Demonstrate converting a few files to use Parendown
Please don't actually merge this commit. I doubt Parendown works well with DrRacket and the other tools and expectations of the Racket community, so I expect this kind of change to inhibit future maintenance of Rebellion. (In practice, I use Parendown only in codebases for which I anticipate maintaining a Cene port, since it makes Racket resemble Cene.)
Even if you don't consider that to be a problem, I haven't even refactored the whole codebase, just a few files.
The reason I'm putting this pull request out there is because you were mentioning it might be a good way to discuss Parendown in the context of an actual codebase.
The place Parendown is most essential, continuation-passing style (or monadic style), isn't much of a factor in the Rebellion codebase. It's also pretty rare for Rebellion to have cascades of early-exit branches since it does its error-checking using Racket contracts instead. As a result, if you look through the changes, you'll notice a lot of them are rather insignificant (mainly of stylistic value, if anything), and even the more significant ones aren't game-changers.
Some of the most significant changes come from places that use cond and struct accessors in Rebellion. These turn into rather more concise pattern-matching branches in the (Parendown + Lathe Comforts) style, and these cascades of branches give Parendown a chance to shine.
Anyway, whenever we get to talking about Parendown again, I hope this achieves the goal of providing us with some tangible examples. :)
Going over the diff again, I think the good parts are:
-
The parts that replace
condwith pattern-matching. -
Maybe also the parts that make use of the new functions
dissect-recordanddissect-octet-stream. This shows that writing a few functions in CPS can be just about as convenient as using multiple-value return ordestructuring-bind.
It's possible these are both more of a matter of the advantages of pattern-matching than the advantages of Parendown. :-p
* I think you're right that the main improvement is replacing `cond` clauses with pattern matching, especially nested `cond`s. I suspect you're right that that doesn't have much to do with Parendown specifically and is more about the utility of pattern matching in general. So #180 is probably a more valuable improvement than I assumed.
I wonder if we should try out a variation of this PR that uses a lot of match-define instead of dissect and match instead of mat/expect, at least to have something to compare with.
* This notation seems to encourage continuation passing style.... a _lot_. To the point where it takes over the codebase and makes your APIs for others assume CPS. Rebellion having CPS-oriented APIs is a nonstarter: under no circumstances should Rebellion _require_ all clients use something like Parendown just to avoid the ever-creeping lambda nesting of CPS.
I don't see a place where my changes have required Rebellion clients to use CPS. The only new thing I exported was record-ref-maybe, which doesn't have much to do with CPS except perhaps in the way it leads to the use of the maybe monad.
As an internal convenience, I defined dissect-record and dissect-octet-stream. I expect dissect-record would never be exported. If dissect-octet-stream were ever exported, I figure that one would be a match transformer (not a CPS function) and would have a #:padding keyword to better align with the style of the constructor.
Do you even see utilities in Lathe Comforts that require clients to use CPS? There may be a few, but just looking at the ones I used in this PR, maybe-if is the only one that might count; it takes a thunk that could be thought of as a continuation. Even then, maybe-if is mostly an instance of preferring a function definition over a macro definition. Passing a success thunk to maybe-if is very comparable to passing a failure thunk to Racket's hash-ref.
* I'm having a really hard time telling where identifiers are bound. The `fn` syntax, the looping macros, and the `expect` form seem to rely heavily on varargs-style interfaces and avoid any grouping. Plus the parendown notation means that `fn` is often used far off to the right of a line but introduces a binding for the lines below.
Detecting where variables are bound is always an issue with new syntaxes. Lathe Comforts does break with some Racket conventions, but I think they're worth breaking from.
I'm not sure how the expect form fits into what you're saying, since that one takes precisely four subforms (the subject, the pattern, the else branch, and the then branch).
The fn, w-, and w-loop forms use fewer parens primarily because, for consistency of indentation style, I'd like to avoid using parens in places that aren't prefix operations. In Racket's (lambda (a b c) (a b c)), the second (a b c) is a function call where b and c are on equal footing and (a ...) is what's operating on them, but the first (a b c) is an argument list where a, b, and c are on equal footing and (...) is what's operating on them. This means the structure of the code can be meaningfully different even if the appearance stays the same.
Making Racket more consistent about using parens for prefix operations would take a lot of work, but for the purposes of a new language at least, I might prefer (fn (args a b) ...), (fn a #/fn b ...), or even a length-specialized (fn2 a b ..) over (fn (a b) ...). I'm a little conflicted between those options, largely because I would miss the terseness of (fn (a b) ...) compared to the others. Thankfully, as long as I can write (fn a b ...), I find it preferable to all the others.
I think the fn form's paren reduction also serves to make Parendown slightly less of a downgrade compared to sugars like fancy-app (+ _ 1), curly-fn #{+ % 1}, and compose-app (a .. b .. c), where raw character count seems to be a driving factor in the design. With Parendown, we can write those as (fn _ #/+ _ 1) and (fn x #/a #/b #/c x) instead. If you prefer to do slightly more keyboarding, you can write (λ (_) #/+ _ 1) and (λ (x) #/a #/b #/c x) instead of fn, and personally I think this amounts to the same thing. But if raw character count wasn't a concern, I suspect these libraries would just export s-expression macros with explicit, easily hygienic binding occurrences like (λapp (_) + _ 1) and (comp (..) a .. b .. c) rather than bothering with #%app, reader macros, code-walking, or syntax-parameterize. I suspsect fn's lack of parens may be compelling for... whatever reason it is that those other libraries are so relentlessly terse. As the author of compose-app, maybe you can help me understand what the actual reasons are. :)
(As a user of Arc and Groovy, the syntaxes I've really thought about as a basis for comparison are Arc's [+ _ 1] and a:b:c, Groovy's { it + 1 }. I'm just picking out the Racket libraries fancy-app, curly-fn, and compose-app because they resemble these.)
As for syntaxes that put the binding occurrences on the right... Yeah, I found this odd at first. The name can serve as a descriptive title that sets the stage for what its associated expression is doing, but it can only do that if it's on the left. It's often more terse than the expression it's bound to, so putting it on the left tends to cut down on line breaks too. It was only after writing a lot of CPS code in JS that I came to be resigned to putting variable bindings on the right sometimes.
There are rare places in Racket, like match and cond..=>, which do put a binding occurrence after the expression its binding comes from. I think the reason for this is that a pattern-matching form has multiple branches which have different bindings, and there isn't a good place "to the right" of all of those patterns at once unless we wanna put it all the way at the end. :)
You'll notice that in mat, expect, and dissect, I deliberately chose to put the subject of the match on the left and the pattern on the right. In fact, dissect is little more than an abbreviated specialization of match.
(mat lst (cons x xs)
(on-success x xs)
(on-failure))
(expect lst (cons x xs)
(on-failure)
(on-success x xs))
(dissect lst (cons x xs)
(on-success x xs))
(match lst #/ (cons x xs)
(on-success x xs))
I made these particular choices because even though mat and expect forms have only two branches (and dissect only has one), I still find them useful for values that have more than one nontrivial variation. In that case I evaluate the expression once and bind it to a variable (such as lst here), and so the subject expression fits on one line and serves as a descriptive title for the binding pattern, rather than the other way around. Funnily enough, this means I prefer putting pattern-matched expressions on the left for precisely the same reasons I prefer putting let variables on the left.
* This doesn't seem to reduce the total amount of punctuation characters in the code, since each `()` character pair gets replaced by a `#/`. This isn't a criticism, just an observation.
Yeah, raw character verbosity is rarely a factor to me (outside of talking about things like fancy-app, curly-fn, and compose-app where other people seem to care about it). Cutting down on characters can be a good way to keep code on one screen, particularly when it helps avoid some word-wrapping line breaks, but that only goes so far and leads to a greater risk of name collisions, which I also care about.
Another far more potent factor that leads to line breaks is indentation, which affects whole sections of code at once. Parendown reduces the depth of (regular-strength) parens (by replacing many of them with weak open parens), and this reduces the need for indentation, which in turn helps avoid line breaks, which in turn helps more code fit on one screen.
At any rate, the # part of #/ is only there to make this seamless with the Racket reader, which already gives a different meaning to /. If you think making a #lang that interferes with Racket's existing meaning for / would be a better demo, I could do that. :)
* The parendown notation doesn't seem to play nicely with keyword arguments. It makes it hard to tell where I can insert new keyword args and where I can't. Keyword args are supposed to be order-independent, but a use of `#\` in the arg above implicitly captures the args below.
Do you mean here in particular?
(reducer-map into-list #:range #/fn strs
(immutable-string-join strs sep
#:before-first before-first
#:before-last before-last
#:after-last after-last))
It sounds like you're talking about a hypothetical case where you'd like to add a #:domain argument to this reducer-map call but that'd like to insert that on the second line, after strs but before (immutable-string ...).
I think it could help to consider this alternative situation:
(for/list ([strs (in-list strs-entries)])
(immutable-string-join strs sep
#:before-first before-first
#:before-last before-last
#:after-last after-last))
There are certain options you can add to this for/list call, but you can only add #:when and #:unless in the for-clause position, and you can only add #:break and #:final as part of the body. If you want to add #:when to the body, that might not even make sense. (Even if we might come up with a way that it does make sense, that would be a solution in search of a problem.)
Likewise, when maintaining a (reducer-map ... #:range #/fn elems ...) operation, it doesn't necessarily make sense to add #:domain to the body. If you want to add #:domain, add it before #:range.
That said, as soon as a reducer-map call specified both the #:domain and #:range options, I would likely stop using a weak open paren there. Writing two similar arguments side by side with similar notation is often more valuable than scrimping on every single indentation level possible.
(It might take me a while to respond to all the rest of your comments, as you can see from what a wall of text this became. XD )
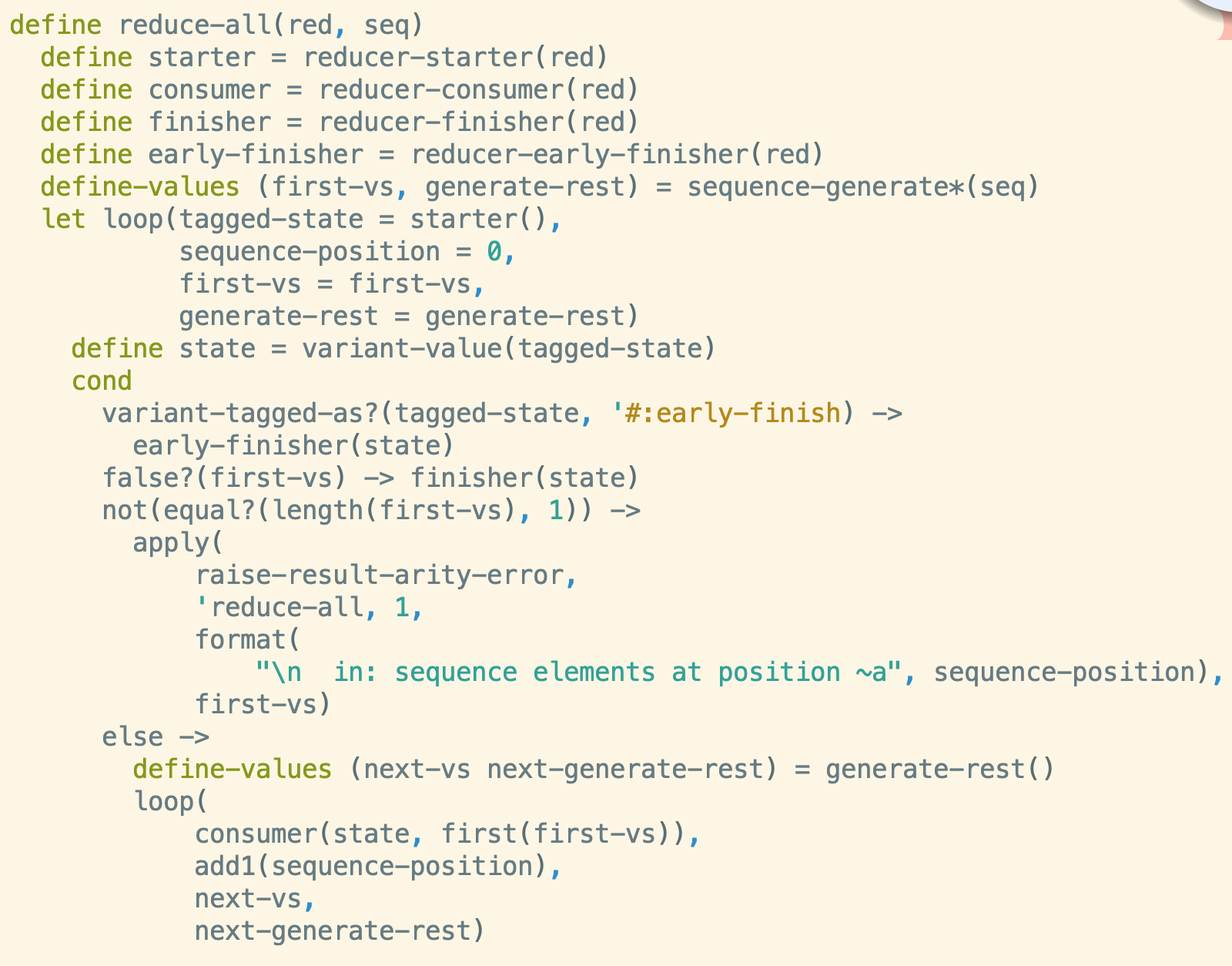
It will take me a while to fully respond, but as a start I wanted to clarify what I mean when I say that I'm having a hard time telling where identifiers are bound. I took the original code for reduce-all and highlighted the binding sites in red and, when present, their assigned expressions in green.

See how there's a very regular pattern? Left-hand side is binding site, right hand side is bound expression, and the two together are grouped by parens into a single clause. When there is no expression, it's usually a header of bindings like a function name and its arguments. The parendown mat, expect, and fn forms seem to scatter the binding sites horizontally and I can't rely on this spine-of-definition-clauses pattern recognition anymore.
Just for kicks I converted reduce-all to a hypothetical algebraic notation (but without infix ops and without using dots for method calls)
I've responded to your first wave of comments... with much longer comments. I hope this isn't too unmanageable a hydra of discussions lol.
I'm probably going to take a break from responding for now.
I took the original code for
reduce-alland highlighted the binding sites in red and, when present, their assigned expressions in green.
I like that visualization. :) I oughta respond with some visualizations too. Did you do that highlighting manually somehow?
See how there's a very regular pattern? Left-hand side is binding site, right hand side is bound expression, and the two together are grouped by parens into a single clause. When there is no expression, it's usually a header of bindings like a function name and its arguments. The parendown
mat,expect, andfnforms seem to scatter the binding sites horizontally and I can't rely on this spine-of-definition-clauses pattern recognition anymore.
Yeah, CPS tends to force things to be on the right because of the lambdas, and I think pattern-matching actually turns the usability criteria upside down. (See "Funnily enough, this means I prefer putting pattern-matched expressions on the left for precisely the same reasons I prefer putting let variables on the left.")
In this code, since you aren't using CPS, almost all the bindings-on-the-right are for pattern-matching, so I think it really is better this way. Even if I did have a general-purpose sugar for putting variables on the left in CPS (which is essentially what Haskell's monadic do notation is), I don't think I'd use it in any of this code.
(Edit: Changed bold to italics.)
Did you do that highlighting manually somehow?
I used the pict/code library, specifically the code macro and make-code-transformer. This script:
#lang racket/base
(require (for-syntax racket/base
syntax/parse)
pict
pict/code)
(define (highlight-single-line-code pict color opacity)
(define w (pict-width pict))
(define h (* (pict-height pict) 7/8))
(define highlighting
(cellophane (filled-ellipse w h #:draw-border? #f #:color color) opacity))
(cc-superimpose highlighting pict))
(define (highlight-binding pict)
(highlight-single-line-code pict "red" 1/2))
(define (highlight-expression pict)
(highlight-single-line-code pict "green" 3/4))
(define-syntax b:
(make-code-transformer
(syntax-parser [(_ id:id) #'(highlight-binding (code id))])))
(define-syntax e:
(make-code-transformer
(syntax-parser [(_ expr:expr) #'(highlight-expression (code expr))])))
(define-syntax b::
(make-code-transformer
(syntax-parser [(_ id:id ...+) #'(code ((b: id) ...))])))
(parameterize ([get-current-code-font-size (λ () 18)])
(code
#'(define (b:: reduce-all red seq)
(define (b: starter) (e: (reducer-starter red)))
(define (b: consumer) (e: (reducer-consumer red)))
(define (b: starter) (e: (reducer-starter red)))
(define (b: consumer) (e: (reducer-consumer red)))
...)))
...produces this output:

* I think you're right that the main improvement is replacing `cond` clauses with pattern matching, especially nested `cond`s. I suspect you're right that that doesn't have much to do with Parendown specifically and is more about the utility of pattern matching in general. So #180 is probably a more valuable improvement than I assumed.I wonder if we should try out a variation of this PR that uses a lot of
match-defineinstead ofdissectandmatchinstead ofmat/expect, at least to have something to compare with.
Very delayed follow-up to this: Rebellion has a lot more support for pattern matching now. Tuple types, record types, and wrapper types can all be pattern matched automatically. Variants can also be pattern matched.
Is it all right if I close this one up? I think we've had our conversation about it. :)