mlem
 mlem copied to clipboard
mlem copied to clipboard
Index of dataframes becomes a "feature" persisted by mlem.save
Consider the following:
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
from mlem.api import save
X, y = load_iris(return_X_y=True, as_frame=True)
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.2, shuffle=True, random_state=42
)
X_train.to_pickle("./data/X_train.pkl")
y_train.to_pickle("./data/y_train.pkl")
rf = RandomForestClassifier(n_jobs=2, random_state=42,)
rf.fit(X_train, y_train)
save(
rf, "rf", sample_data=X_train, description="Random Forest Classifier",
)
In this case, the resulting metadata of the model treats the index column as one of the features:
- name: data
type_:
columns:
- ''
- sepal length (cm)
- sepal width (cm)
- petal length (cm)
- petal width (cm)
dtypes:
- int64
- float64
- float64
- float64
- float64
index_cols:
- ''
type: dataframe
This is confusing and also leads to practical challenges. For example, when dockerizing and serving the model, the API expect five (5) features and not only four (4) which is the actual number of features used by the model.
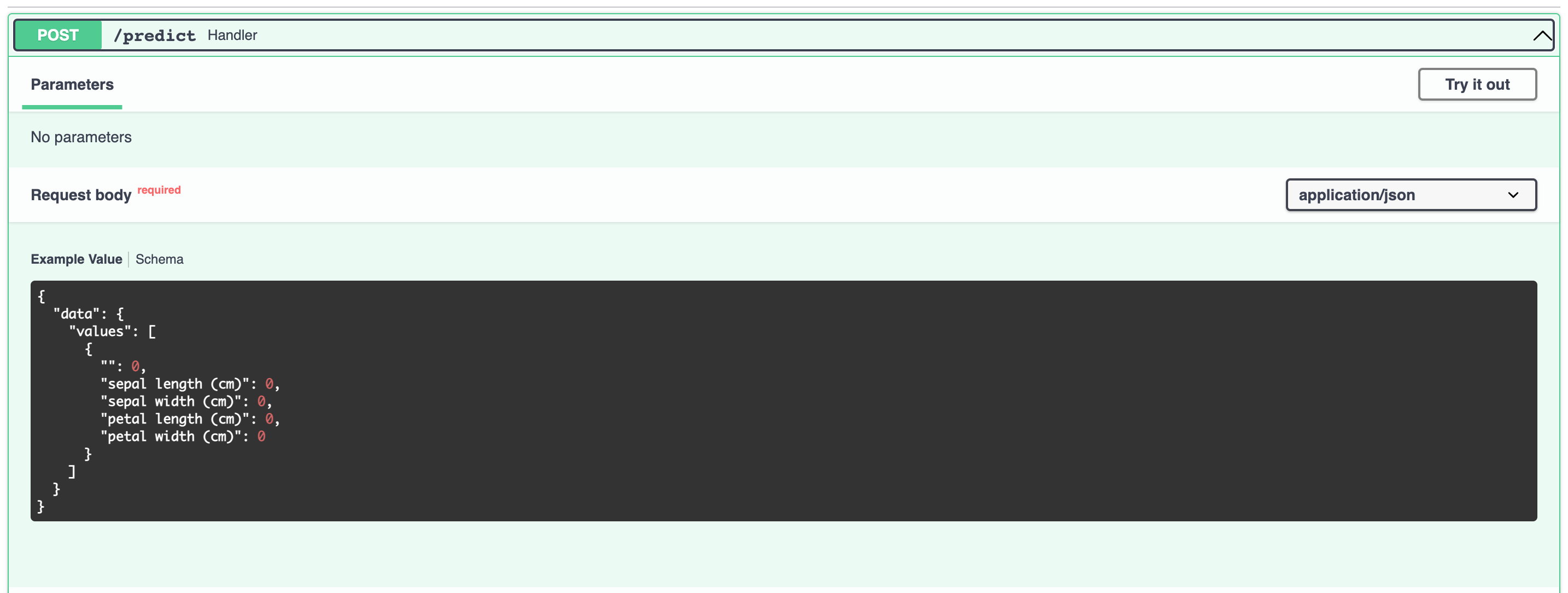
This ticket is a follow up of the discussion started on Discord here.
Going with the suggestion of @mike0sv (here) to rest the index does mitigate the issue. However, I'm not sure this behavior is ideal. Misalignment between the features used by the model and those listed in the meta data by MLEM is not desired (or at least very confusing).
NB, Mikhail's suggestion means:
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.2, shuffle=True, random_state=42
)
X_train.reset_index(drop=True).to_pickle("./data/X_train.pkl")
y_train.reset_index(drop=True).to_pickle("./data/y_train.pkl")
But in this case rest of the index is an extra step that's not needed from scikit learn's perspective for example.
Maybe there should be a arg that controls this: mlem.api.save(..., sample_store_index=False)?
Or maybe store the index separately so that it is only used for reconstruction purposes
I'd say we should just allow empty index by default or this can be configured by model type implementation. For example, sklearn dont use index, so we can allow constructing dataframe without index columns for sklearn models. If you don't want to see it as a column in openapi, just reset index before saving like I proposed earlier