audiomentations
 audiomentations copied to clipboard
audiomentations copied to clipboard
transformations with sample rate bug
Hi! In current implementation after resample transformation the current sample rate could be changed and not given to the future state of composition pipeline. Thus, such code may lead to unexpected behaviour:
sr = 48000
new_sr = 24000
augment = Compose([
Resample(min_sample_rate=new_sr, max_sample_rate=new_sr, p=1),
Resample(min_sample_rate=new_sr, max_sample_rate=new_sr, p=1)
])
samples = # some wav data #
augmented_samples = augment(samples, sr) # should return original wav with sr=24000, but returns stretched
IPython.display.Audio(data=augmented_samples, rate=new_sr) # speed up
i.e. final sample rate reduced twice in the example above.
There are also some transformation that uses sample rate, thus, this problem is crucial for them.
I can suggest solve this problem using some condition in several transformation classes constructor arguments. By this we can return sample rate with samples and parse it in Compose, or return only samples by default.
Or use decorators.
I can see where this is coming from. However, I usually think of the Resample as a form of data augmentation that slows down or speeds up the audio, and that you assume that the sample rate of the output remains unchanged.
Is there a realistic scenario where you would want to have two Resample transforms in a Compose?
Maybe the best fix here is improved documentation? Or show a warning if a Compose contains more than one Resample?
Thank you for your response!
Not only Resample transform requires actual sample rate of input, but other layers too. Thus, expected behavior for all pipelines in my opinion requires the ability for this layer and many others being commutative with each other. For example, these lines of code show us some unexpected behaviour:
sr = 48000
new_sr = 24000
y = ... # np.array of some length
# define transforms
resampler = Resample(min_sample_rate=new_sr, max_sample_rate=new_sr, p=1.)
resampler.randomize_parameters(y, sr)
resampler.freeze_parameters()
masker = FrequencyMask(min_frequency_band=.5, max_frequency_band=.5, p=1.)
masker.randomize_parameters(y, sr)
masker.freeze_parameters()
resample_mask = Compose([
resampler,
masker,
])
mask_resample = Compose([
masker,
resampler,
])
# Plot mel spectrogram with custom defined plot function
plot_mel_from_wav(data=y, sr=sr, title="source")
plot_mel_from_wav(data=resample_mask(y, sr), sr=new_sr, title="resample + mask")
plot_mel_from_wav(data=mask_resample(y, sr), sr=new_sr, title="mask + resample")
These two transformation shows us different outputs, but obviously we expect to nullify some frequencies independently with resampling. Here is the mel spectrograms of above transformation of example audio located in demo/ms_adpcm.wav:
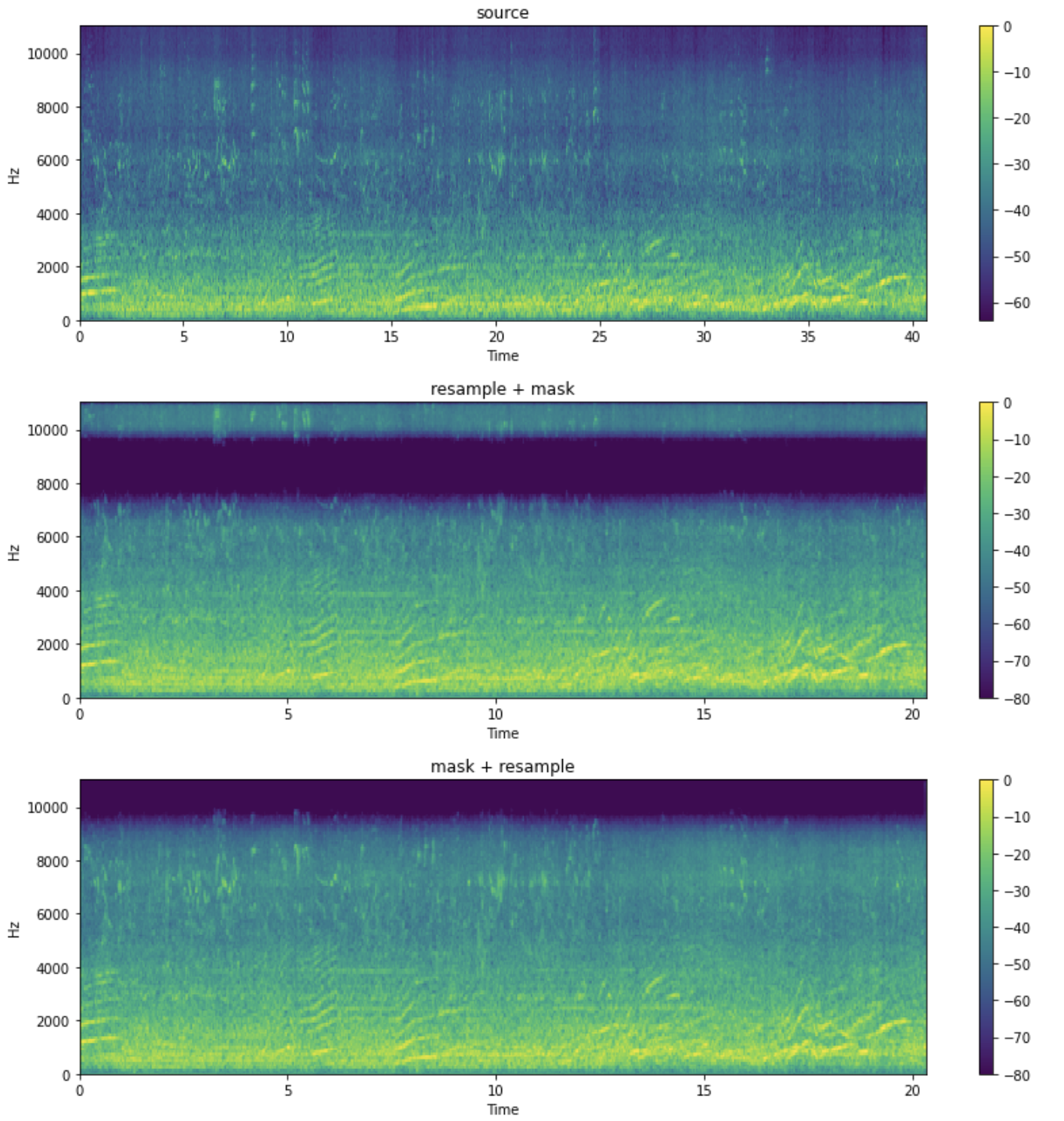
On the other hand, expected behaviour is:
resampler = Resample(min_sample_rate=new_sr, max_sample_rate=new_sr, p=1.)
resampler.randomize_parameters(y, sr)
resampler.freeze_parameters()
masker = FrequencyMask(min_frequency_band=.3, max_frequency_band=.3, p=1.)
masker.parameters = {
'should_apply': True,
'bandwidth': 4000,
'freq_start': 6000
}
masker.freeze_parameters()
# plot the results
plot_mel_from_wav(data=resampler(masker(y, sr), sr), sr=new_sr, title="resample + mask")
plot_mel_from_wav(data=masker(resampler(y, sr), new_sr), sr=new_sr, title="mask + resample")
And the results are quite the same:

The way I see it, there are mainly two use cases for Resample:
- As a form of data augmentation. In this case, think of it as an alternative to TimeStretch that not only stretches the audio in time, but also in pitch. Think that the output has the same sample rate as the input. In this case, it doesn't need to return the sample rate, because we assume that the output sample rate is the same as the input sample rate.
- For resampling audio to a specific sample rate to make it compatible with some function, model or device that expects the audio to have a particular sample rate.
I would argue that audiomentations focuses more on 1) than 2), but I can appreciate that some people use it in both ways.
I can see how Resample wouldn't do what you expect if you have it as a first step in the Compose. However, it would work as expected when it is the last step of Compose.
If you want to resample your audio before you put it through your audio augmentation pipeline, perhaps it's better to do the resampling as a separate step, before you give the resampled audio to Compose? I often do any needed resampling in the call that loads my audio file (I pass the sample rate that I expect).
I'll think about this issue and figure something out.
Also, according to your comment, placing Resample at the end of composition does a great solution, but makes overall pipeline slower, because of processing more data in steps before resample.
And for separate step solution it makes some inconvenience to use pipeline and resampling separately.
Perhaps it's a good idea to rename "Resample" to "Speed" or something, like in lhotse: https://github.com/lhotse-speech/lhotse/pull/124/files#diff-e72b73f9bc90713740d6ad04858a53af438d8f15c313241b0a43397f78879ad2R124
That way, the intended main purpose becomes more clear
Actually, we could have both Speed and Resample. The latter could pass on the sample rate if it's inside a Compose, while the former doesn't do that.