory. You can start using the model via
>>> from mlp_mixer import MLPMixer
>>> model = MLPMixer()
By default, the model comes with the following parameters:
MLPMixer(
image_size=256,
patch_size=16,
in_channels=3,
num_features=128,
expansion_factor=2,
num_layers=8,
num_classes=10,
dropout=0.5,
)
Summary
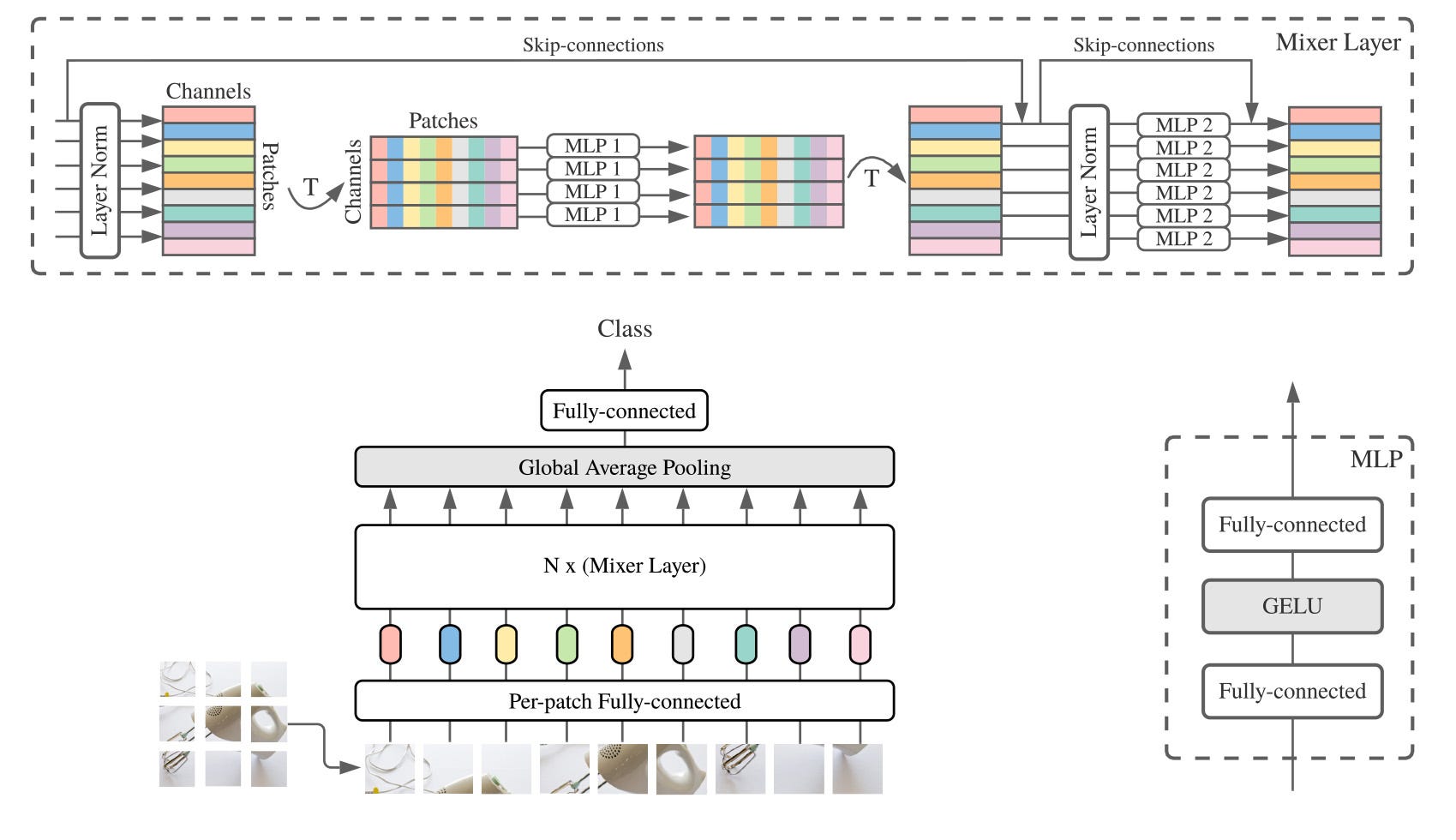
Convolutional Neural Networks (CNNs) and transformers are two mainstream model architectures currently dominating computer vision and natural language processing. The authors of the paper, however, empirically show that neither convolution nor self-attenion are necessary; in fact, muti-layered perceptrons (MLPs) can also serve as a strong baseline. The authors present MLP-Mixer, an all-MLP mode architecture, that contains two types of layers: a token-mixing layer and a channel-mixing layer. Each of the layers "mix" per-location and per-feature information in the input. MLP-Mixer performs comparably to other state-of-the-art models, such as ViT or EfficientNet.