datachain
 datachain copied to clipboard
datachain copied to clipboard
Research on using Iceberg instead of ClickHouse/SQLite
Current Implementation
SQLite (Local/CLI Usage)
The project uses SQLite for local operations through two main classes:
SQLiteDatabaseEngine
https://github.com/iterative/datachain/blob/ed973c82f4ab4674a5a24816eaf689498117aef6/src/datachain/data_storage/sqlite.py#L98
SQLiteWarehouse
https://github.com/iterative/datachain/blob/ed973c82f4ab4674a5a24816eaf689498117aef6/src/datachain/data_storage/sqlite.py#L406C7-L406C22
Clickhouse implementation
Currently used in the SaaS version
Why Consider Iceberg?
Current Pain Points
- Dual Implementation Overhead:
- Maintaining separate SQLite and ClickHouse implementations
- Different transaction and concurrency models
- Separate optimization strategies
- Performance
From today's call:
Iceberg Integration Discussion:
@skshetry investigated iceberg integration, concluding that direct integration is challenging due to iceberg's nature as a metastore rather than a SQL database. ClickHouse and DuckDB support read-only access, while Trino and Spark offer write capabilities, though the writing method remains unclear. He considered import/export support as a starting point, but acknowledged its limitations compared to native iceberg support. The team discussed the ideal use case of writing and reading iceberg tables directly in object storage, but recognized the current limitations of write access for many tools.
Iceberg vs. ClickHouse and Data Processing:
The discussion explored the benefits of iceberg compared to ClickHouse. @shcheklein highlighted iceberg's decoupling of persistent storage and compute. @skshetry contrasted iceberg's lakehouse approach for potentially unstructured data with ClickHouse's data warehouse approach for structured data. @dmpetrov emphasized iceberg's optimized query capabilities stemming from its data structure and storage in object storage like S3, contrasting it with less efficient methods like querying files directly from S3. @shcheklein further explained that iceberg allows the use of various databases on top of the same data, making it more flexible.
Iceberg Investigation and Next Steps:
Investigation into iceberg revealed challenges in integrating it into the data chain. It suggested import support as a potential initial step, acknowledging that this would be similar to existing Parquet support and would not leverage iceberg's native capabilities. We also discussed the various iceberg catalogs and their implications for integration. The team concluded that deeper research into the capabilities and limitations of iceberg is needed before proceeding with full integration.
Apache Iceberg is an open table format designed for huge analytic datasets. Iceberg enables various compute engines (like trino, spark ) to work with large scale datasets using a standardized table format.
Briefly, let me discuss the architecture of Iceberg. Iceberg mainly has 3 layers:
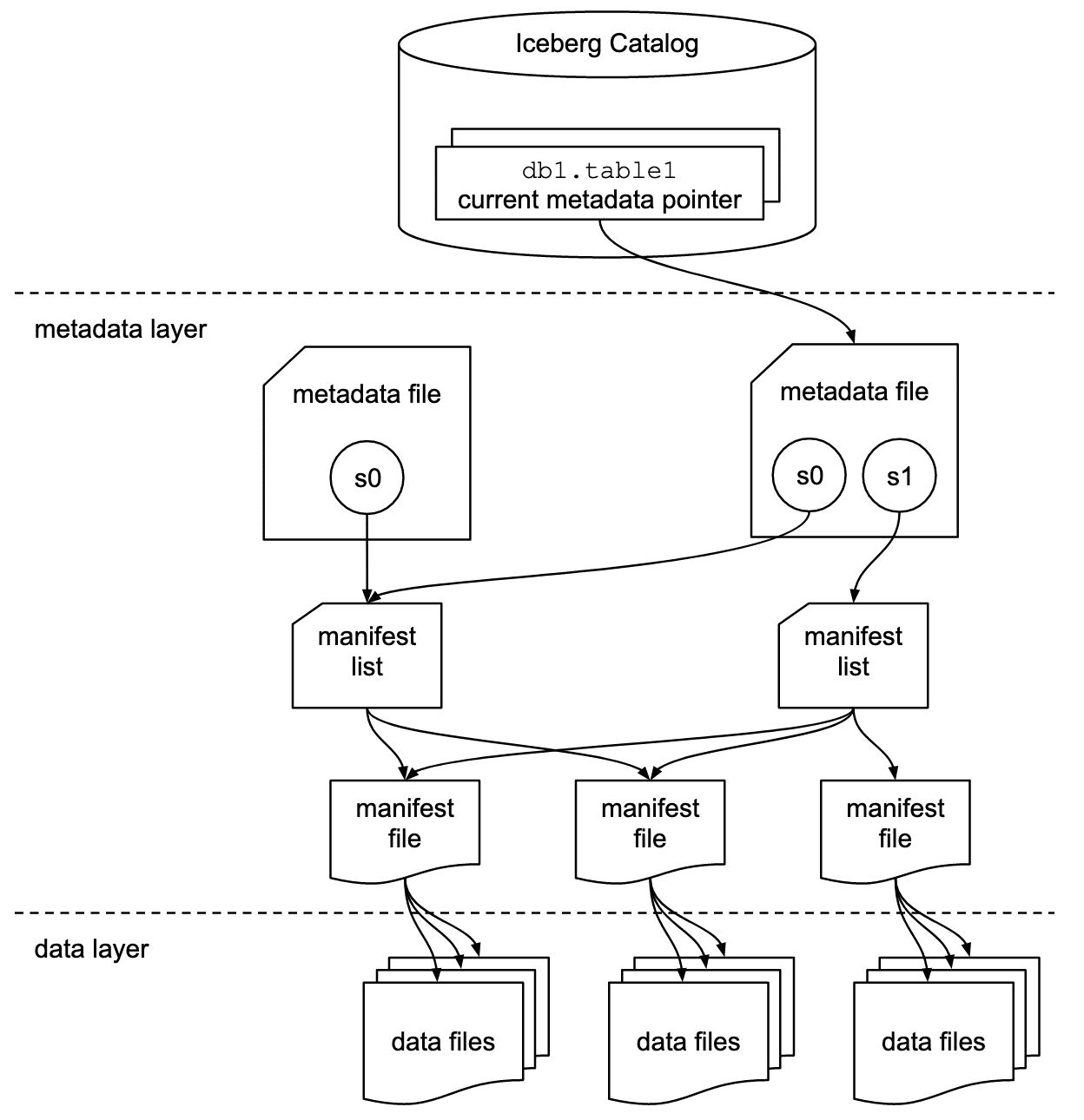
- Catalog: Iceberg uses a catalog (e.g., Hive Metastore, AWS Glue, SQL catalog, REST catalog) to track table locations and metadata changes to ensure consistency. There are multiple flavours of catalog (as said in eg.).
- Metadata Storage: Iceberg maintains table metadata (e.g., snapshots, manifests) in object storage alongside the actual data files. This metadata enables schema evolution, time travel, and efficient queries.
- Data File Storage: Iceberg stores data as columnar Parquet (or ORC/Avro) files in object storage. (
PyIceberg- the official Apache Iceberg project for Python supports multiple storages:s3,gs,hdfs, andabfs).
Additional References:
Compute Engines
More than catalog, we care more about compute engines. Let's discuss them briefly.

Spark
Spark is the most feature-rich compute engine for Iceberg operations. Supports read/write.
Clickhouse:
Clickhouse has two kinds of supports:
- Iceberg Table Engline
- and via a function
Iceberg Table Function
Both of these are read-only. Clickhouse recommends to use the latter. There is an open FR for write support: https://github.com/ClickHouse/ClickHouse/issues/49973.
Duckdb:
Duckdb has read-only support for reading/querying from iceberg tables, including from s3. No write support unfortunately, however there's an open issue: https://github.com/duckdb/duckdb-iceberg/issues/37).
See https://duckdb.org/docs/stable/extensions/iceberg.html, and https://duckdb.org/docs/stable/guides/network_cloud_storage/s3_iceberg_import.html#loading-iceberg-tables-from-s3.
The duckdb integration is an experimental project, more of a proof-of-concept. It only started supporting REST catalog last month and is not yet released. There are some things that it does not support: Hidden Partitioning and predicate pushdown for table scanning.
Also no write support. :(
Daft
Daft provides both reading and writing support for iceberg. It also supports push-down filtering.
It uses pyiceberg internally.
Looking at their code, write support does not look trivial. :(
https://github.com/Eventual-Inc/Daft/blob/fb89b2a557b867742591e6bb1327e8695c2f6423/daft/dataframe/dataframe.py#L820
Snowflake
Snowflake has a catalog support as well as query engine support (SQL).
Trino
Trino supports iceberg, and has sql support, including write operations.
https://trino.io/docs/current/connector/iceberg.html#sql-support
PyIceberg
PyIceberg is an official Apache Iceberg project, that provides a Python implementation for accessing Iceberg tables, without the need of a JVM.
https://github.com/apache/iceberg-python
This has read/write support for Iceberg. write support is recent. pyiceberg does not have all the features that Java implementation has.
See https://github.com/apache/iceberg-python/issues/736.
- PyIceberg: Current State and Roadmap
- Peformance question for to_arrow, to_pandas, to_duckdb - apache/iceberg-python
- Expose PyIceberg table as PyArrow Dataset - apache/iceberg-python
Also, has support for expressions for filtering. Supports SQL, Rest, Hive, Glue and DyanamoDB catalogs.
(TBD: need to add more information)
Polars
Polars supports reading from an Apache Iceberg table, and has push-down filtering.
- https://docs.pola.rs/api/python/dev/reference/api/polars.scan_iceberg.html
- https://github.com/pola-rs/polars/pull/10375
It also uses pyiceberg.
Ibis
Ibis has not implemented iceberg support yet. See:
- https://github.com/ibis-project/ibis/issues/7712.
Dbt
Kedro
- https://github.com/kedro-org/kedro/issues/4241
Dask
- https://github.com/apache/iceberg/issues/5800 was closed. No information on why that was closed.
Delta Lake/DataFusion
(haven't checked yet!)
Notes about my PR #937
My PR uses to_arrow_batch_reader to read in batches to reduce memory usage. (https://github.com/apache/iceberg-python/pull/786)
Although that's an import and a blocking call, so we don't have any way to do computes before it gets saved as a datachain dataset. And we don't have a way to apply filters beforehand, so unlike polars/daft, we'll save entire table.
So far, the only way to directly read from iceberg is duckdb locally, and use an engine on Studio.
There is also a way to query pyarrow.Table with duckdb, but that requires keeping an in-memory results.
Note that pyiceberg also has support for expressions, but that has to be applied by users through some ways (or, converted by us from SQL expressions to pyiceberg expressions which may not be feasible or is difficult due to our architecture).
If pyiceberg implemented Expose PyIceberg table as PyArrow Dataset, it'd be easy to mix duckdb and pyiceberg together.
(I'll add more information as I do research, so far there is not a satisfying answer).
I recommend using ClickHouse, which has one of the most complete implementations of Iceberg, including both reads and writes.
However, MergeTree tables are better optimized for high performance on huge analytic datasets.
@alexey-milovidov thank you for the news! Are there any limitations with write support - it's new feature as I understand?Do you happen to have any docs or examples you could point?
MergeTree tables are better optimized
That's expected. A proper export/import to/from Iceberg should cover many of our cases.